
用合成数据创建机器学习欺诈模型
欺诈案件在任何行业都很常见,而且会造成巨大的财务损失。每个企业无论大小都会面临欺诈问题,无论他们喜欢与否,只要有人有恶意。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
一文了解机器学习中的F1分数(F1 Score)
机器学习中的文本分类是什么?
Ins 数据科学、机器学习及AI宝藏博主推荐
机器学习在安全领域撒过的美丽的谎言
为了缓解欺诈问题,机器学习欺诈检测研究已经做出了许多努力,但仍然没有完美的解决方案。这是可以理解的,因为每个企业都有不同的需求,数据也在不断发展。
即使没有完美的解决方案,也有一些方法可以改进模型。解决方案之一是使用合成数据。什么是合成数据(Synthetic Data),它如何帮助欺诈检测?让我们开始吧。
合成数据
合成数据是通过计算机技术创建的数据,在现实世界中并不存在。换句话说,我们可以将合成数据定义为未经直接收集而生成的数据。
合成数据在数据世界中并不是什么新鲜事。随着技术的进步,合成数据变得更加关键,并影响到各个行业。为什么会产生影响,让我们看看合成数据在数据科学领域的多种应用:
- 无需收集即可生成大量数据
- 创建反映真实情况的数据集
- 克服使用隐私数据
- 模拟尚未发生的情况
- 缓解数据不平衡
随着合成数据研究的进行,这些应用的研究也将继续下去。关键是合成数据有助于数据科学,也会对行业产生影响。
此外,可以根据数据的创建和存储方式对合成数据进行分类。分类如下:
- 完全合成数据:合成数据基于原始数据,但用户不包括任何原始数据。数据集仅包含合成数据,但与原始数据具有类似的属性。
- 部分合成数据:原始数据和合成数据在可变水平上的组合。如果我们想用合成变量替换某些变量,例如敏感数据,则通常使用这一类别。
- 混合合成数据:数据的创建来自真实数据和合成数据。变量之间的基本分布和关系是完整的,但数据集将包含原始数据和合成数据(不仅仅是变量级别)。
我们已经了解了合成数据及其实用性,但它如何帮助欺诈机器学习建模呢?我们可以看看欺诈数据集的典型案例。
欺诈建模
欺诈是在非法情况下获取利润的欺骗行为,每个企业都面临这个问题和潜在的损失。然而,企业中欺诈案件的数量本质上低于非欺诈案件。为什么?因为大多数人都是诚实的,如果情况发生逆转,生意就会毁于一旦。
欺诈预防数据科学项目的成功取决于两件事:业务战略和欺诈模型。
作为数据科学家,我们需要了解业务,但业务战略将是另一项责任。相反,我们需要专注于改进我们的欺诈模型。然而,开发一个欺诈模型有多难?
正如我前面提到的,欺诈案件很少发生,但每一个案件都可能造成大量损失。这意味着欺诈建模通常有我们所称的不平衡数据。
一般来说,如果使用不明确的特征来对目标进行分类,那么不平衡数据会导致我们的预测模型只会预测大多数情况发生的案例。这种情况会导致高准确率,但不具有精确率或召回率。
那么,合成数据如何与不平衡数据案例相关?研究表明,合成数据可以通过对少数群体数据进行过采样创建平衡的数据集来帮助缓解不平衡问题。例如,Dina等人(2022年)的一篇论文表明,与基于不平衡数据训练出的机器模型相比,CTGAN生成的合成数据的准确率提高了8%。
合成数据平衡最著名的策略是SMOTE,尽管它在复杂数据中优势并不明显。这就是为什么我们会尝试另一种数据合成方法——主要涉及GAN模型,因为已经证明它有助于提高机器性能。
