
如何在Pandas里写SQL查询语句?
15年前,软件开发人员只需要拥有几项技能就可以胜任95%的岗位。这些技能包括:
- 面向对象的编程语言
- 脚本语言
- JavaScript
- SQL
想要快速了解数据、得出初步结论,也就是我们常说的探索性数据分析(exploratory analysis),并以这个结论生成报告或编写程序,SQL是首选工具。
如今,数据以多种形式出现,不再仅仅是“关系数据库”这么简单,你还可能遇到CSV文件、纯文本、Parquet、HDF5等等。这也是为什么我们Pandas工具包可以大大方便我们的工作。
如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
如何用Pandas 三步清洗数据?
一文上手用Pandas给数据加标签
SQL和Pandas同时掉到河里,你先救谁?
什么是Pandas工具包?
Pandas是Python数据分析核心工具包,基于NumPy构建,由Anaconda支持,尤其适合处理结构化(表格)数据。更多相关信息,请参见:
http://pandas.pydata.org/pandas-docs/stable/index.html。
Pandas有什么用?
所有用SQL写的查询语句,都可以通过Pandas实现。当然,pandas的用途远不止这些!
如何用Pandas重写SQL查询语句?
习惯用SQL格式写查询语句的人,一开始可能并不习惯用Pandas的格式来写。
SQL是一种声明式编程语言
(Declarative programming language):
https://en.wikipedia.org/wiki/List_of_programming_languages_by_type#Declarative_languages
使用SQL,几乎可以像日常英文表达一样“声明”你想要获得的内容。
但Pandas的语法与SQL完全不同。在Pandas中,我们需要对数据集进行一系列操作,并将其链接起来,从而变换和重塑数据,来得到我们想要的结果。
我们会需要一本 phrasebook(常用语手册)!
剖析SQL查询语句
SQL查询语句由一些重要的关键字组成,可以在这些关键字之间添加要查看的数据的详细信息。大致框架如下:
SELECT… FROM… WHERE…GROUP BY… HAVING…ORDER BY…LIMIT… OFFSET…
当然,还有一些其他的关键字,但上面这些是最常用的。那我们要如何将这些命令在Pandas实现呢?
首先,我们需要将数据加载到Pandas中,因为它们尚未存储在数据库中。方法如下:
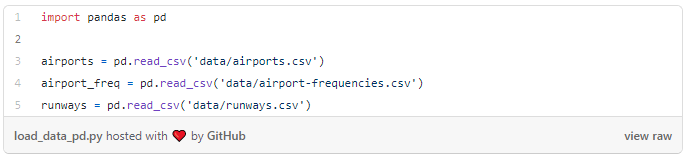
数据来源:http://ourairports.com/data/
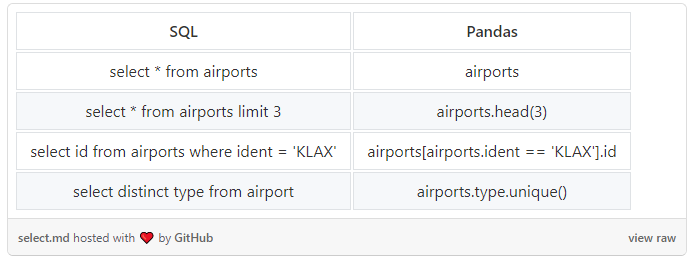
SELECT, WHERE, DISTINCT, LIMIT
这是一些SELECT语句。我们使用LIMIT缩短结果,使用WHERE过滤结果,使用DISTINCT删除重复的结果。
SELECT多个条件
我们通过符号“&”将多个条件组合在一起。如果我们只想要显示表格中特定的列,可以通过添加另外一对方括号来表示。

