工具:帮助你精通数据科学工作流")
助手类(Helper Classes)工具:帮助你精通数据科学工作流
在计算机编程中,类是组织数据(属性)和函数(方法)的有用方法。你可以定义一个类,然后用来定义与机器学习模型相关的属性和方法,比如,此类类的实例可能具有诸如训练数据文件名、模型类型等属性。与这些属性相关的方法可以是拟合、预测和验证。
除机器学习外,类在整个数据科学领域都有广泛的应用。你可以使用类来系统化各种EDA任务、特征工程操作和机器学习模型训练。如果任务定义得够好,类可以帮助我们更好地理解、修改和调试现有的属性和方法,如果将类方法定义为完成一个定义良好的任务,则尤其如此。通常,定义只做一件事的函数和类是很好的做法,这样可以更直接地理解和维护这些方法。
虽然使用类可以使维护代码变得更加简单,但用得多了,它也会变得很难理解。如果你对基本的EDA、特征工程和模型训练的属性和方法感兴趣,一个类可能就足够了。但是,当你为每种类型的任务添加更多的属性和方法时,整体看上去就会显得模糊复杂(尤其是对于阅读你的代码的协作者)。考虑到这一点,随着复杂性的增加,最好为每种类型的任务(EDA、特征工程、机器学习)配备助手类。在开发复杂的工作流时,应该有单独的EDA、特征工程和机器学习类,而不是单一的类。

于此,我们将考虑这些不同类型的任务中的每一种,并了解如何编写让我们能够执行它们的单个类。对于EDA,我们的类将允许我们读入数据,生成直方图和散点图。对于特征工程,我们的类将有一个进行对数变换的方法。最后,对于机器学习,我们的类将有拟合,预测和验证方法。
我们将看到,当我们添加额外的属性和方法时,类实例化和方法调用变得更加难以阅读。我们将为每个任务类型添加额外的方法和属性,并说明当我们让其变复杂时,是怎么影响其可读性的。在此基础上,我们将了解如何将类的各个部分划分为更易于理解和管理的助手类。
以下,我将在Deepnote(一个协作性的数据科学notebook,使运行可重复的实验变得非常容易)里编码,同时使用医疗成本数据集,依据患者属性(如年龄、身体质量指数和子女数量)来预测医疗费用。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
打好数据科学和机器学习的基础——6本书带你学数学
数据科学家或将成为历史?——无代码数据科学的诞生
每个数据科学家都必须遵循的技巧
数据科学面试中的机器学习问题类型以及如何准备这些问题?
OOP Bookkeeping模型类型
首先,我们在DeepNote上创建一个新项目(如果你还没有帐户,可以免费注册)。
让我们创建一个名为“Helper_classes”的项目,并在该项目中创建一个名为“Helper_classes_ds”的notebook。然后,让我们将Insurance.CSV文件拖放到页面上显示“FILES”的左侧面板上:
接着,我们继续定义一个类,包含机器学习工作流中的一些基本步骤——从导入我们将使用的所有包开始:
from sklearn.linear_model import LinearRegression
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_absolute_error
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd我们定义一个名为“MLWorkflow”的类,它包含一个init方法,我们将使用该方法来存储模型预测和性能,同时,我们定义一个存储医疗成本数据的类属性:
class MLworkflow(object):
def __init__(self):
self._performance = {}
self._predictions = {}
self.data = pd.read_csv("insurance.csv")接下来,我们定义一个名为“eda“的方法,执行一些简单的可视化工作。如果为变量直方图传递“True”值,它将为指定的数值特征生成直方图;如果为变量scatter_plot传递“True”值,它将生成针对目标的数值特征的散点图:
class MLworkflow(object):
...
def eda(self, feature, target, histogram, scatter_plot):
self.corr = self.data[feature].corr(self.data[target])
if histogram:
self.data[feature].hist()
plt.show()
if scatter_plot:
plt.scatter(self.data[feature], self.data[target])
plt.show()接下来,我们定义另一个名为“data_prep”的方法来定义我们的输入和输出。同时,我们定义一个名为transform的参数,我们可以使用它来对数值列进行对数变换:
class MLworkflow(object):
...
