
金融中的机器学习:利用随机森林掌握时间序列分类
随机森林是机器学习中的一种集成学习技术,它将多个决策树组合在一起进行预测。它们值得研究,因为它们具有高准确性,可以处理分类和回归任务,并且能够抵抗过度拟合,同时需要最少的超参数调整,使它们成为数据科学和预测建模中强大且多功能的工具。
本文展示了如何编写一个简单的分类随机森林模型来预测标准普尔500指数的每日涨跌走势。如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
机器学习中的文本分类是什么?
50多次ML面试(作为面试官)教会了我什么?
深度学习面试的35个经典问题和答案,建议收藏!
数据科学初学者必备的7个备忘单!
分类与随机森林
时间序列分类预测是指基于历史时间序列数据,应用分类算法对分类结果或类别进行预测。在这种情况下,时间序列数据是指在一段时间内收集的连续观测数据,分类预测旨在将未来的数据点或时间段分类为预定义的类或类别。
在分类预测中,目标是基于历史时间序列数据预测一个分类结果或目标变量。这种分类结果可以采用离散的类别标签,例如股票价格变动的“上涨”或“下跌”,传感器读数的“正常”或“异常”,或任何其他相关类别。
随机森林是一种强大的集成学习方法,用于分类和回归任务。它们属于基于决策树的算法家族,以其多功能性、鲁棒性和处理复杂数据的能力而闻名。
随机森林结合了多个独立决策树的预测,以做出更准确、更稳健的预测。集成学习背后的思想是,通过组合多个模型的结果,你通常可以获得比单个模型更好的整体性能。
随机森林的核心是决策树。决策树是一种有监督的机器学习模型,它通过根据特定的特征值将输入数据划分为子集并创建决策节点的树状结构来做出决策。随机森林采用了一种叫做自助聚合(Bootstrap aggregating)的技术,简称Bagging。Bagging涉及到创建多个随机子集(替换)原始数据集。
每个子集用于训练一个单独的决策树。这个过程减少了方差,并有助于防止过拟合,因为每棵树看到的数据版本略有不同。除了使用自助样本外,随机森林还通过在决策树的每个节点上只选择随机的特征子集来引入随机性。这有助于去相关,并进一步提高模型的鲁棒性。
一旦所有单独的决策树都经过训练,它们就会被组合起来进行预测。对于分类任务,每棵树为一个类“投票”,投票最多的类成为最终预测。
下面的插图展示了随机树的工作原理。
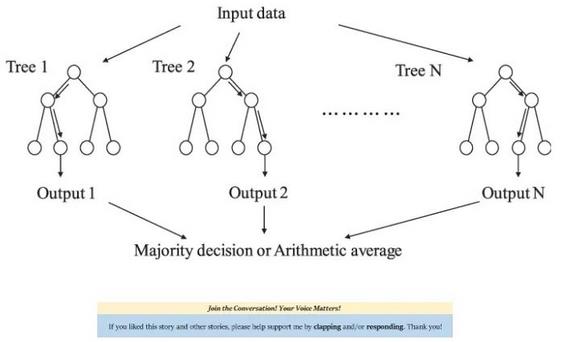
创建算法
分类任务将使用一个金融时间序列的例子,标准普尔500指数,操作步骤如下:
- 在Python中导入每日标准普尔500指数值。
- 通过取每个收盘价和前一个收盘价之间的差异使数据平稳。
- 将数据分类,正差异标记为1,负差异标记为-1。
- 创建一个数组,其中包含延迟最多为50的分类变量(这表明你将拥有多列数组)。
- 在训练集上拟合随机森林模型。
- 使用拟合模型对测试集进行预测。
- 使用准确性(来自测试集的预测变量和实际变量之间匹配的变量数量)和Cohen’s Kappa来评估结果。
完成此操作的完整代码如下(请记住,你必须从提示符中pip安装pandas_datareader):
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, cohen_kappa_score
import pandas_datareader as pdr
import matplotlib.pyplot as plt
def data_preprocessing(data, num_lags, train_test_split):
# Prepare the data for training
x = []
y = []
for i in range(len(data) - num_lags):
x.append(data[i:i + num_lags])
y.append(data[i+ num_lags])
# Convert the data to numpy arrays
x = np.array(x)
y = np.array(y)
# Split the data into training and testing sets
split_index = int(train_test_split * len(x))
x_train = x[:split_index]
y_train = y[:split_index]
x_test = x[split_index:]
y_test = y[split_index:]
return x_train, y_train, x_test, y_test
start_date = '1960-01-01'
end_date = '2023-09-01'
# Set the time index if it's not already set
data = (pdr.get_data_fred('SP500', start = start_date, end = end_date).dropna())
# Perform differencing to make the data stationary
data_diff = data.diff().dropna()
# Categorizing positive returns as 1 and negative returns as -1
data_diff = np.reshape(np.array(data_diff), (-1))
data_diff = np.where(data_diff > 0, 1, -1)
x_train, y_train, x_test, y_test = data_preprocessing(data_diff, 50, 0.80)
# Create and train a Random Forest Classifier
model = RandomForestClassifier(n_estimators = 100, random_state = 0)
model.fit(x_train, y_train)
# Make predictions
y_predicted = model.predict(x_test)
# Evaluate the model
accuracy = accuracy_score(y_test, y_predicted)
kappa = cohen_kappa_score(y_test, y_predicted)
print(f"Accuracy: {accuracy:.2f}")
print(f"Kappa: {kappa:.2f}")代码输出如下:
Accuracy: 0.55Kappa: 0.10这个简单的模型在分类上升或下降数据上达到55%的准确率,Cohen’s Kappa为0.10。
Cohen’s Kappa是一种衡量一致性的方法,它量化了两个评分者或评估者之间超出随机机会预期的一致性程度。这种解释可能会有所不同,但以下是评估一致性程度的一些常见准则:
- 低于零:表示一致性低于偶然预期。评估者之间可能存在系统性分歧。
- 0到0.20之间:表示稍有一致。这一协议只比随机情况下的预期稍微好一点。
- 0.21 ~ 0.40:表示基本一致。该协议是温和的,但仍有改进的空间。
- 0.41 ~ 0.60:表示中等一致。该协议是实质性的,并被普遍认为是可以接受的。
- 在0.61到0.80之间:表示较高的一致。这种一致性很强,评估者之间的一致性也很高。
- 在0.81和1.00之间:表示几乎完全一致。一致性非常高,评估者之间的一致性近乎完美。
合适的一致性水平可能受到诸如错误分类的后果和分类任务的难度等因素的影响。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Sofien Kaabar, CFA
翻译作者:文杰
美工编辑:过儿
校对审稿:Chuang
原文链接:https://kaabar-sofien.medium.com/machine-learning-in-finance-mastering-time-series-classification-with-random-forests-773acc3cca71




