
机器学习面试,你必须知道这些数学知识
机器学习中有很多方程式,为了准备面试,你至少需要知道本文所包含的内容。
在开始这篇文章之前,我应该先介绍一下目标受众——本篇文章是针对那些对机器学习工程面试感兴趣的人,而不是研究科学家(或类似职位,比如数据科学家)。原因是,研究科学家的面试往往非常重理论(数据科学则偏向统计学知识),候选人需要了解更多的方程式,而机器学起工程师(MLE)面试则更注重工程学知识,你需要非常了解机器学习,但不需要达到专家水平。
如果你跟我一样,在为MLE的面试做准备时,你会阅读书籍和博客,做笔记。一段时间后,你意识到这些资料中都有很多数学方程,你开始好奇,到底哪些对你的面试很重要。但是因为你不确定,所以你只有一个不落地研究了:(
好消息是,MLE 面试和其他面试相比的优势在于,面试官提出的问题中基本上不会要求你明确给出方程式,甚至推导方程式(需要注意的是:有些初创公司的面试过程还不够正式化,所以面试内容主要还是取决于面试官)。但是,在回答机器学习问题时,我们需要注意并使用其中一些方程式。
通常,你会使用这些方程式来支持你的回答。例如,如果面试官问,如何减少过拟合,你会提到 L1(lasso)和 L2(ridge)正则化,此时还应该补充说, L2 添加了一个惩罚项,为损失函数的系数的平方,L1也类似。在这种情况下,我们不会明确地写出方程式,但我们会让面试官知道我们是了解这些知识的,并且会在回答问题时使用它们。
我列出了一份总结性的方程式及清单,在准备 MLE 面试时你必须知道这些内容。该清单针对一般领域的 ML 工程师,对于特定领域,你还需要了解其他方程式。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Machine Learning知识点:机器学习里的聚类分析技巧
三个月如何搞定机器学习的数学原理?
研究了2000+笔记本,我们总结了最适合机器学习、数据科学和深度学习的电脑
评估机器学习算法的指标
损失函数(Loss Functions)
你应该熟知所有损失函数,因为当你谈论 ML 模型时,面试官会期待优秀的候选人可以在没有提示的情况下提到损失函数。
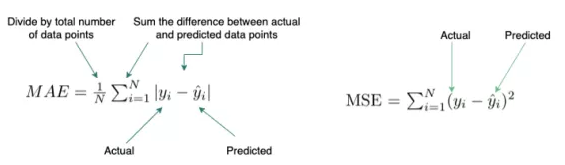
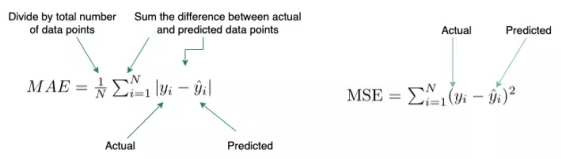
平均绝对误差 (MAE) / 均方误差 (MSE)
这些是用于回归模型的损失函数
对数损失函数(Log Loss)
针对二进制输出分类模型的损失函数
.png)
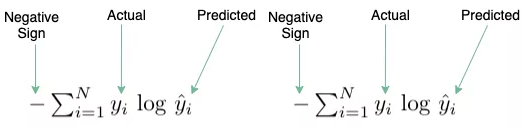
交叉熵损失函数(Cross Entropy Loss)
多输出分类模型的损失函数
铰链损失函数(Hinge Loss)
针对SVM 的损失函数
模型
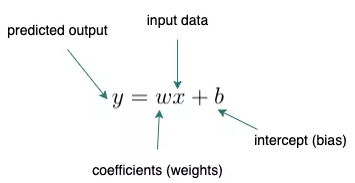
