
作为数据科学家如何使用ChatGPT
全世界都听说过ChatGPT,但根据最近的一项新闻研究,只有2%的人会每天使用它。
作为数据科学家,我每天都会用它来处理很多事情。老实说,它将我的生产力提高了一倍。
在这篇文章中,我想解释一下我是如何使用ChatGPT的,不管你是不是数据科学家都希望能提供给你一些新的思路,让你更频繁地用它来提高你的工作效率。如果你想了解更多关于ChatGPT的相关内容,可以阅读以下这些文章:
人工智能裁员已经开始:Duolingo在使用ChatGPT-4后裁员数千人
在新研究的支持下,从ChatGPT获得深入响应的9种技巧
ChatGPT又蠢又没用?请提出正确的问题!
ChatGPT很累,可能正在计划度假(不是开玩笑)
学习与研究
我最喜欢的提示之一是“假如我5岁解释给我听”(ELI5)。它基本上让ChatGPT以非常简单的方式向我解释一个主题,往往比许多在线资源更好。
例如,如果我们运行“解释一下递归神经网络假如我5岁的话。”

这个类比非常好,真正构建了对递归神经网络的直观理解。
然后,我们可以开始深入挖掘,更具体地询问数学、工作示例等,因为作为一名数据科学家,我需要对实现 RNN 有更实际、更深入的理解。
这里的主要价值在于,我可以将ChatGPT当作私人导师,它可以用多种不同的方式向我解释问题,我可以选择最适合我的解释方式。这非常强大,可能会为你节省大量在互联网上寻找适合自己理解的解释的时间。试试看,然后告诉我你的体验!
单元测试
大多数技术专业人员不喜欢编写单元测试,这已不是什么秘密。单元测试虽然非常繁琐,但它们需要完成,因为它们确保你的代码健壮,并在部署到生产环境时增强信心。
ChatGPT可以通过提供一个测试模板来大大加快这一过程,你可以根据需要调整模板来测试代码的边界情况。
让我们考虑一个计算斐波那契数列的函数:
def fibonacci_sequence(n):
if n <= 0:
return []
elif n == 1:
return [0]
elif n == 2:
return [0, 1]
sequence = [0, 1]
for i in range(2, n):
next_fibonacci_number = sequence[-1] + sequence[-2]
sequence.append(next_fibonacci_number)
return sequence让我们将其输入到 ChatGPT 中,让它为我们的功能编写单元测试:
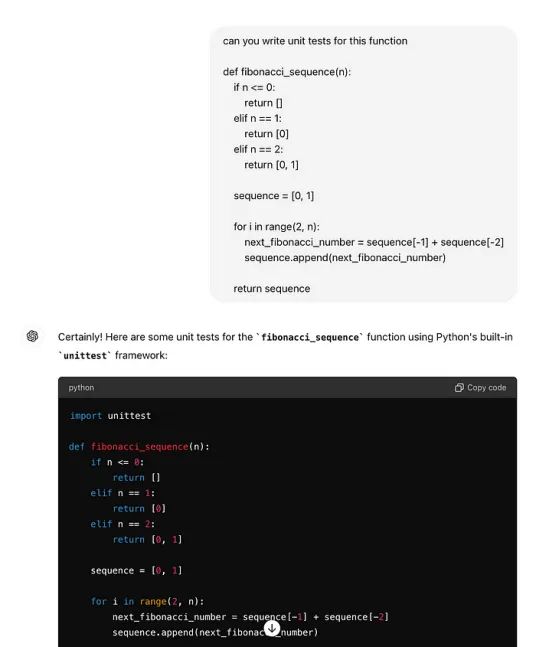
这是 ChatGPT 生成的测试的完整输出:
import unittest
def fibonacci_sequence(n):
if n <= 0:
return []
elif n == 1:
return [0]
elif n == 2:
return [0, 1]
sequence = [0, 1]
for i in range(2, n):
next_fibonacci_number = sequence[-1] + sequence[-2]
sequence.append(next_fibonacci_number)
return sequence
