
一小时学会SVM 支持向量机
在机器学习中,支持向量机(SVM,Support-Vector Machines)是具有学习算法的监督学习模型,用于分析数据以进行分类和回归分析。今天我们就一起来学习一个关于SVM的机器学习算法。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
5种机器学习的分类器算法
Python机器学习库:pycarets新增时间序列模块
机器学习VS深度学习:有什么区别?
如何回答ML机器学习的面试问题?
本文的主要内容有:
- 机器学习关于分类器的方法
- SVM工作器的原理
- 怎样用好SVM的方法做分类器
- SVM的优缺点
首先,我们来看一下机器学习里面的这种基本的方法:Supervised Machine Learning。机器学习其实是一种人工智能的方法,通过一种算法,这种算法能够把数据里的潜在规律学习出来,这样就会是一个模型,可以拿过去的数据学习这个模型,拿它预估将来的一些情况。
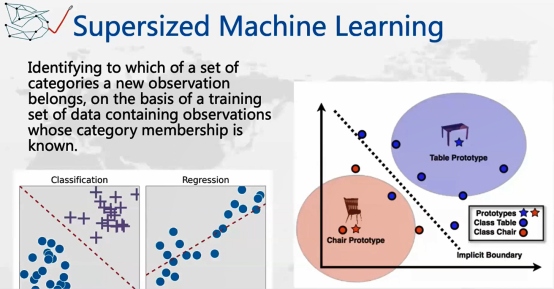
Supervised Machine Learning和Unsupervised Machine Learning最大的区别是:SVM无论是历史数据还是提取的数据链,都是被标记好的,比如说我们有一个回归模型,想预估一个货品的需求量,在这里,需求量应该会是一个数值。比如一个商店有100种商品,每种商品在三年之内每个星期的销售量,这个我们就认为是过去的需求历史数据,就可以做一个模型去预估在未来几周会有多少需求,这时候会发现在需求这方面是有数据的。
Unsupervised Machine Learning,比如给定一组用户的基本数据,需要整理成一个一个的分组,但我们不知道它们的具体分组是多少。今天我们主要想讨论的是Supervised Machine Learning,它们是被标记好的,我们知道哪些是好的,哪些是存在欺诈的,把欺诈和非欺诈做成两个标记,这种也是所谓的Supervised,因为是知道1和0的。
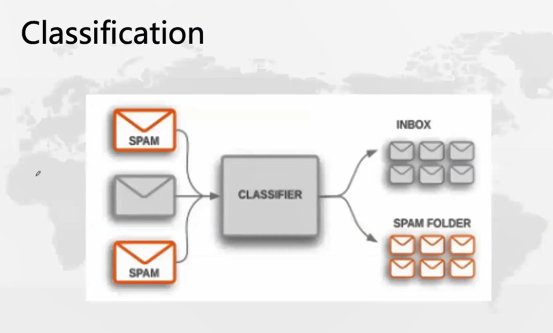
那么Classification是什么呢?我们可以用垃圾邮件的例子来讲,分类器实际上就是一个机器学习算法,和今天我们讲的SVM一样,这样的一个机器学习算法实际上就是去学习过去的历史,比如垃圾和钓鱼邮件常用哪些词,正常的邮件会出现哪些词,或者标题里最常出现的100个词,通过学习这些东西来实现。然后,每个邮件都会标记好是垃圾邮件还是正常邮件。通过SVM这样的算法,把这两种邮件分类的模型方法学习出来,学习出来的这个模型就是分类器。
将来,如果有一封新的邮件进来,我们也不知道他是好是坏,这个时候让邮件先通过学习好的分类器算法来实现分类,就是机器学习里分类器的工作方法。

