
用Python实现K-近邻分类
“告诉我你的朋友是谁,我会告诉你你是谁?”
K-近邻分类的概念很难描述。这是一句古老的谚语,可以在多种语言和多种文化中找到。圣经中也用其他字词提到:“与智者同行的人将是智者,但愚昧的同伴将受到伤害”(箴言13:20)
这意味着k近邻分类器的概念是我们日常生活和判断的一部分:想象一下你遇到的一群人,他们都很年轻,时尚且富有运动精神。他们谈论与他们不在一起的朋友Ben。那么,您对Ben的想象是什么?是的,你认为他是年轻的,时尚的,热爱运动的。
如果Ben居住在一个支持保守派的社区,并且居民平均收入超过每年20万美元,他的两个邻居每年的收入甚至超过30万美元, 你会如何看待Ben?最有可能的是,你不认为他是弱者,还可能怀疑他也是保守主义者?
近邻分类的原理在于找到预定义数量,即“ k”个训练样本,该样本距离新样本最近,必须对其进行分类。新样本的标签将从这些邻居中定义。k近邻居分类具有固定的用户定义常数,用于确定邻居数量。还有基于半径的邻居学习算法,该算法具有基于点的局部密度而变化的邻居数量,所有样本都位于固定半径内。距离通常可以是任何度量标准:标准欧几里德距离是最常见的选择。基于邻居的方法被称为非通用机器学习方法,因为它们只是“记住”其所有训练数据。我们可以通过未知样本最近邻居的多数投票来计算分类。
现在让我们加入数学计算:
k近邻分类(k-NN)直接对学习的样本起作用,而不是和其他分类方法一样创建规则。
近邻算法:
给定一组类别{c1,c2,…cn}也称为类,例如 {“男性”,“女性”}。还有一个学习集LSLS,它由带标签的实例组成。
分类的任务在于将类别或类分配给任意实例。如果实例oo是LSLS的元素,则将使用实例的标签。
现在,我们来看一下LSLS中没有oo的情况:
将oo与LSLS的所有实例进行比较。用距离度量进行比较。我们确定oo的kk个最接近的邻居,即距离最小的物品。kk是用户定义的常数和一个正整数,通常很小。
LSLS最常见的类将分配给实例oo。如果k = 1,则仅将对象分配给该单个最近邻居的类。
k近邻分类的算法是所有机器学习算法中最简单的算法之一。k-NN是一种基于实例的学习或惰性学习,其中,当我们进行实际分类时,该函数仅在本地进行近似,并且所有计算都将执行。
在实际开始编写一个近邻分类之前,我们需要考虑数据,即学习集。我们将使用sklearn模块的数据集提供的“ iris”(鸢尾花)数据集。
数据集包含来自三种鸢尾的50种样品。这三种鸢尾是:
· 鸢尾setosa
· 维吉尼亚鸢尾
· 杂色鸢尾鸢尾花
从每个样品中测量出四个特征:萼片和花瓣的长度和宽度,以厘米为单位。

这是预期的输出:

我们从以上集合创建一个学习集。我们使用np.random的置换来随机分割数据。

输出:

以下代码仅是可视化我们的学习集数据所必需的。我们的数据包含每个鸢尾的四个值,因此我们将第三和第四值相加,将数据减少为三个值。这样,我们就能在3维空间中描绘数据:
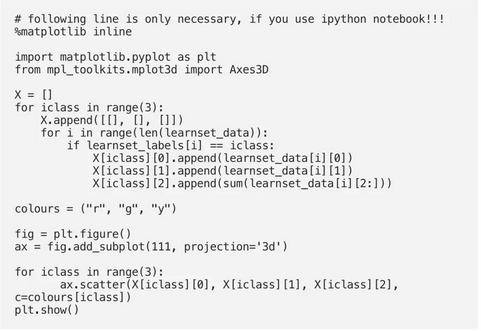
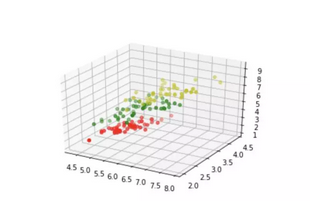
确定邻居
为了确定两个实例之间的相似性,我们需要一个距离函数。在我们的示例中,欧几里德距离是理想的:

函数“ get_neighbors”返回包含“ k”个邻居的列表,这些邻居最接近实例“ test_instance”:

我们将用鸢尾样本测试该功能:

输出:
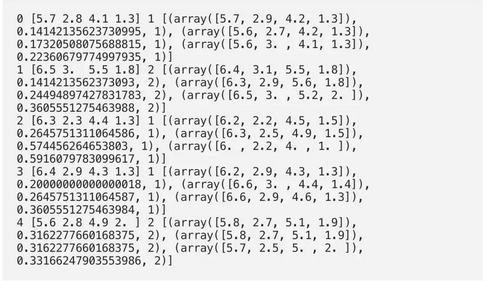
投票获得单一结果
我们现在将编写一个表决功能。此功能使用集合中的“ Counter”类对实例列表中的类进行计数。当然,此实例列表将是邻居。函数vote返回最常见的类:

我们将在我们的训练样本中测试“投票”:


我们可以看到,除了具有索引8的项目以外,这些预测与标记的结果相对应。
“ vote_prob”是类似于“ vote”的函数,但返回类别名称和该类别的概率:



总结
在本教程中,您发现了如何使用Python从零开始实现k-Nearest Neighbors算法。
具体来说,您了解到:
如何逐步编码k最近邻算法。
如何在真实数据集上评估k最近邻。
如何使用k最近邻对新数据进行预测。
作者:Yassine Hamdaoui
翻译:Xin Zhang