虽然合成数据有其优势,但请注意,研究仍然是新的,在将合成数据应用于建模时,请注意如下缺点:
- 随着数据复杂性的增加,生成的合成数据可能无法代表真实世界的人口。这将导致模型学习错误的见解,并产生错误的预测。
- 合成数据的质量取决于用于生成数据的数据集。错误的原始数据会产生错误的合成数据,从而导致模型的输出不准确。
如果你已经了解在建模中使用合成数据的风险和缺点,那么让我们看看不平衡的数据是如何帮助欺诈检测的。
创建欺诈检测模型
本例中,我使用Shivam Bansal在Kaggle中提供的车辆保险索赔欺诈检测数据集(许可证:CC0:公共域)。数据集检测哪些客户会对其索赔进行欺诈方面存在业务问题。
为了简化操作,我会使用Pandas Profiling来进行EDA。让我们从探索数据集开始,看看总体特征和不平衡的数据。
import pandas as pd
from pandas_profiling import ProfileReportprofile = ProfileReport(df)profile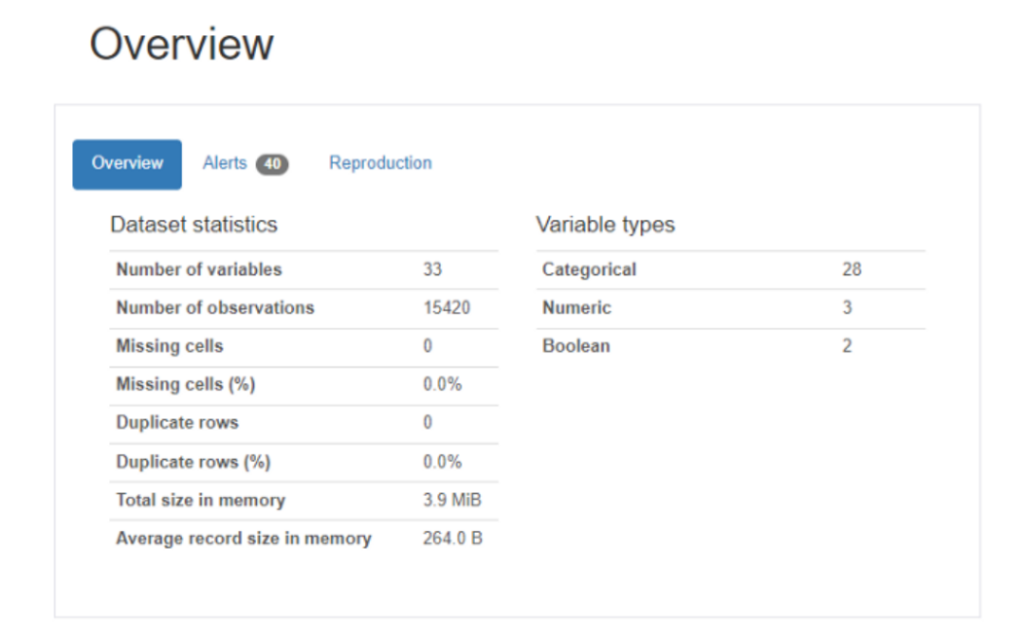
总体而言,我们有大约33个变量和15420个观察值,其中大多数数据属于分类类型。没有缺失数据,所以我们不需要做任何缺失数据处理。让我们检查变量目标以查看分布。
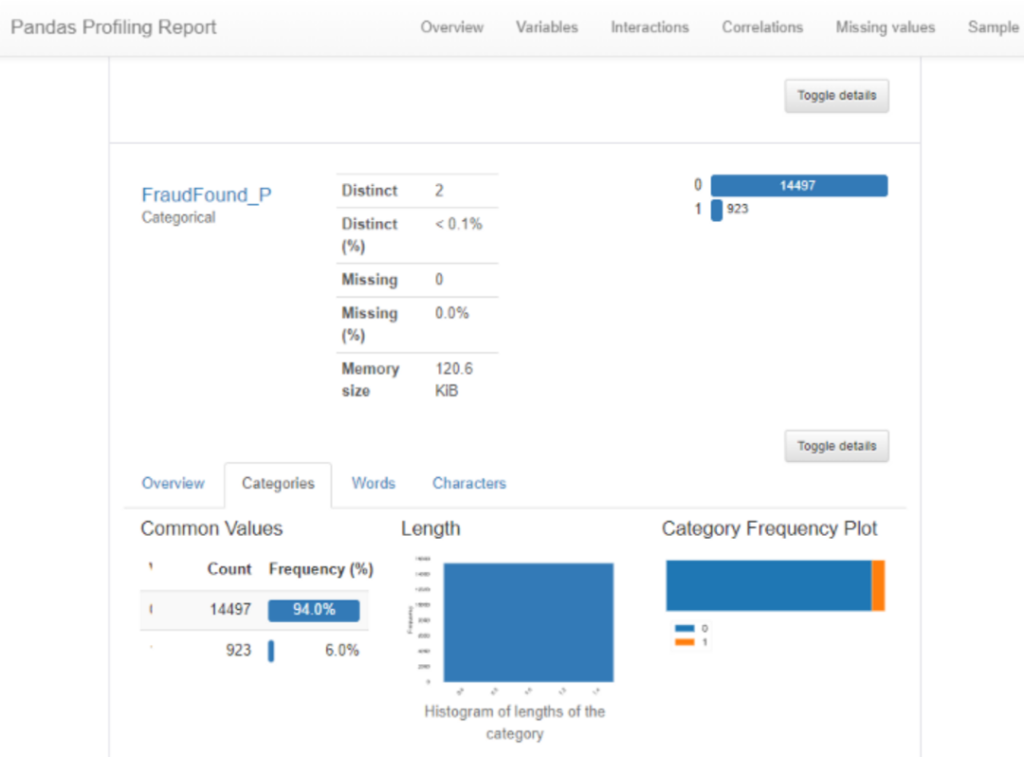
从上面的总结中我们可以看到,目标“FraudFound”严重失衡。与非欺诈数据相比,只有6%的数据或923个观察结果是欺诈性的。
下一部分,让我们构建一个分类器模型来预测车辆保险欺诈。为了训练结果,我不会使用所有的数据集,也不会做一些分类编码。
#Selecting some data I assume would be useful
df = df[['AccidentArea', 'Sex', 'MaritalStatus', 'Age', 'Fault', 'PolicyType', 'VehicleCategory', 'VehiclePrice', 'Deductible', 'DriverRating','Days_Policy_Accident','Days_Policy_Claim','PastNumberOfClaims', 'AgeOfVehicle','BasePolicy', 'FraudFound_P']]df = pd.get_dummies(df, columns = df.select_dtypes('object').columns, drop_first = True)在数据清理之后,我将尝试创建训练数据来训练模型。
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import classification_reportX_train, X_test, y_train, y_test = train_test_split(df.drop('FraudFound_P',axis = 1), df['FraudFound_P'], train_size = 0.7,stratify = df['FraudFound_P'], random_state = 100)model = RandomForestClassifier(random_state = 100)
