
Market Basket Analysis:把握电商求职核心的购物篮分析是什么?
Market Basket Analysis – 这是一种由Amazon、Walmart等大型零售商使用的关键技术,通过发现顾客放在“购物篮”中的不同商品之间的关联,来分析顾客的购买习惯。
发现这些关联可以帮助零售商洞察哪些商品经常被顾客一起购买来制定营销策略。比如:根据潮流改变实体店布局,客户行为分析,商品分类目录设计,线上商品交叉营销,分析顾客购买的趋势产品是什么,定制电子邮件等。
这个分析的主要的目的在于找出什么样的东西应该放在一起。藉由顾客的购买行为来了解是什么样的顾客以及这些顾客为什么买这些产品,找出相关的联想(association)规则,企业藉由这些规则的挖掘获得利益与建立竞争优势。
作为一个合格的商业分析师及Data Scientist,希望在电商、零售等领域工作,了解和学会购物篮分析可以大大提高自己的核心技能以及面试的成功率。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
MBA转行商业分析师的四点建议
找工作前必知:商业分析师如何通过预测分析来创建客户体验?
吐血整理:史上最全美国数据科学、商业分析本科及研究生项目介绍(附项目特色及学分要求)
1.让我们从一个美国沃尔玛的小故事引入今天的话题吧
“啤酒和尿布”的故事是一个market basket rule在现实中运用的经典案例。在这个故事里,沃尔玛的数据分析师发现,大部分男性在沃尔玛购物时,他们的消费清单里都会同时出现啤酒和尿布这两种产品。沃尔玛决定根据这个调查得到的数据,从新排列了尿布和啤酒的物品位置排列顺序,使他们更加贴近,让购物者能够更加方便的同时购买这两种商品。至此,显著的提升了这两个产品的销量。
2.Market basket analysis就是上一个故事中所用到的知识
Market basket analysis顾名思义,是用来分析顾客购买习惯的,主要有以下几个特点:
- 1.它提供了对客户“购物篮”中产品组合的洞察
- 2.“购物篮”这个术语通常适用于单个订单
- 3.经常比较与单个客户相关的所有订单
- 4.最终,购买洞察力提供了创建交叉销售主张的潜力1)购买哪些组合2)什么时候购买3)购买的顺序
总而言之,market basket analysis就是通过数据分析的方法,去找到需要的组合从而促进产品的销售。
3. 那么market basket analysis如何帮助企业促进销售的增长呢
- 首先,公司需要宣传并推销其最为盈利的产品
- 其次,公司应该鼓励并提醒顾客去购买那些容易被顾客忽略的产品
从下图,我们可以清楚的看到Amazon是如何运用这个分析手法来推销产品的。

除了以上的方法,还有更多的方法可以供商家考虑。
- 1.改变商店物品的排列顺序
- 2.对顾客消费习惯的分析
- 3.商品目录设计
- 4.线上商店的交叉营销
- 5.带有附件的定制化电子邮件等
4.那么这个association rule是如何运算的呢

Association rule就是需要找到购买产品的规律,从上图我们可以看到。当顾客购买产品A时,他也可能购买产品B。其中产品A为 support,产品B为confidence。
用沃尔玛啤酒和尿布的故事作为一个例子。

商家就是运用association rule来寻找不同的组合从找到契合度最高的产品组合来提升销量。
下图为用方程式的形式来展示Association rule的算法。

我们将为这个方程式带入一些数字,使其变得通俗易懂。

5.Apriori Algorithm & Finding item rules with high confidence or lift
Apropri Algorithm是通过大数据来研究出什么产品组合最有可能被消费者广泛购买,被广泛的使用在basket analysis里。在根据Apropri Algorithm找到需要的数据后,产品公司可以在这些数据中finding item rules with high confidence or lift
6.购物篮分析之定义客户购买喜好
在运用market basket analysis时,需要注意的是这个分析只注重于单个顾客的消费。如果想要分析所有顾客的消费习惯以及组合,就不能称为basket analysis。所有顾客的消费习惯的调查只能告诉公司其最为流行的产品。
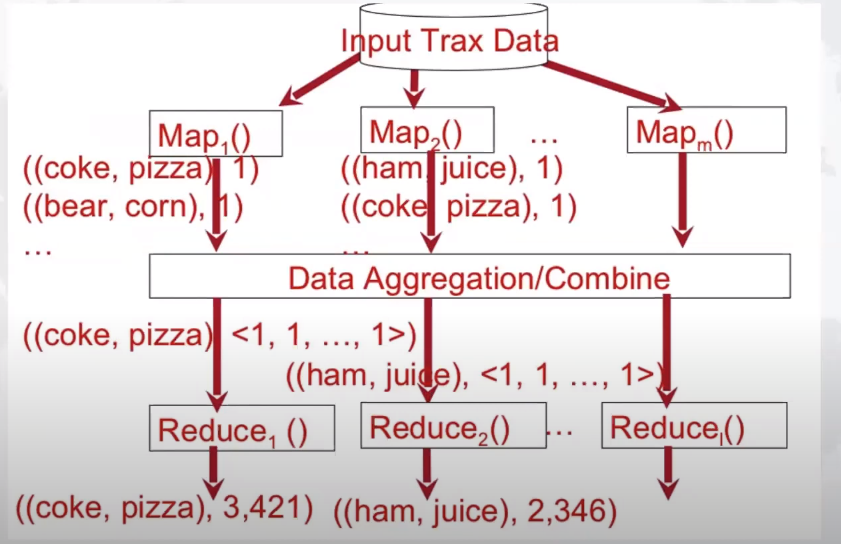
7.Map reduce对于拥有大数据的公司比如Amazon以及谷歌极为重要
当这些公司想要计算这些庞大的数据时,他们会用到的一个方法就是Map reduce。Map reduce就是把大数据平均分配为对等的小数据,使数据分布式化,并把这个数据放到独立的机器中进行运算。从而促进运算效率。
首先我们运用以下的方法求出每个排列组合,得到这些组合出现的顺序。

然后把求出的排列组合传输到reduce里面。

其中key为组合,value为组合出现的次数。
然后对不同map里出现的排列组合来进行shuffle“洗牌”。

在完成各个不同map的shuffle过后,把这些结果传送给reduce从而做一个总和得到最终结果。

最后用一个图片来概括整个map reduce的运算过程。
以上就是本次公开课的所有内容了,希望对求职的小伙伴们提供到帮助!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Recap 作者:Peter Mei
美工编辑:过儿
校对审稿:冬冬
公开课回放链接:https://www.youtube.com/watch?v=C1s6yXy4PYc&list=PL39P3XK_jveHE89PgwwvVPAGAj2cuxRrT&index=38&ab_channel=DataApplicationLabDataApplicationLab