def data_prep(self, features, target, transform):
for feature in features:
if transform:
self.data[feature] = np.log(self.data[feature])
self.X = self.data[features]
self.y = self.data[target]然后,我们定义一个拟合方法,拆分用于训练和测试的数据,其中test_size可以由“split”参数指定。我们还将提供适合线性回归或随机森林模型的选项,可以扩展到任意数量的模型类型:
class MLworkflow(object):
...
def fit(self, model_name, split):
X_train, X_test, y_train, y_test = train_test_split(self.X, self.y, random_state=42, test_size=split)
self.X_test = X_test
self.y_test = y_test
if model_name == 'lr':
self.model = LinearRegression()
self.model.fit(X_train, y_train)
elif model_name == 'rf':
self.model = RandomForestRegressor(random_state=42)
self.model.fit(X_train, y_train)接着,我们定义一个在测试集上生成预测的方法。我们将结果存储在预测字典中,其中字典键是模型类型:
class MLworkflow(object):
...
def predict(self, model_name):
self._predictions[model_name] = self.model.predict(self.X_test)最后,我们计算每种模型类型的性能。我们使用平均绝对误差作为我们的性能指标,并使用验证方法将值存储在我们的性能字典中:
class MLworkflow(object):
...
def validate(self, model_name):
self._performance[model_name] = mean_absolute_error(self._predictions[model_name], self.y_test)
The full class is as follows:
class MLworkflow(object):
def __init__(self):
self._performance = {}
self._predictions = {}
self.data = pd.read_csv("insurance.csv")
def eda(self, feature, target, histogram, scatter_plot):
self.corr = self.data[feature].corr(self.data[target])
if histogram:
self.data[feature].hist()
plt.show()
if scatter_plot:
plt.scatter(self.data[feature], self.data[target])
plt.show()
def data_prep(self, features, target, transform):
for feature in features:
if transform:
self.data[feature] = np.log(self.data[feature])
self.X = self.data[features]
self.y = self.data[target]
def fit(self, model_name, split):
X_train, X_test, y_train, y_test = train_test_split(self.X, self.y, random_state=42, test_size=split)
self.X_test = X_test
self.y_test = y_test
if model_name == 'lr':
self.model = LinearRegression()