线性回归(Linear Regression)
尽管线性回归问题不像逻辑回归那样为人所知,但知道在什么情况下会遇到线性回归问题也很重要。线性回归是传统ML基本模型之一,其方程式非常简单。
逻辑回归(Logistic Regression)
逻辑回归在ML面试中经常出现,因为它通常是分类问题的基线模型,面试官可以使用过拟合和分类指标进行跟踪。
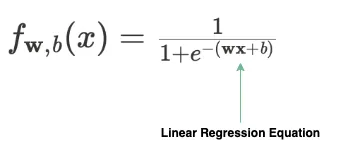
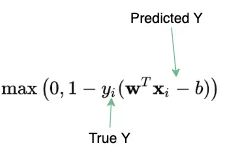
支持向量机(SVMs)
与线性回归一样,支持向量机并不经常出现在ML面试中。但是,了解 SVM 的成本函数的方程式,将有助于你理解超参数,超参数可用于控制误分类数量(这个问题经常出现在与SVM有关的问题中)。如果超参数为 0,则模型不允许出现任何误分类,反之,超参数值越大,允许的误分类越多。
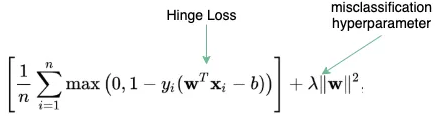
神经网络的前向传递(Forward Pass of Neural Networks)
神经网络经常出现在ML面试中,所以你至少要准备一个问题。候选人必须熟知前向传递方程,以便更好地理解要如何将激活函数、权重和输入结合在一起。

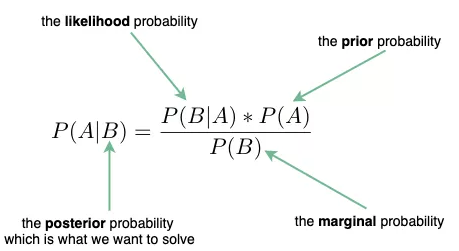
贝叶斯定理(Bayes Theorem)
这是机器学习中最常出现的方程。面试中出现的问题往往不是解决贝叶斯定理的问题——这些问题通常是针对数据科学家的——但有时你需要解释简单贝叶斯模型,而这个定理是核心。
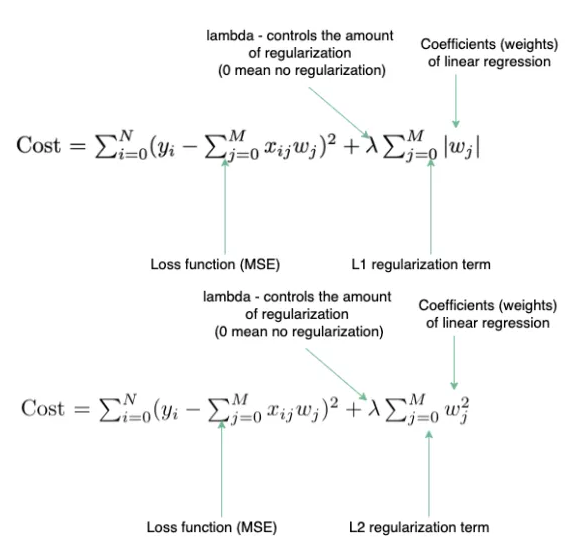
L1 和 L2 正则化(L1 and L2 Regularization)
了解这两个方程以及它们如何防止过拟合非常重要。过拟合问题经常出现在 ML 面试中。
决策树(Decision Tree)
决策树、随机森林、和增强树经常出现在 ML 面试中,你应该知道用于测量节点杂质的两个方程:
基尼系数(Gini Index)
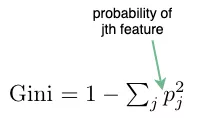
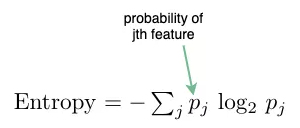
熵(Entropy)
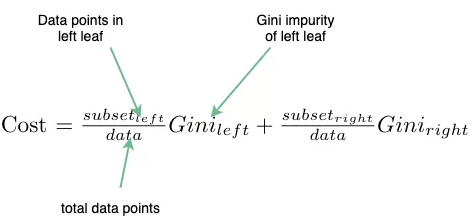
决策树的成本函数-因为编写成本函数非常简单,面试官很可能在ML编程问题中提出让你编写成本函数。
指标
在提到 ML 模型时,你需要知道如何进行评估,因此了解每个模型的指标非常重要。
分类指标(精确度、召回率、准确度、F1)
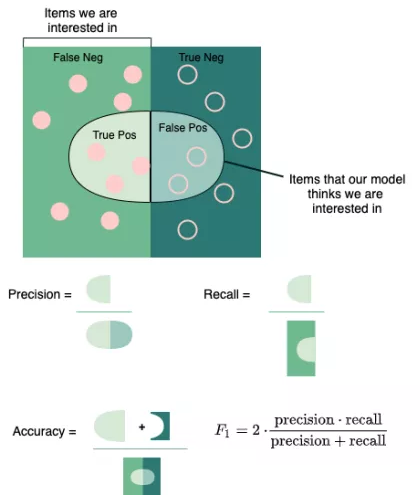
回归指标(平均绝对误差、均方误差)
其他一些指标:
- Normalized discounted cumulative gain(排名指标)