model.fit(X_train, y_train)使用Random Forest模型,我会尝试初步评估欺诈模型。
y_pred = model.predict(X_test)print(classification_report(y_test, y_pred))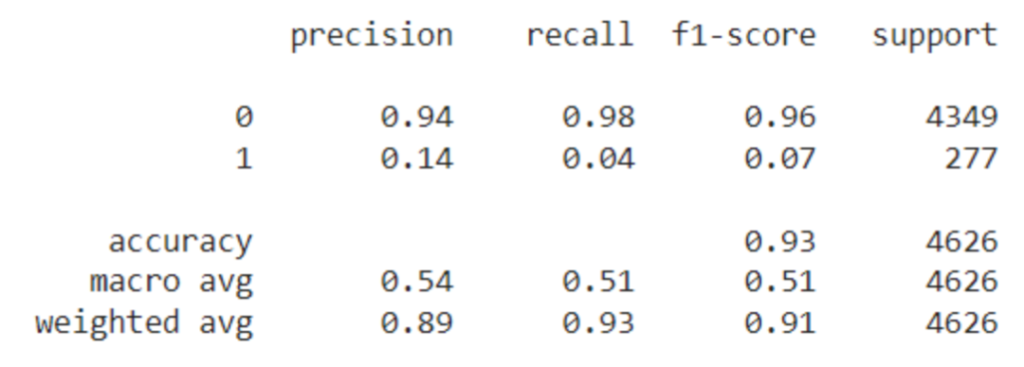
从上面的结果可以看出,大多数预测都会预测非欺诈案件。我们已经预料到了这种情况,因此我们将尝试使用其他合成数据来提高模型性能。
首先,我们需要安装软件包。我会使用Ydata-synthetic包中的模型来简化操作。对于这个示例,我将使用Conditional Wassertein GAN with Gradient Penalty(CWGAN-GP)模型来生成合成数据。该模型有助于平衡数据集。
pip install ydata-synthetic安装完成后,我将为CWGAN-GP模型设置数据集以进行训练。此外,我还将根据我们拆分的训练数据创建合成数据。我为什么要这样做?因为我想通过在测试数据集中包含的合成数据来避免数据泄漏。
X_train_synth = X_train.copy()
X_train_synth['FraudFound_P']= y_train由于我只想为少数数据训练合成器,所以我会创建一个只包含欺诈案例的数据集。
X_train_synth_min = X_train_synth[X_train_synth['FraudFound_P'] == 1].copy()下一步是创建CWGAN-GP模型。在训练模型之前,让我们用参数初始化模型。
from ydata_synthetic.synthesizers.regular import CWGANGP
from ydata_synthetic.synthesizers import ModelParameters, TrainParameters#Model selection
synth_model = CWGANGP#Setting the parameters of the CWGANGP model, you could experiment with thisnoise_dim = 61
dim = 128
batch_size = 128
log_step = 100
epochs = 200
learning_rate = 5e-4
beta_1 = 0.5
beta_2 = 0.9
models_dir = './cache'#Setting the parametersgan_args = ModelParameters(batch_size=batch_size, lr=learning_rate, betas=(beta_1, beta_2),noise_dim=noise_dim,layers_dim=dim)train_args = TrainParameters(epochs=epochs, sample_interval=log_step)#Initiate the modelsynthesizer = synth_model(gan_args, n_critic =10, n_clasess = 10)随着参数和模型的初始化,我们准备对CWGAN-GP模型进行训练。如果在本地笔记本电脑上训练很难,请尝试进入谷歌Colab,以提供更多算力。