self.model.fit(X_train, y_train)
elif model_name == 'rf':
self.model = RandomForestRegressor(random_state=42)
self.model.fit(X_train, y_train)
def predict(self, model_name):
self._predictions[model_name] = self.model.predict(self.X_test)
def validate(self, model_name):
self._performance[model_name] = mean_absolute_error(self._predictions[model_name], self.y_test)我们可以定义这个类的一个实例并生成一些可视化图:
mlworkflow = MLworkflow()
mlworkflow.eda('age', 'charges', True, True)
print(mlworkflow.corr)
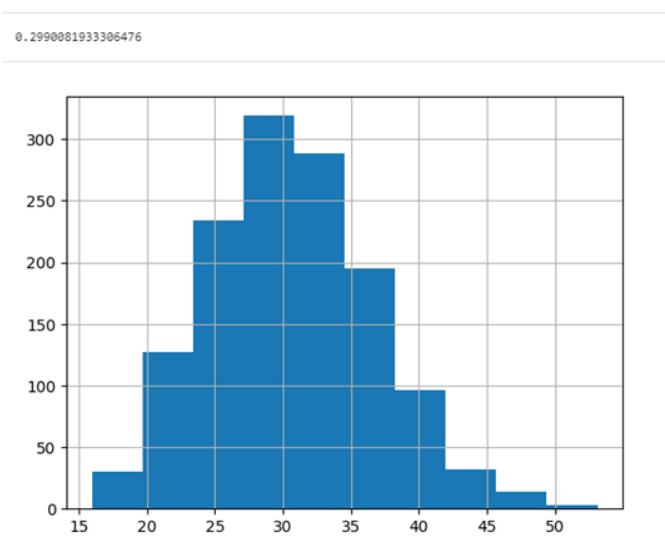
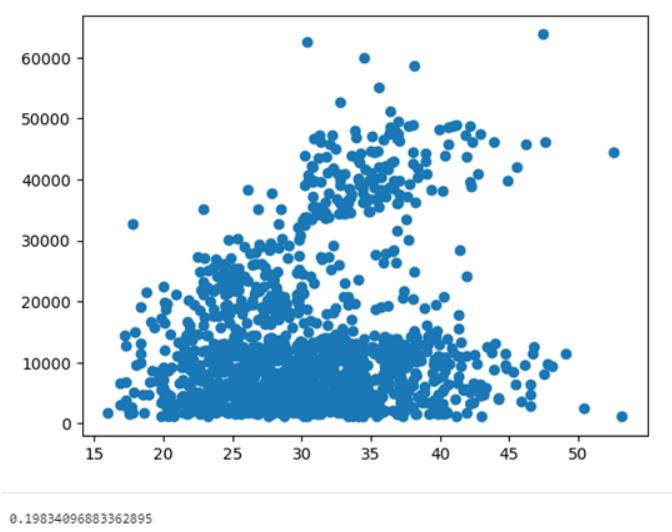
mlworkflow.eda('bmi', 'charges', True, True)
print(mlworkflow.corr)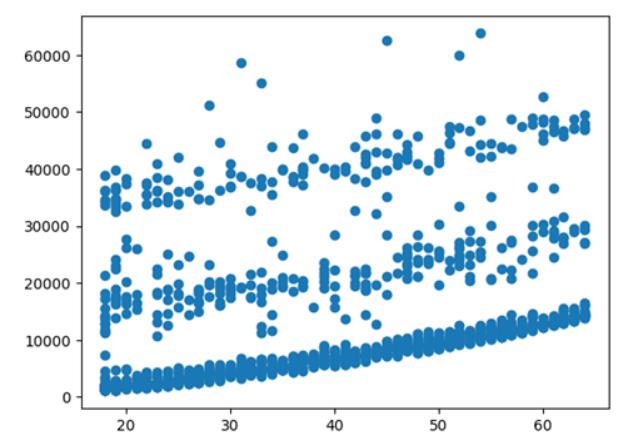
然后,我们定义一个实例并构建线性回归和随机森林模型。我们首先定义类的一个实例,并使用我们希望使用的输入和输出调用数据预处理方法:
model = MLworkflow()
features = ['bmi', 'age']
model.data_prep(features, 'charges', True)接着,我们通过使用线性回归的model_name参数值“lr”和20%的test_size拟合方法来构建线性回归模型。我们在模型实例上调用预测和验证方法:
model.fit('lr', 0.2)
model.predict('lr')
model.validate('lr')我们可以对我们的随机森林模型做同样的事:
model.fit('rf', 0.2)
model.predict('rf')
model.validate('rf')因此,我们的模型对象将具有一个名为“_performance”的属性。我们可以通过模型对象访问它并输出数据:
model = MLworkflow()
features = ['bmi', 'age']
model.data_prep(features, 'charges', True)
model.fit('lr', 0.2)
model.predict('lr')
model.validate('lr')
model.fit('rf', 0.2)
model.predict('rf')
model.validate('rf')
print(model._performance)
{'lr': 9232.307984997156, 'rf': 9161.66313279731}我们看到,字典键“LR”和“RF”的平均绝对误差值分别为9232和9161。
Bookkeeping模型类型和Single类分类分段训练数据
虽然用于定义该类的代码足够简单,但随着复杂化,它可能变得难以阅读和解释。例如,如果除了能够监视模型_类型,我们还希望能够在数据中的不同类别上构建模型,该怎么办?例如,如果我们希望只在女性患者身上训练线性回归模型,或者只在男性患者身上训练随机森林模型,又该怎么办?别急,让我们来看看如何编写这个经过修改的类。与之前类似,我们定义了一个init方法,用于初始化必要的字典。我们添加一个名为Models的新字典:
class MLworkflowExtended(object):
def __init__(self):
self._performance = {}
self._predictions = {}
self._models = {}
self.data = pd.read_csv("insurance.csv")EDA和数据预处理方法基本保持不变:
class MLworkflowExtended(object):
...
