
Python中的营销组合建模简介——哪些广告支出真正推动了你的销售?
广告入门
为了维持一家企业的运营,在广告上花钱至关重要——无论该公司是初创的小公司还是创立已久的大公司,都是如此,广告在公司运营中的支出费用都是巨大:
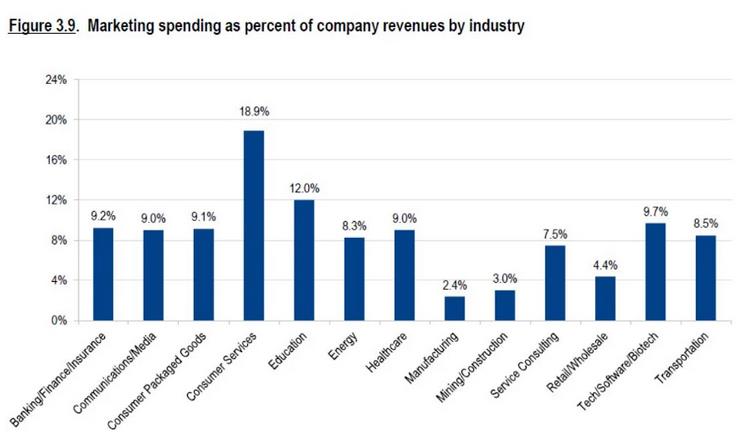
资料来源:
https://www.webstrategiesinc.com/blog/how-much-budget-for-online-marketing-in-2014,(文章于2020年更新)
广告费用如此之高,使得企业经营者有必要明智地花费每一笔广告费用。然而,这说起来容易做起来难,或者正如美国零售业巨头约翰·瓦纳梅克(JohnWanamaker)或英国实业家勒沃胡姆勋爵(LordLeverhulme)大约一百年前所说:
“我花在广告上的钱有一半被浪费了;问题是我不知道是哪一半。”
你可能会认为现在这个问题已经不那么严重了,但奇怪的是,它仍然存在。幸运的是,我们能够借助大量数据和功能强大的计算机,通过高级分析(如归因建模或营销组合建模)来改变这种状况。在本文中,我们将重点讨论后者。如果你想了解更多关于商业分析的相关内容,可以阅读以下这些文章:
Retail Analysis的力量——商业分析在零售业的应用
Tableau数据可视化,学完就掌握商业分析必备技能了!
新兴报表工具FineReport——商业分析师需要知道的三种报表
数据大浪潮你跟上了吗:如何转行Business Analyst 商业分析师?
示例数据集和简单建模
想象一下,现在你负责某家老牌公司的营销预算。为了增加销售额,您可以在三个不同的广告渠道中播放广告:
- 电视
- 收音机和
- web横幅。
数据
在每个星期,你决定在每个频道上花一些钱,或者不花。此外,您还可以观察每周的销售额。200周后,收集的数据可能如下所示:
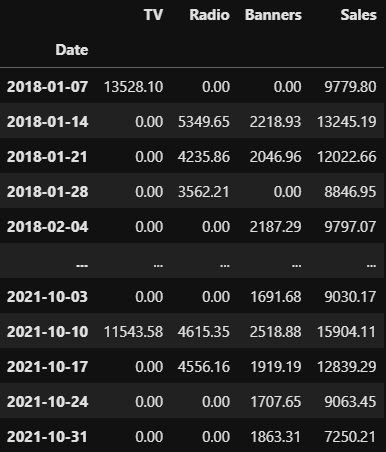
表中的数字就是是您选择广告渠道的花费和销售额,从现在起我将使用欧元。您可以在此处获取上述文件(https://github.com/Garve/datasets/blob/4576d323bf2b66c906d5130d686245ad205505cf/mmm.csv)。
粗略看一下上图的数据,我们可以看到很多周没有电视广告(71%),还有一些周没有广播广告(54%)。可以发现,只有约24%的周没有使用网络横幅,所以网络横幅是最常用的渠道。
然而,当我们在电视上花钱时,他们往往高于广播支出,而广播支出又高于网络横幅广告支出。此外,销售一直都在持续着。
现在,在开始建模之前,让我们首先明确目标。
目标
最后,我们希望能够回答以下问题:
截至2021年10月10日(见上表)的一周内,15904.11欧元的销售额中有多少是由电视广告产生的?又有多少是通过广播和网络横幅拉动的?基线是多少,即如果没有任何广告,我们会有多少销售额?
