
Python的自回归分布滞后模型简介
在这里,你将学习如何使用多变量时间序列创建预测模型。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
使用Python和R的五个简单快捷的技巧——让你成为高效数据科学家
数据工程——Scala与Python的区别
【Python-数据科学】Pandas Basics速查表(2023)
如何使用Python进行运动检测?
如果时间序列包含多个变量,那么它就是多元的。
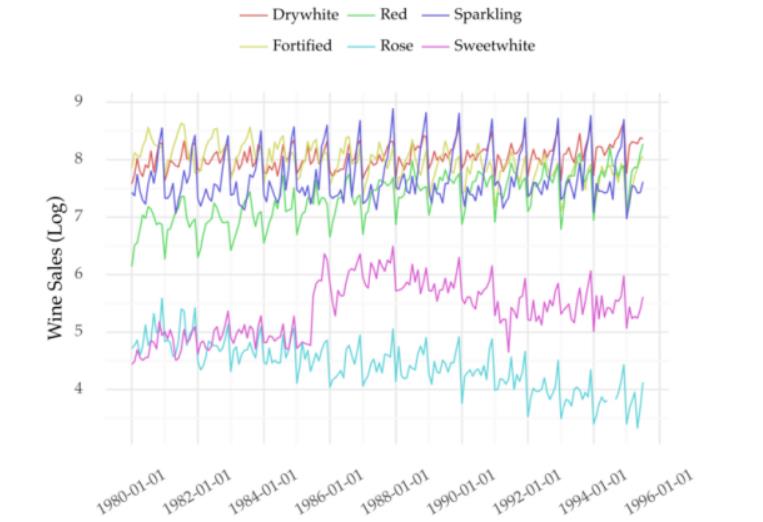
示例详见图1。它显示了多种葡萄酒月度销售的多变量时间序列。每种葡萄酒都是时间序列的一个变量。
假设你想预测其中一个变量。比如起泡酒的销量(个人喜好)。你如何通过一个模型来实现?
常见的方法就是将该变量视为单变量时间序列。有很多模拟这些序列的方法。例如ARIMA,exponential smoothing,或者Facebook的Prophet,自动回归机器学习方法被越来越多地使用(https://towardsdatascience.com/machine-learning-for-forecasting-transformations-and-feature-extraction-bbbea9de0ac2)。
然而,其他变量也可能包含起泡酒未来销售的重要线索。详见下面的矩阵。
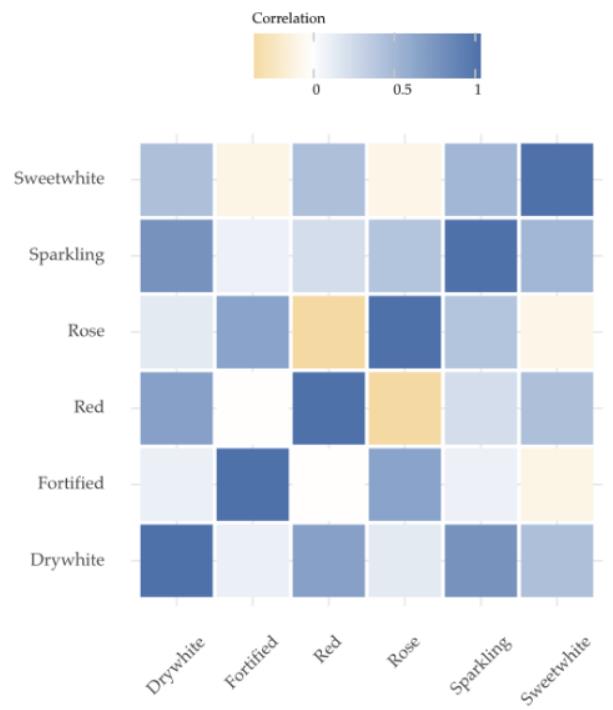
起泡酒的销量(第二排)与其他葡萄酒的销量表现出良好的相关性。
因此,尝试在模型中包含这些变量可能是一个好主意。
我们可以使用一种称为自回归分布滞后(ARDL)的方法来完成。
自回归分布滞后
单变量时间序列的自回归
顾名思义,ARDL模型以自回归为基础。
自回归是大多数单变量时间序列模型的基础。它主要有两个步骤。
首先,我们将(单变量)时间序列从值序列转换为矩阵,用时间延迟嵌入法来实现这一点。尽管这个名字很花哨,但方法却很简单。其根本就是基于之前的最近值对每个值进行建模。了解详细的解释和实施情况,详见我之前的帖子(https://towardsdatascience.com/machine-learning-for-forecasting-transformations-and-feature-extraction-bbbea9de0ac2)。
然后,我们再建一个回归模型。未来值表示目标变量。解释变量代表最近的值(https://towardsdatascience.com/machine-learning-for-forecasting-transformations-and-feature-extraction-bbbea9de0ac2)。
多变量情况
概念与多元时间序列相似。但是,你也可以将其他变量的过去值添加到解释变量中。这成了一种叫做“多变量时间序列”的方法。但是,你也可以将其他变量的过去值添加到解释变量中。这导致了一种称为“自回归分布滞后”的方法。分布滞后含义是指使用额外变量的滞后性。
把他们放在一起。时间序列中变量的未来值就取决于自身的滞后和其他变量的滞后。
为了使这个方法更清晰明白,我们对其进行了编码。
亲身实践
多变量时间序列通常指许多相关产品的销售数据。我们将以葡萄酒销售时间序列为例。你可以从https://rdrr.io/cran/Rssa/man/AustralianWine.html或https://pkg.yangzhuoranyang.com/tsdl/得到它,ARDL方法也适用于零售以外的其他领域。
转换时间序列
我们先使用以下脚本转换时间序列。
import pandas as pd
# https://github.com/vcerqueira/blog/
from src.tde import time_delay_embedding
wine = pd.read_csv('data/wine_sales.csv', parse_dates=['date'])
# setting date as index
wine.set_index('date', inplace=True)