class TestFibonacciSequence(unittest.TestCase):
def test_negative_input(self):
self.assertEqual(fibonacci_sequence(-1), [])
def test_zero_input(self):
self.assertEqual(fibonacci_sequence(0), [])
def test_one_input(self):
self.assertEqual(fibonacci_sequence(1), [0])
def test_two_input(self):
self.assertEqual(fibonacci_sequence(2), [0, 1])
def test_five_input(self):
self.assertEqual(fibonacci_sequence(5), [0, 1, 1, 2, 3])
def test_ten_input(self):
self.assertEqual(fibonacci_sequence(10), [0, 1, 1, 2, 3, 5, 8, 13, 21, 34])
if __name__ == '__main__':
unittest.main()我的PyCharm IDE中运行后,我可以它确实有效。

我无法告诉你这为我节省了多少时间。仅仅是设置测试就需要耗费大量时间。这个方法让我可以专注于最重要的部分:找到那些可能会破坏我函数的边界情况。
创建可视化
创建图表通常非常耗时,特别是当你添加多条线和标签并试图使图表整体看起来漂亮时。我曾花费数小时敲击键盘,试图让Matplotlib满足我的需求。这并不有趣,我也不推荐这样做。
在GPT-4和GPT-4o之前,我会使用ChatGPT-3.5生成Python代码来绘制我的图表,然后在IDE中运行它。然而,现在更容易了,因为它们有一个叫做高级分析(Advanced Analytics)的功能。你只需将数据交给它,它就会为你创建图表并将相关代码输出到屏幕上。
例如,让我们使用我从Kaggle上获得的数据,这些数据包含Netflix的电影和电视节目(CC0许可)。我所做的只是将数据拖入ChatGPT,然后我可以请它为我解释这些数据:
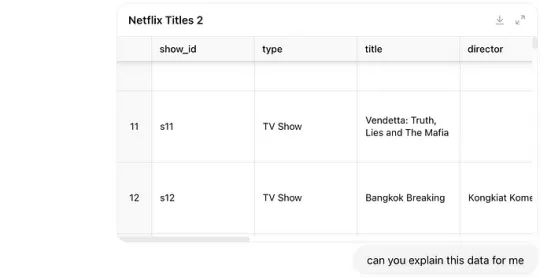

它还提供了用于加载数据的Python代码,这样我就可以确认它在幕后是如何运作的。然而,在这种情况下,它已经相当好地识别了数据,所以我不需要进一步深入挖掘。
现在我可以要求它使用这些数据绘制一些图表。假设我们想要一个根据拍摄地国家的show_id的柱状图。
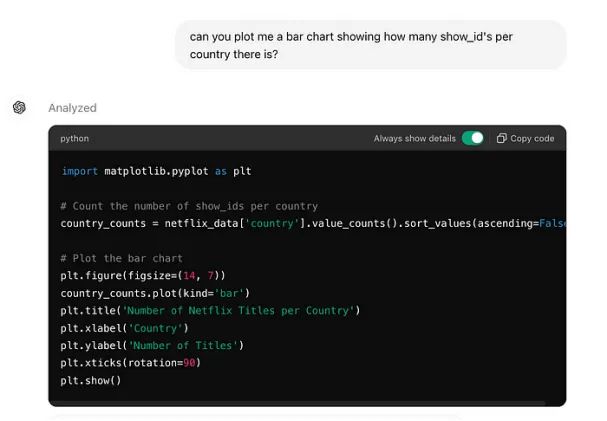
它会为我们编写代码,然后在聊天窗口生成图表!
请注意,窗口中的绘图看起来与代码在 matplotlib 中生成的绘图不同。
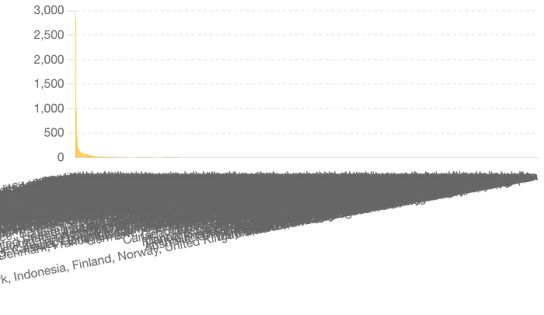
我们可以看到,它非常混乱,因为它绘制了每个国家/地区的图表。假设我们想要前 10 名,其余的则放在“其他”类别中。
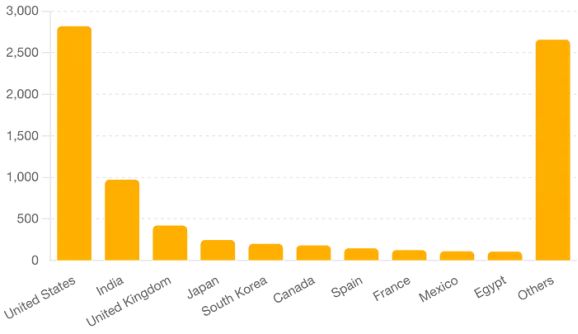
这看起来好多了,而且图表质量也很高!