def eda(self, feature, target, histogram, scatter_plot):
self.corr = self.data[feature].corr(self.data[target])
if histogram:
self.data[feature].hist()
plt.show()
if scatter_plot:
plt.scatter(self.data[feature], self.data[target])
plt.show()
def data_prep(self, features, target, transform):
self.target = target
for feature in features:
if transform:
self.data[feature] = np.log(self.data[feature])拟合方法的变动较大,它现在接受变量model_category和category_values以及我们的随机森林算法的默认值。它还会检查类别值是否在初始化的字典中,如果不是,则使用空字典初始化它们。新字典最外层的键是分类值,包含算法类型及其性能,结构如下:
_performance = {'category1':{'algorithm1':100, 'algorithm2':200}, 'category2':{'algorithm1':300, 'algorithm2':500}我们也会对指定类别上的数据进行筛选,对应的代码如下:
def fit(self, model_name, model_category, category_value, split, n_estimators=10, max_depth=10):
self.split = split
self.model_category = model_category
self.category_value = category_value
if category_value not in self._predictions:
self._predictions[category_value]= {}
if category_value not in self._performance:
self._performance[category_value] = {}
if category_value not in self._models:
self._models[category_value] = {}
self.data_cat = self.data[self.data[model_category] == category_value]剩下的逻辑与我们之前的逻辑类似。完整函数如下:
def fit(self, model_name, model_category, category_value, split, n_estimators=10, max_depth=10):
self.split = split
self.model_category = model_category
self.category_value = category_value
if category_value not in self._predictions:
self._predictions[category_value]= {}
if category_value not in self._performance:
self._performance[category_value] = {}
if category_value not in self._models:
self._models[category_value] = {}
self.data_cat = self.data[self.data[model_category] == category_value]
self.X = self.data_cat[features]
self.y = self.data_cat[self.target]
X_train, X_test, y_train, y_test = train_test_split(self.X, self.y, random_state=42, test_size=split)
self.X_test = X_test
self.y_test = y_test
if model_name == 'lr':
self.model = LinearRegression()
self.model.fit(X_train, y_train)
elif model_name == 'rf':
self.model = RandomForestRegressor(n_estimators=n_estimators, max_depth = max_depth, random_state=42)
self.model.fit(X_train, y_train)
self._models[category_value] = self.model请注意,此函数要复杂得多。
预测和验证方法类似。不同之处在于,我们现在还按类别存储预测和性能:
def predict(self, model_name):
self._predictions[self.category_value][model_name] = self._models[self.category_value].predict(self.X_test)
def validate(self, model_name):
self._performance[self.category_value][model_name] = mean_absolute_error(self._predictions[self.category_value][model_name], self.y_test)完整的类如下:
然后,因模型类型和类别而异,我们可以进行不同的实验。例如,我们在单独的女性和男性数据集上建立线性回归和随机森林模型:
model = MLworkflowExtended()
features = ['bmi', 'age']
model.data_prep(features, 'charges', True)
model.fit('lr', 'sex', 'female', 0.2)
model.predict('lr')
model.validate('lr')
print(model._performance)
model.fit('rf', 'sex', 'female', 0.2)
model.predict('rf')
model.validate('rf')
print(model._performance)
model.fit('rf','sex', 'male', 0.2, 100, 100)
model.predict('rf')
model.validate('rf')
print(model._performance)
model.fit('lr','sex', 'male', 0.2)
model.predict('lr')
model.validate('lr')
print(model._performance)
{'female': {'lr': 8016.511847126879}}
{'female': {'lr': 8016.511847126879, 'rf': 8626.57969374399}}
{'female': {'lr': 8016.511847126879, 'rf': 8626.57969374399}, 'male': {'rf': 10547.991737227838}}
{'female': {'lr': 8016.511847126879, 'rf': 8626.57969374399}, 'male': {'rf': 10547.991737227838, 'lr': 9604.81470061645}}
同样地,我们也能以地域为类别,以下以西南和西北为例:
model = MLworkflowExtended()
features = ['bmi', 'age']
model.data_prep(features, 'charges', True)
model.fit('lr', 'region', 'southwest', 0.2)
model.predict('lr')
model.validate('lr')
print(model._performance)
model.fit('rf', 'region', 'southwest', 0.2)
model.predict('rf')
model.validate('rf')
print(model._performance)
model.fit('rf','region', 'northwest', 0.2, 100, 100)
model.predict('rf')
model.validate('rf')
print(model._performance)