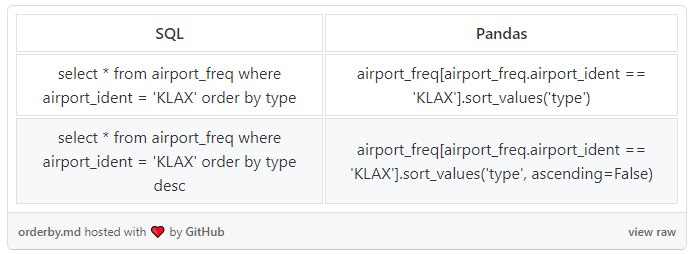
ORDER BY
默认情况下,Pandas会使用升序排序。如果要使用降序排序,要写明ascending = False。
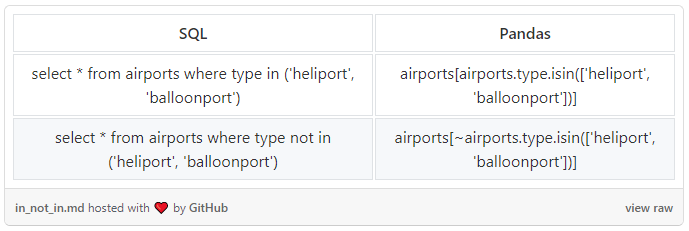
IN…NOT IN
我们知道了如何对值进行筛选,但如何对一个列表进行筛选呢,就像 SQL 的 IN 语句那样?在 Pandas 中,.isin() 操作符的工作方式与 SQL 的 IN 相同。如果要变为否定条件,请使用 “〜”。
GROUP BY, COUNT, ORDER BY
分组操作很简单:可以使用 .groupby() 运算符。在SQL和Pandas中,COUNT的语义之间存在细微的差异。在Pandas中,.count会返回non-null / NaN值的数量。要获得与SQL的COUNT相同的结果,需要使用 .size()。
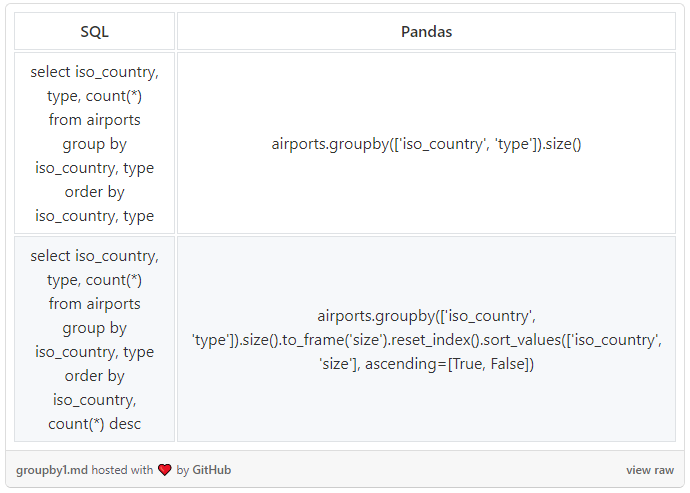
下面,我们对多个字段进行分组。Pandas 默认情况下,会对列表中相同字段上的内容进行排序,因此,在第一个示例中不需要 .sort_values()。但如果我们想使用不同的字段进行排序,或者想使用 DESC 而不是 ASC,就像第二个例子那样,那我们就必须明确使用 .sort_values():
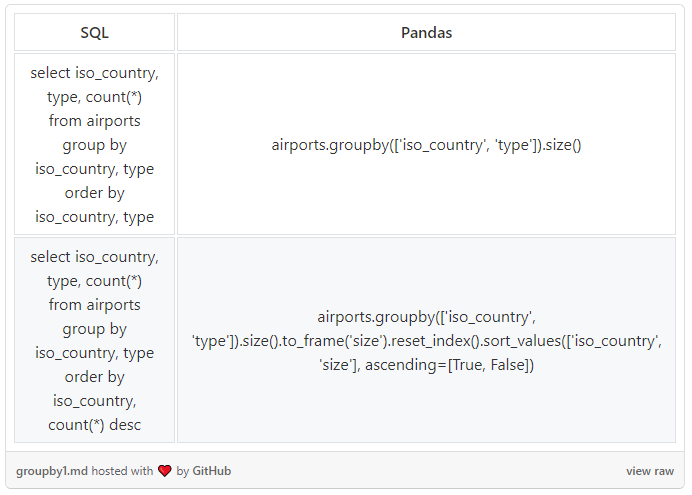
其中使用 .to_frame() 和 reset_index() 是为什么呢?因为我们想通过计算对字段(大小)进行排序,所以这个字段需要成为 DataFrame 的一部分。在 Pandas 中进行分组之后,我们得到了一个叫 GroupByObject 的新类型。所以,我们需要使用 .to_frame() 把它转换回 DataFrame 类型。再使用 .reset_index(),重新进行数据帧的行编号。
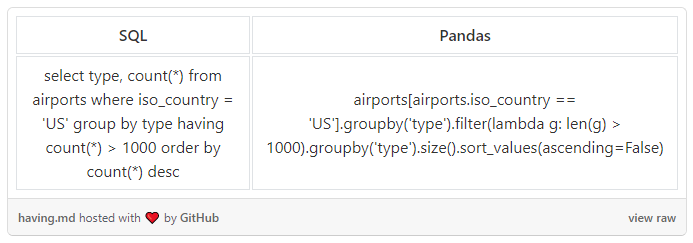
HAVING
在 SQL 中,你可以使用 HAVING 条件语句,对分组数据进行追加过滤。在 Pandas 中,可以使用 .filter() ,并给它一个 Python 函数(或 lambda 函数),如果结果中包含这个组,该函数将返回 True。
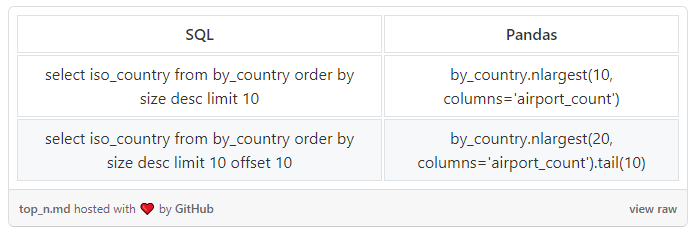
前 N 个记录
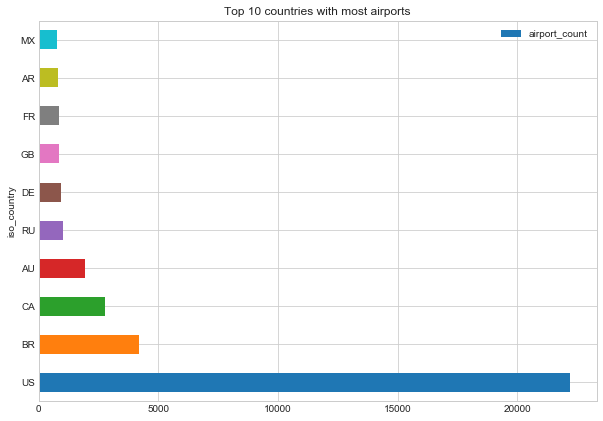
假设我们做了一些初步查询,现在有一个名为 by_country 的 dataframe,它包含每个国家的机场数量:

在接下来的第一个示例中,我们通过 airport_count 来进行排序,并且只选择机场数量最多的 10 个国家。第二个例子比较复杂,我们想要“前 10 名之后的另外 10 名,即 11 到 20 名”:
聚合函数 (MIN, MAX, MEAN)
现在给定一组 dataframe,即一组跑道数据:
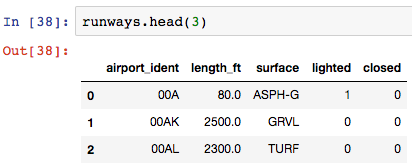
计算跑道长度的最小值,最大值,平均值和中值:
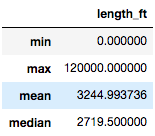
你会注意到,使用 SQL 查询时,每个统计结果都是一列数据。但是使用 Pandas 的聚集方法,每个统计结果都是一行数据:
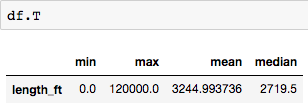
不用担心 — 只需将 dataframe 通过 .T 进行转换就可以得到成列的数据:
JOIN
使用 .merge() 来连接 Pandas 的 dataframes。你需要给出要连接哪些列(left_on 和 right_on)和连接类型:inner(默认),left(对应 SQL 中的 LEFT OUTER),right(RIGHT OUTER),或 OUTER(FULL OUTER)。