接下来,让我们来看看评估(Evaluation),为什么我们会对评估感兴趣呢?我们学习出来的这个模型是否有效,或者如果有几种不同的算法怎么去评判他们呢?
一般来说,我们会用一种混淆矩阵(Confusion Matrix)去评估,这个方法是怎么来的呢?它是一个2×2的矩阵,Positive就是1,Negative就是0。我们还是用邮件为例,如果说这个邮件是欺诈的话,那就是在第一列,如果不是,就是在第二列,同样,分类器的模型也会告诉我们一个结果。
比如这边的结果是真正的结果也就是Y,另一边的结果是预估出来的,这两个结果可能会出现不一样的情况,任何一个模型都可能会算错,那么这个2×2的矩阵会出现四种情况,比如一个邮件进来,我们有可能给它算为好的邮件,也可能算到坏的邮件里,如果两个刚好一致,就叫TP(True Positive),有True Positive,就有False Positive——我们认为通过模型认为是Positive,但其实是Negative,这也是我们不想看到的结果。
另外一种情况,即模型认为该邮件不是垃圾邮件,但其实该邮件确实是垃圾邮件,我们也不希望这种情况出现,我们称之为False Negative。如果该邮件不是垃圾邮件,模型判定其不是垃圾邮件,我们称之为True Negative,这是我们想要看到的结果。这就是四大情况a,b,c,d,我们分别需要计算其指标(Metrics),其中包括:第一,准确度(Accuracy),即(a+d)/(a+b+c+d);还有灵敏度(Sensitivity)——a/(a+c)以及明确性(Specificity)d/(b+d)。
在本题中,a=3,b=12,c=7,d=978,代入公式计算即可。
有一些算法的结果是百分比的形式,需要你自行判断。例如,我前边提到过的信用卡欺诈,你可以根据大环境及经济形势的变化,判断会出现很多欺诈行为。
如果原来的阀门值是50%,而算法运行结果大于50%,则可以判定为是金融欺诈行为;如果经济情况不太好,该阀门值可能为40%。在算法输出0或1之前,会有一个阀门值,我们需要通过策略不断调整输出结果。
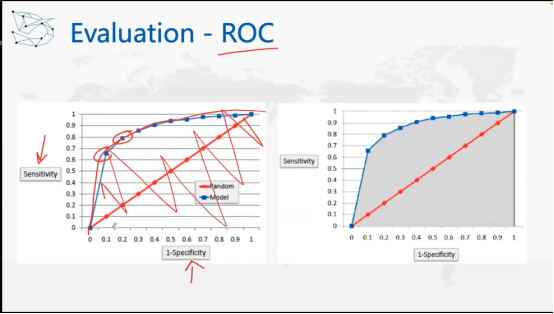
这时,算法又和策略有一定的关系,为了评估不同策略下算法的好坏,我们可以用ROC曲线的方法,即生成一个曲线:例如,Y轴为灵敏度(Sensitivity),X轴为明确性(Specificity),两者之间存在一定的权衡关系。如果你想知道该算法在不同的策略下的表现如何(即图中曲线),曲线下的面积(AUC)可以用来衡量不同值的表现,即总体表现。
前面我们讲到了分类器的运作和评估方式。下面,我们将讨论支持向量机SVM(Support-vector machines/networks),即分类器的算法。

支持向量机,也叫支持向量网络,是监督学习模型算法的一种。维基百科中也提了几个主要的算法贡献者,Vapnik以及他的同事Boser等等。
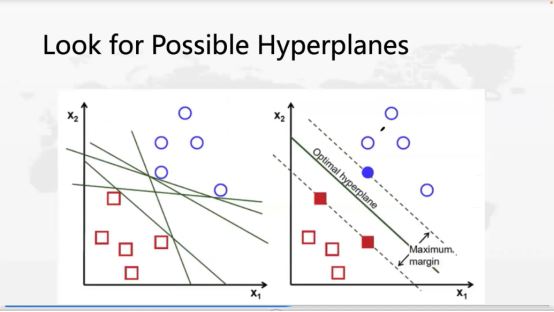
那么SVM的基本原理是什么呢?首先,我们确定将SVM作为分类器,圆圈是一类,正方形是一类,其实我们想找一个超平面(Hyper planes),一个可以把它们分开的分界线。左图中绿色的线有好几条,可以各种方向地画,但是哪条线效率最高呢?SVM的特别之处就在于,它不画一条线,而是两条,这两条线分别向不同分类的方向扩展,图中的margin区间越大越好。也就是说,当线移动到分类的点时就停止,这时就找到最大margin区域,用这个区域来分割这两类点,这就是SVM的方法。
在找margin区域时,两条线分别在两边碰到了边界点,这个边界点就可以把它叫做支持向量(Support Vectors)。这个算法本身就是找最大Margin去解决分类问题。

