
8种防止过拟合的技术
当模型在训练集上表现良好但在测试集表现不佳时,就会发生过拟合。过拟合是机器学习中一个非常常见的问题,并且有大量文献致力于研究防止过拟合的方法。如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
一文了解机器学习中的F1分数(F1 Score)
机器学习中的文本分类是什么?
Ins 数据科学、机器学习及AI宝藏博主推荐
机器学习在安全领域撒过的美丽的谎言
在本文中,将描述八种简单的方法来防止过拟合,通过在每种方法中只对数据、模型或学习算法进行改进来缓解过拟合。
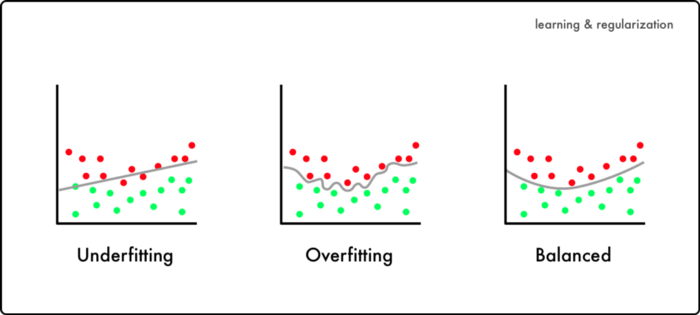
✦++ 目录
- Hold-out
- 交叉验证
- 数据增强
- 特征选择
- L1 / L2正则化
- 移除层/每层的神经元数
- Dropout
- 早停法(Early Stopping)
✦++ 1. Hold-out(数据)
我们可以简单地将数据集分成两组:训练集和测试集,而不是使用所有的数据进行训练。训练集和测试集常见的拆分比例是80%和20%。我们训练模型直到它在训练集和测试集上都表现良好。这表明了良好的泛化能力,因为测试集代表了未用于训练的未见数据。然而,这种方法需要足够大的数据集才能在拆分后进行训练。
✦++ 2. 交叉验证(数据)
我们可以将数据集分成k个组(k 折交叉验证)。让其中一组作为测试集(请参阅hold-out说明),其他组作为训练集,并重复此过程,直到每个单独的组都被用作测试集(例如,k次重复)。与hold-out不同,交叉验证允许所有数据都用于训练,但也比hold-out计算成本高。

✦++ 3.数据增强(数据)
更大的数据集将减少过拟合。如果我们无法收集更多的数据并且受限于当前集中的数据,我们可以应用数据增强来人为地增加数据集的大小。例如,如果我们正在训练图像分类,我们可以对图像数据集执行各种图像转换(例如,翻转、旋转、缩放、移动)。

✦++ 4. 特征选择(数据)
如果我们只有有限数量的训练样本,每个都有大量的特征,我们应该只选择最重要的特征进行训练,这样我们的模型就不需要学习这么多的特征,而且还会导致过拟合。我们可以简单地测试不同的特征,为这些特征训练单独的模型,并评估模型效果,或者使用各种常用的特征选择方法之一。