UNION ALL和UNION
使用 pd.concat() 替代 UNION ALL 来合并两个 dataframes:
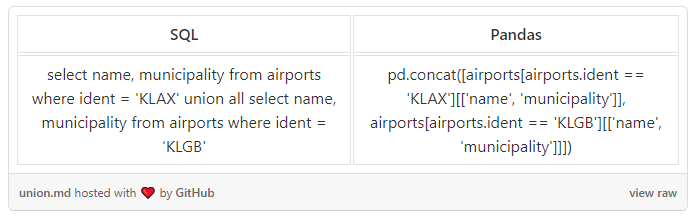
合并过程中,如果想要删除重复数据(等价于 UNION),还需要添加 .drop_duplicates()。
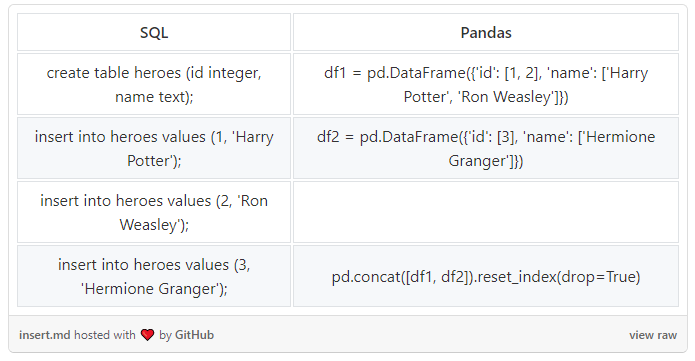
INSERT
到目前为止,我们一直在讲筛选,但是在探索性分析过程中,你可能也需要修改。如果你想添加一些遗漏的记录该怎么办?
Pandas 里面没有类似 INSERT 语句的方法。相反,你只能创建一个包含新记录的新 dataframe,然后合并两个 dataframe:
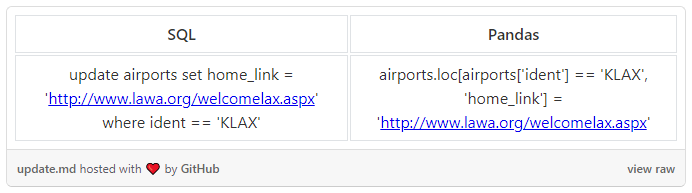
UPDATE
现在我们需要修改原始 dataframe 中的一些错误数据:
DELETE
从 Pandas dataframe 中,“删除”数据的最简单(也是最易读的)方法,是从 dataframe中提取你想保留的行的子集。或者,你可以通过使用行索引来删除,使用 .drop() 方法删除这些行:

不可变性 (Immutability)
我需要提一件重要的事情 — 不可变性。默认情况下,大部分用于 Pandas dataframe 的操作符都会返回一个新对象。有些操作符可以接收 inplace=True 参数,这样,你就可以继续使用原始的 dataframe。例如,以下是一个就地重置索引的方法:

然而,上面的 UPDATE 示例中的 .loc 操作符,仅定位了需要更新记录的索引,并且这些值会就地更改。此外,如果你更新了一列中所有的值:

或者添加一个计算得出的新列:

这些都会就地发生变化。
其他
Pandas 的好处在于它不仅仅是一个查询引擎。你还能用你的数据做更多事情,例如:
- 以多种格式输出:
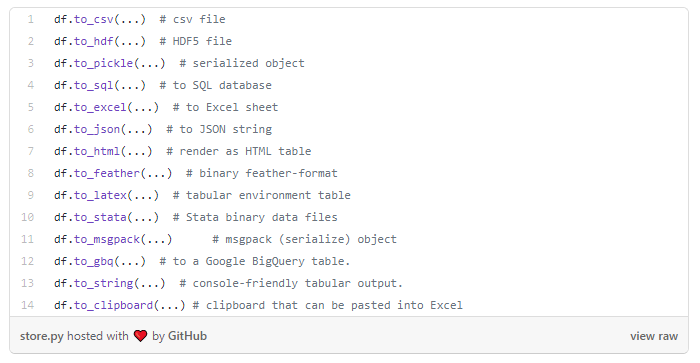
- 绘制图表:
可以生成一些非常实用美观的图表!
- 共享:
共享 Pandas 查询结果、绘图和相关内容的最佳媒介是 Jupyter notebooks(http://jupyter.org/)。事实上,有些人(比如杰克·范德普拉斯 (Jake Vanderplas))会把整本书都发布在 Jupyter notebooks 上:
https://github.com/jakevdp/PythonDataScienceHandbook
很简单就可以创建一个新的笔记本:

之后:
- 打开 localhost:8888
- 点击“新建”,并给笔记本起个名字
- 查询并显示数据
- 创建一个 GitHub 仓库,并把你的笔记本添加到仓库中(后缀为 .ipynb 的文件)
GitHub 有一个很棒的内置查看器,可以用 Markdown 的格式显示 Jupyter notebooks 的内容。
现在,开始你的 Pandas 之旅吧!
我希望你现在可以确信,Pandas 库可以像你的老朋友 SQL 一样帮你进行探索性数据分析,而且在某些情况下,甚至会做得更好。是时候开始自己动手在 Pandas 里查询数据了!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Irina Truong
翻译作者:Haoran Qiu
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/jbennetcodes/how-to-rewrite-your-sql-queries-in-pandas-and-more-149d341fc53e