# you can simulate some data with the following code
# wine = pd.DataFrame(np.random.random((100, 6)),
# columns=['Fortified','Drywhite','Sweetwhite',
# 'Red','Rose','Sparkling'])
# create data set with lagged features using time delay embedding
wine_ds = []
for col in wine:
col_df = time_delay_embedding(wine[col], n_lags=12, horizon=6)
wine_ds.append(col_df)
# concatenating all variables
wine_df = pd.concat(wine_ds, axis=1).dropna()
# defining target (Y) and explanatory variables (X)
predictor_variables = wine_df.columns.str.contains('\(t\-')
target_variables = wine_df.columns.str.contains('Sparkling\(t\+')
X = wine_df.iloc[:, predictor_variables]
Y = wine_df.iloc[:, target_variables]
view raw
tde_mv.py hosted with ❤ by GitHub我们将函数time_delay_embedding(https://towardsdatascience.com/machine-learning-for-forecasting-transformations-and-feature-extraction-bbbea9de0ac2)应用于时间序列中的每个变量(第18–22行)。结果在第23行被连接到单个Pandas数据帧中。
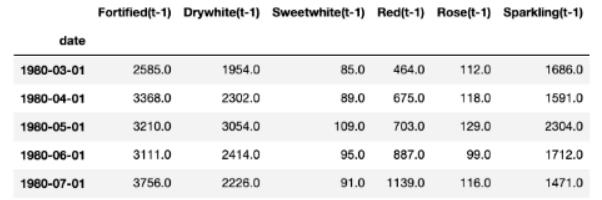
解释变量(X)是每个时间步上(第29行)每个变量的最后12个已知值。以下是它们如何查找滞后t-1(为简洁,省略了其他滞后数)。
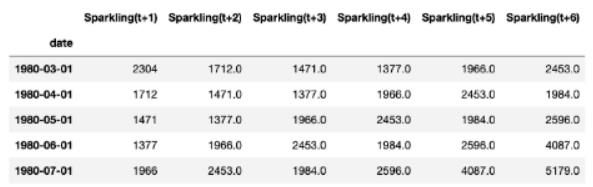
第30行定义了目标变量。这些变量指的是未来起泡酒销售的6个值:
构建模型
准备好数据之后,就可以构建模型了。下面,我使用随机森林算法完成了一个简单的训练和测试周期。
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error as mae
from sklearn.ensemble import RandomForestRegressorfrom sklearn.ensemble import RandomForestRegressor
# train/test split
X_tr, X_ts, Y_tr, Y_ts = train_test_split(X, Y, test_size=0.3, shuffle=False)
# fitting a RF model
model = RandomForestRegressor()
model.fit(X_tr, Y_tr)
# getting forecasts for the test set
preds = model.predict(X_ts)
# computing MAE error
print(mae(Y_ts, preds))
# 288.13
view raw
mv_tde_model.py hosted with ❤ by GitHub在拟合模型(第11行)之后,我们再从测试中得到预测结果(第14行)。该模型的平均绝对误差为288.13。
选择滞后数

我们使用每个变量的12个滞后数作为解释变量。这是在函数time_delay_embedding的参数n_lags中定义的。该如何设置此参数的值呢?