如果我们的模型能够做到这一点,我们还可以使用它来计算ROI和优化支出,这是公司最终想要的。考虑到这一目标,我们可以限制自己使用加法模型,即形式模型
Sales = f(TV) + g(Radio) + h(Banners) + Base
因为他们让我们很容易分解销售。销售额只是一些只依赖于电视支出的功能、另一个只依赖于广播支出的功能、另一个只依赖于网页横幅支出的功能和(恒定)基线的总和。
诸如随机森林、梯度增强或(简单的前馈)神经网络之类的模型不适合这里,因为我们无法从它们中得到这样的分解。
注意:当然,有一些Shapley价值观是我们想要的,但根据Shapley价值观的贡献通常是负面的,这是营销人员不想听到的不合理的东西。
另一个可选的加性模型是我们所熟知的-线性回归,它是加性模型的最简单代表!
您可以在此处找到后续文章,其中包含更详细的模型:
https://towardsdatascience.com/an-upgraded-marketing-mix-modeling-in-python-5ebb3bddc1b6
线性回归建模
将上述数据存储在变量数据中后,我们将执行以下操作:
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import cross_val_score, TimeSeriesSplit
import pandas as pddata = pd.read_csv(
'https://raw.githubusercontent.com/Garve/datasets/4576d323bf2b66c906d5130d686245ad205505cf/mmm.csv',
parse_dates=['Date'],
index_col='Date'
)X = data.drop(columns=['Sales'])
y = data['Sales']lr = LinearRegression()
print(cross_val_score(lr, X, y, cv=TimeSeriesSplit()))# Output: [0.69594303 0.69302285 0.66850729 0.78807363 0.73512387]注意:我们这里不使用标准的k倍交叉验证,因为我们处理的是时间序列数据。TimeSeriesSplit是一种更合理的做法,您可以在这里阅读更多有关它的信息。
嗯,这看起来已经很合理了,尽管它可能会更好。但这种模式让我们可以按照自己的意愿分解销售额,因为公式很简单
Sales = 0.36 * TV + 0.49 * Radio + 1.23 * Banners + 6678.40我们可以通过简单的代码获取计算系数和截距。
lr.fit(X, y) # refit the model with the complete dataset
print('Coefficients:', lr.coef_)
print('Intercept:', lr.intercept_)# Output:
# Coefficients: [0.35968382 0.48833246 1.2159193 ]
# Intercept: 6678.396933606161销售明细表
为了分析各渠道对销售额的贡献值,让我们考虑其中一周的数据:

让我们插入数字,看看得到了什么:
print(lr.predict(([[11543.58, 4615.35, 2518.88]])))
# Output: [16147.01594158]这并不完全是上表中15904.11的真实答案,但让我们暂时坚持下去。我们现在可以看到,电视(未经调整)对营业额的贡献是:
coef_TV * spendings_TV = 0.36 * 11543.58 = 4155.69,现在,贡献总计为模型预测16147.0159,这不是15904.11的真实目标,所以让我们将贡献和基线乘以校正系数correction_factor = 15904.11 / 16147.0159 ≈ 0.985,一切正常。我们得到
contribution_TV = correction_factor * 4155.69 = 4089.57我们还可以得到
contribution_radio = 2219.92 and
contribution_banners = 3016.68
base = 6577.93将所有内容相加,得到我们想要的观察标签:
4089.57 + 2219.93 + 3016.68 + 6577.93 = 15904.11我们可以为所有观察结果生成一个很好的贡献图,如下所示:
weights = pd.Series(
lr.coef_,
index=X.columns
)
base = lr.intercept_