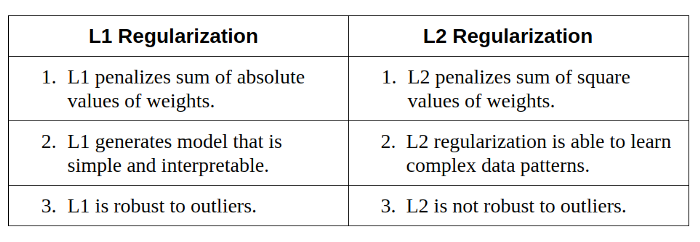
✦++ 5. L1/L2正则化(学习算法)
过于复杂的网络学习模型的技术可能会导致过拟合,而正则化可以限制这种过拟合。在L1或L2正则化中,我们可以在成本函数上添加一个惩罚项,以将估计的系数推向零(而不是取更多的极值)。L2正则化允许权重衰减到零但不允许为零,而L1正则化允许权重衰减到零。
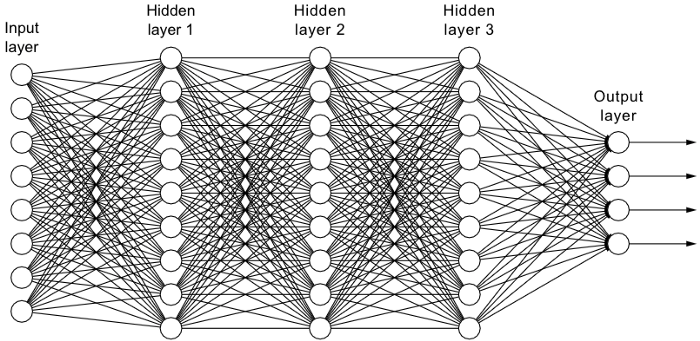
✦++ 6. 移除层数/每层的神经元数(模型)
如L1或L2正则化中所述,过于复杂的模型可能更容易过拟合。因此,我们可以直接通过移除层和减小模型的大小来降低模型的复杂度。我们可以通过减少全连接层中的神经元数量进一步降低复杂性。我们应该有一个复杂的模型,能够充分平衡欠拟合和过拟合。
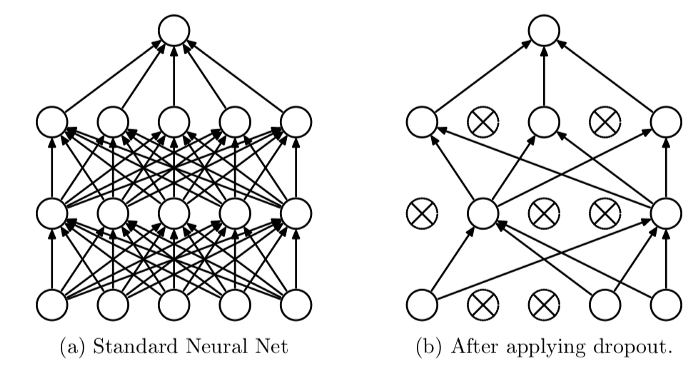
✦++ 7. Dropout(模型)
通过将dropout(一种正则化形式)应用于我们的层,我们忽略了具有设定概率的网络神经元的子集。使用dropout可以减少神经元之间相互依赖的学习,这可能导致过拟合。然而由于dropout,模型肯能会需要更多的epoch才能收敛。
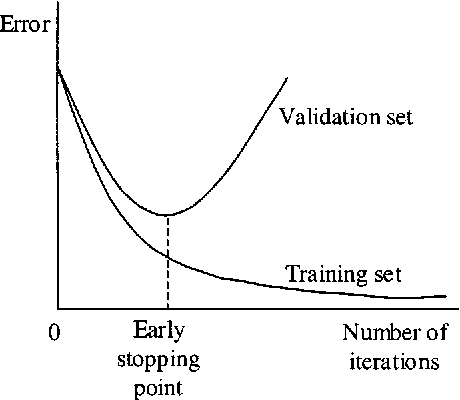
✦++ 8. 早停法(Early Stopping模型)
首先我们可以对任意数量的epoch训练我们的模型,并绘制验证损失图(例如,使用hold-out)。一旦验证损失开始减少(例如,停止减少而是开始增加),停止训练并保存当前模型。我们可以通过监控损失图或设置提前停止触发器来实现这一点。保存的模型将是不同epoch训练值之间泛化的最佳模型。
你已经到了文章的结尾!希望你现在拥有一个防止过拟合的方法工具箱。
感谢阅读,你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Rohan
翻译作者:明慧
美工编辑:过儿
校对审稿:过儿
原文链接:https://medium.com/@rohan5076/8-simple-techniques-to-prevent-overfitting-f11b74086b21