很难说应该包含多少值。这取决于输入数据和特定变量。
简单的方法就是使用特征选择。首先,从大量的值开始。然后再根据重要性得分或预测性能减少该数字。
这是该过程的简化版本。首先,根据随机森林的重要性得分选择前10个特征。
然后就是不断重复训练和测试周期。
# getting importance scores from previous model
importance_scores = pd.Series(dict(zip(X_tr.columns, model.feature_importances_)))
# getting top 10 features
top_10_features = importance_scores.sort_values(ascending=False)[:10]
top_10_features_nm = top_10_features.index
X_tr_top = X_tr[top_10_features_nm]
X_ts_top = X_ts[top_10_features_nm]
# re-fitting the model
model_top_features = RandomForestRegressor()
model_top_features.fit(X_tr_top, Y_tr)
# getting forecasts for the test set
preds_topf = model_top_features.predict(X_ts_top)
# computing MAE error
print(mae(Y_ts, preds_topf))
# 274.36
view raw
mv_tde_model_top_feats.py hosted with ❤ by GitHub与之前的原始预测指标相比,前十个特征显示出更好的预测性能。以下是这些功能的重要性评分:
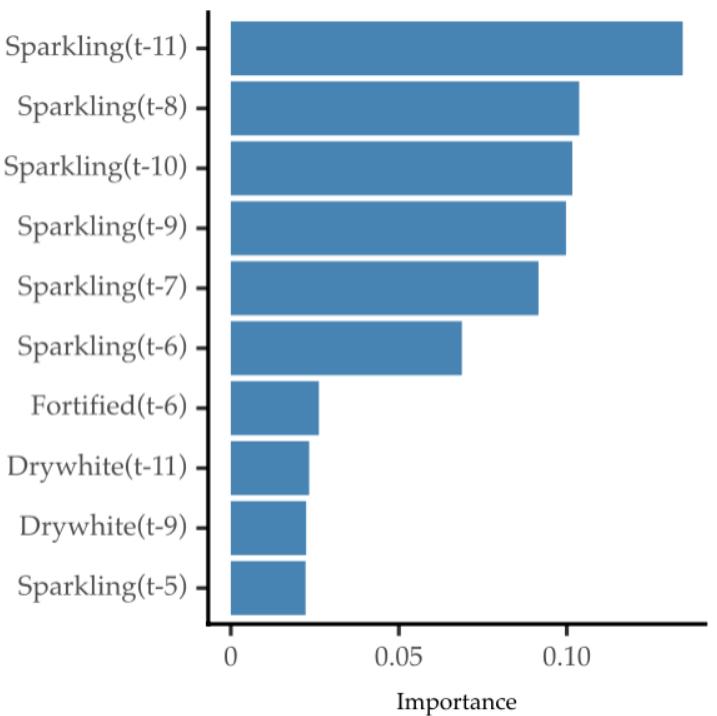
正如预期的那样,目标变量(起泡酒)的滞后性是非常最重要的。但是,其他变量的一些滞后性也是相关的。
ARDL的扩展
多目标变量
我们旨在预测单一变量(起泡酒)。如果我们有兴趣预测多个呢?
这就是一种称为向量自回归(VAR)的方法。
与ARDL一样,每个变量都是基于其滞后和其他变量的滞后进行建模的。VAR用于预测多个变量,而不仅仅直是一个变量。
与全球预测模型的关系
值得注意的是,ARDL和全球预测模型(https://medium.com/towards-data-science/introduction-to-global-forecasting-models-3ca8e69a6524)不同。在ARDL的情况下,每个变量的信息都被添加到解释变量之中。变量的数量通常较低而且大小也相同。
全球预测模型汇集了许多时间序列的历史观测结果。该模型符合所有观察结果。因此,每个新系列都作为新的观测值被添加。此外,全球预测模型通常还涉及数千个时间序列。
总结
- 多变量时间序列包含两个或多个变量。
- ARDL方法可用于多变量时间序列的监督学习。
- 使用特征选择策略优化滞后数。
- 使用VAR法预测多个变量。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
参考资料:
[1] Rob Hyndman and Yangzhuoran Yang (2018). tsdl: Time Series Data Library. v0.1.0. https://pkg.yangzhuoranyang.com/tsdl/
原文作者:Vitor Cerqueira
翻译作者:王文龙
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/machine-learning-for-forecasting-supervised-learning-with-multivariate-time-series-b5b5044fe068