- Intersection over union(计算机视觉指标)
- Dice coefficient(计算机视觉指标)
- BLEU 分数(NLP 指标)
激活函数
如上文所述,神经网络经常出现在面试中,在回答涉及神经网络和其他ML模型的问题时,了解流行的激活函数也很有必要。

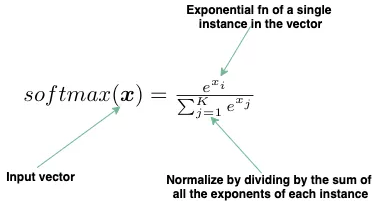
Softmax函数
距离函数(Distance Functions)
距离函数出现在ML面试的许多领域:比如k最近邻、k均值以及推荐系统。因此,你应该熟悉 3 个最受欢迎的距离函数:
余弦相似度(Cosine)
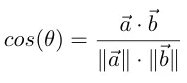
欧氏距离(Euclidean)
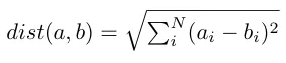
曼哈顿距离(Manhattan)
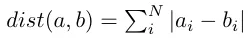
统计知识
虽然 MLE 面试中的统计问题没有数据科学家面试那么多,但你也要试着将这些方程用于数据分析问题。这类问题经常出现在面试中,因为你的工作中心就是处理数据。
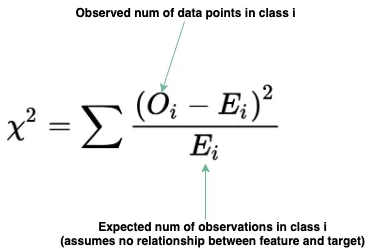
卡方(Chi Squared)
卡方检验用来确定某一类别特征的期望频率,与该特征的观察频率之间,是否存在统计学上显著的差异。
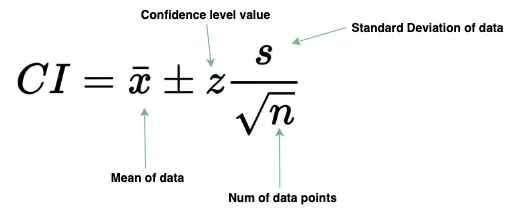
置信区间(Confidence Intervals)
该区间给出了估计区间包含感利息价值的概率。最常见的置信区间为 95%。
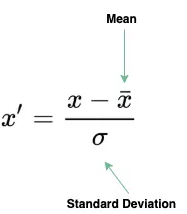
标准化(Standardization)
标准化是一种数据预处理技术,用于将数据围绕平均值进行缩放,以获得单位标准差。
归一化(Normalization)
归一化是一种数据预处理技术,用于在 0 和 1 之间缩放数据。
偏差-方差权衡方程(Bias-Variance Tradeoff Equation)
虽然你可能了解偏差-方差权衡的概念,但理解该偏差-方差权衡方程还可以帮你深层次理解这个概念,并在回答这个问题时提供更深层次的知识。
总结
机器学习是指训练计算机程序,以建立基于数据的统计模型的过程。 机器学习 (ML) 的目标是转换数据,并从数据中识别关键模式或获得关键见解。而数学是机器学习面试中的一大重点。为了练习,我们汇总了机器学习面试问题中的数学相关的函数和问题。这份ML最重要数学的指南会对大家的求职很有帮助。
原文作者:Stefan Hosein
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/math-you-need-to-succeed-in-ml-interviews-9e717d61f296