刚刚那个例子可能会让大家感到疑惑,因为我们是用直线做的,那有没有可能这个区域是曲线呢?这种情况也非常多。
比如,线性回归就是简单的方程,但是在项目中你可以用曲线去预估值。现在是用直线去分割不同的类别,你可能也会用曲线分割,两者之间的区别就是kernel不同。kernel是一个函数,在SVM中可以选择不同的kernel,它可以是线性的,也可以是非线性的。线性的就是一个简单的分类模型,如果是非线性的,可能是一个Polynomial的模型。
原理这部分就讲到这了,接下来,我们来看编程部分。如果我们用SVM作为分类器,它有几个主要的参数,C、kernel、degree、gamma。kernel主要有linear、poly、rbf、sigmoid。degree是关于poly核函数的,比如一个函数,如果是线性的,那就是y=a+bx;如果degree=2,y=a+bx1+cx1x2+bx12,这就是poly核函数的degree。gamma是rbf、poly、sigmoid核函数的系数。
这些就是我们可以调节的参数,运行分类器的基本方法是先构建一个基础的模型,基础模型可以使用逻辑回归、决策树算法,也可以构建更复杂的模型,随机森林。运行几个模型之后,使用前面的评估指标选出一个效果最佳的算法。比如,最佳模型是随机森林,之后就是调节算法的参数,就是这页讲的Tune parameters。在SVM中可以调试这几种主要参数,C可以选三个值,kernel可以选几个,degree可以选三个值,参数通过不同的排列组合,用评估指标找到最优模型的最优参数。
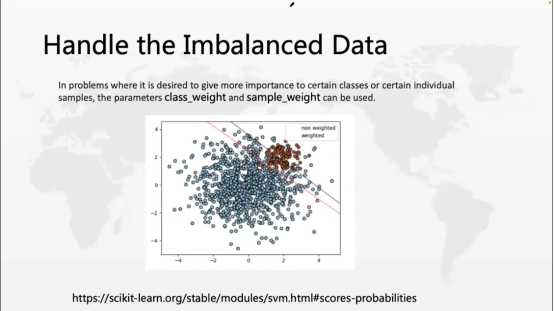
接下来我们看一下SVM的一些特殊的情况。
第一个情况是处理不平衡数据,什么是不平衡数据呢?在训练二分类模型时,两组类别数据量不相当,它们之间有很大差别,这个就叫不平衡数据。在我们实际生活中经常遇到的这种问题,比如我们前面讲的email,在成千上万email中,垃圾邮件占少数,大部分不是垃圾邮件。
第二种是信用卡欺诈,大部分的信用卡交易都是正常的,真正欺诈占少数。这在工业界中是一种常见的现象。那SVM有没有方法去处理这个问题呢?它使用class_weight和sample_weight这两个参数去调节,那它的调节方法是什么呢?如果1比较少,0比较多,那么可以给1加一些权重。
没有加权重时,分类器可能更多的考虑多数的一方。小的一部分由于数量少学的不多,就可以进行加权。SVM其实也相当于一个处理不平衡数据的方法。那么处理不平衡数据集还有哪些方法呢?
除了在算法里面对少数进行加权,其他的方法比如说重新采样(重新采样又包括up和downsize)。顾名思义,Downsize就是要减少数量集,可以把多的数据减少一部分,这样就可以让多和少两个集合的比例稍微平衡一点。但这种方法的缺点是牺牲了一些我们需要的数据集。Upsize就是增加,通过拷贝数据增加数据量;另一种是smock,就是产生一些新的样本,但是产生的这些样本是根据原有的少数集合里面的样本去产生一些。处理不平衡的数据大概就是这么几个方法。
SVM本身是可以做回归算法的,不仅仅是分类器。如下图,比如原来是[0,0]一组对应0.5,[2,2]一组对应2.5,[1,1]一组对应1.5,也是可以做回归算法用的。

分类器是找到几个周边重要的点,SVM做回归也是要找周边的一些点进行计算,只不过它的成本函数会把周边的一些点忽略掉。
最后就是关于分类器的优缺点了。每一个分类器的算法都有自己的优点和缺点,SVM的优点包括:效果很好,有清晰的分隔距;在高维空间中是有效的,也是它的特色之一;在列数比行数大的情况下,它是有效的;训练的机器如果内存比较小的话,内存效率相对来说也会更高一些。

它的缺点:当我们有一个大的数据集,由于所需的训练时间更长,所以不能很好地执行;另外,当数据集有更多的重叠时,也不会执行得很好;另外,它不能直接提供概率估算,但是在Python实现、SVC实现的时候,decision function可以帮助解决不提供概率估算这个弱项。

在本文中,我们详细研究了机器学习算法——支持向量机。我们讨论了它的工作原理,在代码中的实现过程,通过调整参数使模型高效的技巧,以及模型优点和缺点。你有没有使用 SVM 的经验?对这个模型有什么想法?欢迎在文章下方留言!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Recap 作者:数据应用学院
美工编辑:过儿
校对审稿:佟佟
公开课回放链接:https://www.youtube.com/watch?v=C2b7bi8FxWU