model.fit('lr','region', 'northwest', 0.2)
model.predict('lr')
model.validate('lr')
print(model._performance)
{'southwest': {'lr': 8899.213068898414}}
{'southwest': {'lr': 8899.213068898414, 'rf': 8600.643187882553}}
{'southwest': {'lr': 8899.213068898414, 'rf': 8600.643187882553}, 'northwest': {'rf': 7070.996465990001}}
{'southwest': {'lr': 8899.213068898414, 'rf': 8600.643187882553}, 'northwest': {'rf': 7070.996465990001, 'lr': 7481.114681045734}}虽然运行得很顺利,但运行实验的代码却是很难阅读。例如,在拟合我们的随机森林时,第一次阅读我们代码的人可能不清楚传递给拟合方法的所有值的含义:
model.fit('rf','region', 'northwest', 0.2, 100, 100)而当我们增加类的功能时,这可能对他们来说更加困难。
Bookkeeping模型类型用助手类工具给训练数据分类分段
为了避免使其更加复杂,基于机器学习工作流每个部分定义的助手类就派上用场了。
我们可以从定义一个EDA助手类开始:
class EDA(object):
def __init__(self):
self.data = pd.read_csv("insurance.csv")
def eda(self, feature, target, histogram, scatter_plot):
self.target = target
self.corr = self.data[feature].corr(self.data[target])
if histogram:
self.data[feature].hist()
plt.show()
if scatter_plot:
plt.scatter(self.data[feature], self.data[target])
plt.show()然后,我们可以使用EDA类来访问特征工程类中的数据:
class FeatureEngineering(object):
def __init__(self):
eda = EDA()
self.data = eda.data
def engineer(self, features, target, transform, display):
self.target = target
for feature in features:
if transform and display:
print(f"{feature}/{target} correlation Before log-tranform:", self.data[feature].corr(self.data[self.target]))
self.data[feature] = np.log(self.data[feature])
print(f"{feature}/{target} correlation After log-tranform:", self.data[feature].corr(self.data[self.target]))接下来,我们定义数据预处理类。在数据预处理类的init方法中,我们初始化字典以存储模型、预测和性能。同时,我们使用特征工程类将对数变换应用于BMI和年龄。最后,我们将修改后的数据和目标变量存储在数据预处理属性中:
class DataPrep(object):
def __init__(self):
self._performance = {}
self._predictions = {}
self._models = {}
feature_engineering = FeatureEngineering()
feature_engineering.engineer(['bmi', 'age'], 'charges', True, False)
self.data = feature_engineering.data
self.target = feature_engineering.target
def dataprep(self, model_name, model_category, category_value, split):
self.split = split
self.model_category = model_category
self.category_value = category_value
if category_value not in self._predictions:
self._predictions[category_value]= {}
if category_value not in self._performance:
self._performance[category_value] = {}
if category_value not in self._models:
self._models[category_value] = {}我们在数据预处理类中定义一个数据预处理方法。我们首先定义训练/测试split模型类别和类别值的属性。然后,我们检查类别值是否出现在我们的预测、性能和模型字典中。如果没有,我们为新类别存储一个空字典:
class DataPrep(object):
...
def dataprep(self, model_name, model_category, category_value, split):
self.split = split
self.model_category = model_category
self.category_value = category_value
if category_value not in self._predictions:
self._predictions[category_value]= {}
if category_value not in self._performance:
self._performance[category_value] = {}
if category_value not in self._models:
self._models[category_value] = {}然后,我们筛选我们的类别,定义输入和输出,拆分用于训练和测试的数据,并将结果存储在数据预处理属性中:
class DataPrep(object):
...
def dataprep(self, model_name, model_category, category_value, split):
...
self.data_cat = self.data[self.data[model_category] == category_value]
self.X = self.data_cat[features]
self.y = self.data_cat[self.target]
X_train, X_test, y_train, y_test = train_test_split(self.X, self.y, random_state=42, test_size=split)
self.X_test = X_test
self.y_test = y_test
self.X_train = X_train
self.y_train = y_train 完整的数据预处理类如下:
class DataPrep(object):
def __init__(self):
self._performance = {}
self._predictions = {}
self._models = {}
feature_engineering = FeatureEngineering()
feature_engineering.engineer(['bmi', 'age'], 'charges', True, False)
self.data = feature_engineering.data
self.target = feature_engineering.target
def dataprep(self, model_name, model_category, category_value, split):
self.split = split
self.model_category = model_category
self.category_value = category_value
if category_value not in self._predictions:
self._predictions[category_value]= {}
if category_value not in self._performance:
self._performance[category_value] = {}
if category_value not in self._models:
self._models[category_value] = {}
self.data_cat = self.data[self.data[model_category] == category_value]
self.X = self.data_cat[features]
self.y = self.data_cat[self.target]
X_train, X_test, y_train, y_test = train_test_split(self.X, self.y, random_state=42, test_size=split)
self.X_test = X_test
self.y_test = y_test
self.X_train = X_train
self.y_train = y_train 最后,我们定义一个模型训练类,允许我们访问准备好的数据,训练我们的模型,生成预测并计算性能:
class ModelTraining(object):
def __init__(self, dataprep):
self._models = dataprep._models
self._predictions = dataprep._predictions
self._performance = dataprep._performance
def get_data(self, training_data, category_value):
self.X_train, self.X_test, self.y_train, self.y_test = training_data
self.category_value = category_value
def fit(self, model_name, n_estimators=10, max_depth=10):
if model_name == 'lr':
self.model = LinearRegression()
self.model.fit(self.X_train, self.y_train)
elif model_name == 'rf':
self.model = RandomForestRegressor(n_estimators=n_estimators, max_depth = max_depth, random_state=42)
self.model.fit(self.X_train, self.y_train)
self._models[self.category_value] = self.model
def predict(self, model_name):
self._predictions[self.category_value][model_name] = self._models[self.category_value].predict(self.X_test)
def validate(self, model_name):
self._performance[self.category_value][model_name] = mean_absolute_error(self._predictions[self.category_value][model_name], self.y_test)我们现在可以用我们的类层次结构进行一系列实验。例如,我们可以建立一个随机森林模型,仅对应于女性患者的数据进行训练:
dataprep = DataPrep()
dataprep.dataprep('rf', 'sex', 'female', 0.2)
training_data = dataprep.X_train, dataprep.X_test, dataprep.y_train, dataprep.y_test
category_value = dataprep.category_value
modeltraining = ModelTraining(dataprep)
modeltraining.get_data(training_data, category_value)
modeltraining.fit('rf', 200, 200)
modeltraining.predict('rf')
modeltraining.validate('rf')
print(modeltraining._performance)
{'female': {'rf': 8466.305049427323}}我们还可以建立其线性回归模型,将模型性能添加到现有性能字典中:
dataprep.dataprep('lr', 'sex', 'female', 0.2)
training_data = dataprep.X_train, dataprep.X_test, dataprep.y_train, dataprep.y_test
category_value = dataprep.category_value
modeltraining = ModelTraining(dataprep)
modeltraining.get_data(training_data, category_value)
modeltraining.fit('lr')
modeltraining.predict('lr')
modeltraining.validate('lr')
print(modeltraining._performance)
{'female': {'rf': 8466.305049427323, 'lr': 8034.741428854192}}男性患者也一样。以下是线性回归的结果:
dataprep.dataprep('lr', 'sex', 'female', 0.2)
training_data = dataprep.X_train, dataprep.X_test, dataprep.y_train, dataprep.y_test
category_value = dataprep.category_value
modeltraining = ModelTraining(dataprep)
modeltraining.get_data(training_data, category_value)
modeltraining.fit('lr')
modeltraining.predict('lr')
modeltraining.validate('lr')
print(modeltraining._performance)
{'female': {'rf': 8466.305049427323, 'lr': 8034.741428854192}}随机森林:
dataprep.dataprep('rf', 'sex', 'male', 0.2)
training_data = dataprep.X_train, dataprep.X_test, dataprep.y_train, dataprep.y_test
category_value = dataprep.category_value
modeltraining = ModelTraining(dataprep)
modeltraining.get_data(training_data, category_value)
modeltraining.fit('rf', 200, 200)
modeltraining.predict('rf')
modeltraining.validate('rf')
print(modeltraining._performance)
{'female': {'rf': 8466.305049427323, 'lr': 8034.741428854192}, 'male': {'lr': 9583.028554450382, 'rf': 10609.717391992232}}我们看到,字典中包含了几个实验及其相应的模型类型、类别级别和模型性能值。
(这篇文章中使用的代码可以在GitHub上找到)
结语
在本文中,我们讨论了如何使用特定编程来简化数据科学工作流程的各个部分。首先,我们定义了单个机器学习工作流类,它支持简单的EDA、数据预处理、模型训练和验证。然后我们看到,当我们向类添加功能时,对类实例的方法调用变得难以阅读。
为了使阅读变得简单,我们设计了一个由一系列助手类组成的类层次结构,每个助手类对应于机器学习工作流中的一个步骤。助手类有助于提高可读性和可维护性,如果允许的话,你大可以尝试一番!
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Sadrach Pierre, Ph.D.
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/mastering-data-science-workflows-with-helper-classes-1134afbd0600