unadj_contributions = X.mul(weights).assign(Base=base)
adj_contributions = (unadj_contributions
.div(unadj_contributions.sum(axis=1), axis=0)
.mul(y, axis=0)
) # contains all contributions for each day
ax = (adj_contributions[['Base', 'Banners', 'Radio', 'TV']]
.plot.area(
figsize=(16, 10),
linewidth=1,
title='Predicted Sales and Breakdown',
ylabel='Sales',
xlabel='Date')
)
handles, labels = ax.get_legend_handles_labels()
ax.legend(
handles[::-1], labels[::-1],
title='Channels', loc="center left",
bbox_to_anchor=(1.01, 0.5)
)输出结果是:
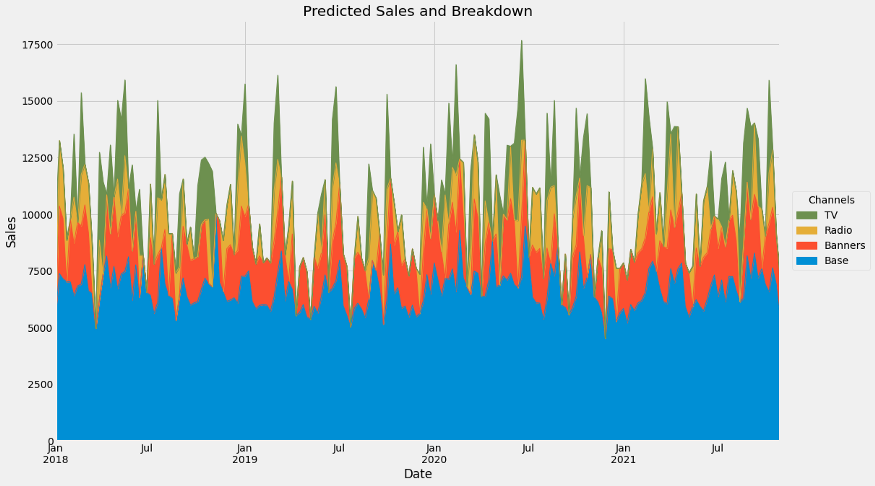
我们可以看到(或计算)基线是每天约6500个销售额,横幅和广播在活动时平均贡献约2500,电视在活动时约3500个。很好!
计算投资回报率(ROI)
我们现在可以确定哪个渠道在ROI方面是最好的,ROI是衡量效率的数字。公式很简单:
channel_ROI = Sales from the channel / channel spendings有了上面的代码片段,我们已经拥有了计算所需的所有数据。您可以按如下方式计算电视ROI:
sales_from_tv = adj_contributions['TV'].sum()
spendings_on_tv = data['TV'].sum()
tv_roi = sales_from_tv / spendings_on_tv
# tv_roi is around 0.36就这么简单。ROI小于1意味着渠道表现不佳。对于电视ROI,我们可以说:
我们在电视上每花1欧元,就可以得到36欧分的回报。
如果我们想让公司生存下去,我们不想太频繁地进行这种交易。另一方面,横幅的ROI为1.21,这要好得多,似乎该频道在我们考虑的时间段内运行得很好。
这种简单方法的问题
虽然上述方法似乎合理,但我们必须解决某些缺点:
- 性能可能会更好。有时,我们对糟糕的性能无能为力,因为它在很大程度上取决于数据,但无论如何,我们应该尽最大努力。
- 更严重的是:模型本身肯定不能反映现实。根据线性公式,我们可以通过在广告上花费越来越多的钱来推动销售额达到我们想要的最高水平。由于横幅的系数很高,为1.23欧元,我们在该渠道中每花费1欧元,就会产生1.23欧元的额外销售额。如果在此渠道无限重复地投放广告,客户会讨厌这个行为!
- 优化也变得琐碎和不切实际。为了最大限度地提高销售额,我们现在将把所有的钱都投入到网络横幅渠道中,因为它的系数最高。我们将完全放弃电视和广播广告,如果公司想在人们中保持知名度,这可能不是正确的做法。
我们将在后续文章中解决所有这些问题,敬请期待!
摘要和展望
我们已经看到,公司将其收入的很大一部分用于广告,以鼓励客户购买其产品。然而,有效利用营销预算并非易事,无论是一百年前还是今天。要想弄清楚某个电视广告支出对销售额的影响有多大,以及广告支出是否值得,以及如何为下一次进行优化,并不那么容易。
为了解决这个问题,我们创建了一个小的营销组合模型,允许我们将观察到的销售分成几个部分:电视、广播、横幅和基本份额。这些通道贡献使我们能够计算ROI,从而查看每个通道的性能。
然而,这个模型太简单,无法捕捉现实,这会产生很多问题。但我们将学习如何通过使模型稍微复杂一些,但仍然可以解释来规避这些问题。
您可以在此处找到后续文章:
Python中升级的营销组合建模(https://towardsdatascience.com/an-upgraded-marketing-mix-modeling-in-python-5ebb3bddc1b6)
我希望你今天学到了一些新的、有趣的和有用的东西。感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Dr. Robert Kübler
翻译作者:Chuang Zhang
美工编辑:过儿
校对审稿:Miya
原文链接:https://towardsdatascience.com/introduction-to-marketing-mix-modeling-in-python-d0dd81f4e794