我们训练模型时必须确定哪些列是数值列和分类列。对于这个示例,我将把所有列都视为数字列。
synthesizer.train(data = X_train_synth_min, train_arguments = train_args, num_cols = list(X_train_synth_min.drop('FraudFound_P', axis = 1).columns), cat_cols = [], label_col = 'FraudFound_P')由于我们的欺诈数据很小,训练不应花费太多时间(除非您增加参数)。然后,我们使用经过训练的模型合成数据。例如,我可以从模型中合成100000个样本数据。
import numpy as npsynth_data = synthesizer.sample(condition = np.array([1]),n_samples = 100000)
随着数据的合成,我将用合成的数据填充我们之前的训练数据,以平衡数据集。
#Sampling the data to fill the training data
minority_synth_data = synth_data[synth_data['FraudFound_P']==1].sample(9502)X_train_synth_true = pd.concat([X_train_synth, minority_synth_data]).reset_index(drop = True).copy()X_train_synth_true['FraudFound_P'].value_counts()
从上面的例子中可以看出,我们可以用当前的合成数据来处理以前的不平衡数据集。让我们看看如何使用平衡数据训练模型。
model.fit(X_train_synth_true.drop('FraudFound_P', axis =1), X_train_synth_true['FraudFound_P'])y_pred = model.predict(X_test)print(classification_report(y_test, y_pred))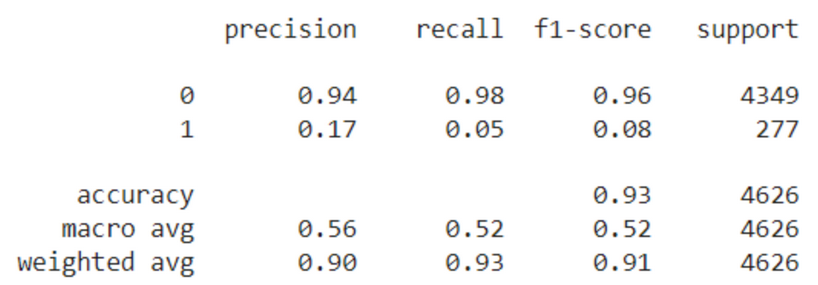
与原始数据集相比,平衡数据集的模型效果略有提高。这并没有增加多少,因为我们没有正确选择特征并用另一个模型进行试验。然而,这个简单的例子证明,综合数据可以帮助提高欺诈建模性能。
结论
欺诈是企业中常见的问题,需要采取适当的措施来处理。我们可以采取的措施之一是使用欺诈模型正确预测欺诈案件。然而,欺诈建模往往因数据不平衡问题而停滞不前。
各种研究证明,合成数据可以通过平衡训练数据来缓解不平衡问题,从而提高模型性能。
从我们创建欺诈模型的简单实验来看,合成数据的平衡数据集的性能略优于原始数据集。这证明,合成数据可以帮助欺诈建模。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Cornellius Yudha
翻译作者:Jie
美工编辑:过儿
校对审稿:过儿
原文链接:https://towardsdatascience.com/synthetic-data-to-help-fraud-machine-learning-modelling-c28cdf04e12a