这只是一个简单的例子,但它展示了ChatGPT在数据分析和可视化方面有多强大。你甚至不需要具备编程能力来做到这一点;编程能力固然有帮助,这很有帮助,但绝对不是必需的,这使得它真正为广大受众所接受。
重构代码
有时,我写代码时很懒,代码不够简洁。结果代码可能不够美观和简洁。这可能导致 bug,并且使得理解代码变得困难(对大多数开发者来说是一场噩梦)。
通常我会要求 ChatGPT 将我的代码“提升到生产标准”,这是一个我发现能够有效清理代码并使其看起来更专业、整洁的提示。
例如,考虑一下我在之前的一篇文章中写的这段代码,它使一个时间序列平稳:
# Import packages
import plotly.express as px
import pandas as pd
import os
import numpy as np
# Read in the data
data = pd.read_csv('../../Software Engineering /make-example/AirPassengers.csv')
def plotting(title, data, x, y, save_file_path, x_label, y_label):
"""General function to plot the passenger data."""
fig = px.line(data, x=data[x], y=data[y], labels={x: x_label, y: y_label})
fig.update_layout(template="simple_white", font=dict(size=18),
title_text=title, width=650,
title_x=0.5, height=400)
if not os.path.exists("../images"):
os.mkdir("../images")
fig.write_image("../images/" + str(save_file_path))
fig.show()
# Plot the airline passenger data
plotting(title='Airline Passengers', data=data, save_file_path='passengers.png', x='Month',
y='#Passengers', x_label='Date', y_label='Passengers')
# Take the difference and plot it
data["Passenger_Diff"] = data["#Passengers"].diff()
plotting(title='Airline Passengers', data=data,
save_file_path='passengers_one_difference.png', x='Month', y='Passenger_Diff',
x_label='Date', y_label='Passengers<br>Difference Transform')
# Take the log and plot it
data["Passenger_Log"] = np.log(data["#Passengers"])
plotting(title='Airline Passengers', data=data,
save_file_path='passenger_log.png', x='Month',
y='Passenger_Log', x_label='Date', y_label='Passenger<br>Log Transform')
# Take the difference and log and plot it
data["Passenger_Diff_Log"] = data["Passenger_Log"].diff()
plotting(title='Airline Passengers', data=data,
save_file_path='passenger_difference_and_log.png', x='Month',
y='Passenger_Diff_Log', x_label='Date', y_label='Passenger<br>Log and Difference')让我们将其输入到ChatGPT中,并要求它使其变得“符合生产标准”并且“更整洁”。
它生成的代码如下所示:
# Import packages
import plotly.express as px
import pandas as pd
import os
import numpy as np
# Read in the data
data = pd.read_csv('../../Software Engineering /make-example/AirPassengers.csv')
def plot_data(title, data, x, y, save_file_path, x_label, y_label):
"""
General function to plot the passenger data.
Parameters:
- title: Title of the plot
- data: DataFrame containing the data
- x: Column name for the x-axis
- y: Column name for the y-axis
- save_file_path: File path to save the image
- x_label: Label for the x-axis
- y_label: Label for the y-axis
"""
fig = px.line(data, x=x, y=y, labels={x: x_label, y: y_label})
fig.update_layout(
template="simple_white",
font=dict(size=18),
title_text=title,
width=650,
title_x=0.5,
height=400
)
output_dir = "../images"
os.makedirs(output_dir, exist_ok=True)
fig.write_image(os.path.join(output_dir, save_file_path))
fig.show()
# Plot the airline passenger data
plot_data(
title='Airline Passengers',
data=data,
x='Month',
y='#Passengers',
save_file_path='passengers.png',
x_label='Date',
y_label='Passengers'
)
# Create transformed columns and plot
transforms = [
("Passenger_Diff", data["#Passengers"].diff(), 'passengers_one_difference.png', 'Passengers<br>Difference Transform'),
("Passenger_Log", np.log(data["#Passengers"]), 'passenger_log.png', 'Passenger<br>Log Transform'),
("Passenger_Diff_Log", np.log(data["#Passengers"]).diff(), 'passenger_difference_and_log.png', 'Passenger<br>Log and Difference')
]
for col_name, transform, file_name, y_label in transforms:
data[col_name] = transform
plot_data(
title='Airline Passengers',
data=data,
x='Month',
y=col_name,
save_file_path=file_name,
x_label='Date',
y_label=y_label
)如你所见,格式符合Pep8指南,我们有文档字符串,并且它创建了一个遵循DRY原则的重复代码片段函数。总的来说,做得不错!
Python确实有一些合适的格式化工具,比如isort和black,但我发现GPT通常能更快、更好地完成工作。
总结与思考
使用 ChatGPT 提高了我在许多领域的工作效率,例如学习新事物、编写单元测试、进行分析和重构代码。我希望本文能为你提供一些在自己的工作领域的新想法。虽然我认为它不会取代我们,但它确实是一个强大的工具,你应该尝试尽可能将其集成到你的工作流程中。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Egor Howell
翻译作者:诗彤
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/how-i-use-chatgpt-as-a-data-scientist-0730fa1e21c2





