
5分钟搞懂Kaggle的夺牌秘籍是什么?
众所周知,kaggle现在是全球最大、最活跃而且也是最具影响力的数据科学社区。目前,kaggle上的注册用户已经接近两百万,参与排名的用户也已经接近十万。要知道,所谓参与排名是一个很苛刻的条件哦,至少要参加过 kaggle 比赛,获得过可圈可点的成绩,或者在论坛上经常发言,曾经审过 kaggle 上的 kernel 等等。而数据科学又是近年来的新兴行业,从业者尚且不多,十万+的活跃用户已经足以说明它炙手可热的程度了。
打kaggle比赛都需要哪些操作?
Feature Engineering
所谓特征工程,是指对重要特征的筛选提取等一系列操作过程。业界广泛承认,特征工程是整个kaggle比赛的灵魂。这句话也适用于广义的数据挖掘等工业界的项目。对一个数据集的分析过程而言,80%以上的时间都花在特征工程上面。
在目前正热门的autoML研究中,电脑自动选择算法和自动调参的能力都已经和人工操作的效果相差不大,只有特征工程的能力还和人相去甚远。所以,Feature engineering是重中之重鸭!(不然等计算机成熟了,你以为偌大的职场还有你的容身之地么?嘻嘻。)
举个简单的例子, 数据科学顶会KDD每年都会举办一个数据科学竞赛,2018年这个比赛的题目是预测北京和伦敦第二天的空气质量。都是实时预测,没有任何掺假的数据。此次比赛的金牌团队的思路就特别新颖,他们根据地理位置,选择了八个方向(东西南北、东北、西南、东南、西北) 把各个方向的数据分别收集到一起。因为他们相信,空气质量与风向有相关性。然后再在此基础上,对每个方向的数据进行特征工程。思路清晰,方向正确,怎么能不优秀呢?
Model Tuning
模型调优是很考验我们基本功的一个地方。因为这需要我们对模型的原理,每个参数的意义和调参对模型的影响都有深入的了解。拿最简单的 linear regression 来说,L1和L2 的惩罚项各自有什么样的作用,如果初步分析的结果不理想,是该调整L1还是L2,调大还是调小,是增大还是减小overfitting的程度呢?这些都需要扎实的拟合基础和一定量的实践经验。
虽然现在有很多好用的自动调优工具,但是好用≠用好
如何用好工具,还是要靠大家的基本功;
Model Ensemble
虽然模型集成在工业界还没有很多落地应用,但它在kaggle里用的比较多。一般来说,到了比赛后半程,大家就开始比拼各种模型的集成套路(stacking,blending)。如果能熟练掌握模型集成的套路,基本可以保证在比赛中可以拿到一个体面的排名。
Think out of Box
然而,随着常见套路的普及,仅仅靠套路,已经无法得到命题人的芳心了。兵法曰:以正合,以奇胜。普通的战术用完了,就要琢磨些新鲜的。还是要靠对具体问题的独特理解,要么有独特的构思,要么有独特的模型架构,才能做 kaggle 比赛的大鱼缸里闪闪发光的 golden fish。

首先来了解一下这一坨躺着等待被分析的数据。我们可以看到,除了训练集和测试集,还提供了历史交易记录、新交易记录和商家信息。所以,如何将交易记录聚合到对应的card ID上,是解决这个问题的关键点之一。
通过分析target value可以发现,存在两千多个小于-30的异常值,我们要求的RMSE主要就来源于这些异常值。所以,探究出target值背后的商业意义,就成为了破解这个谜题的关键。通过膜拜大佬们的分析思路,我们才知道,这个target其实是一个比值,是将来消费与过去消费的比值经过scaling之后得到的结果。(吃惊)
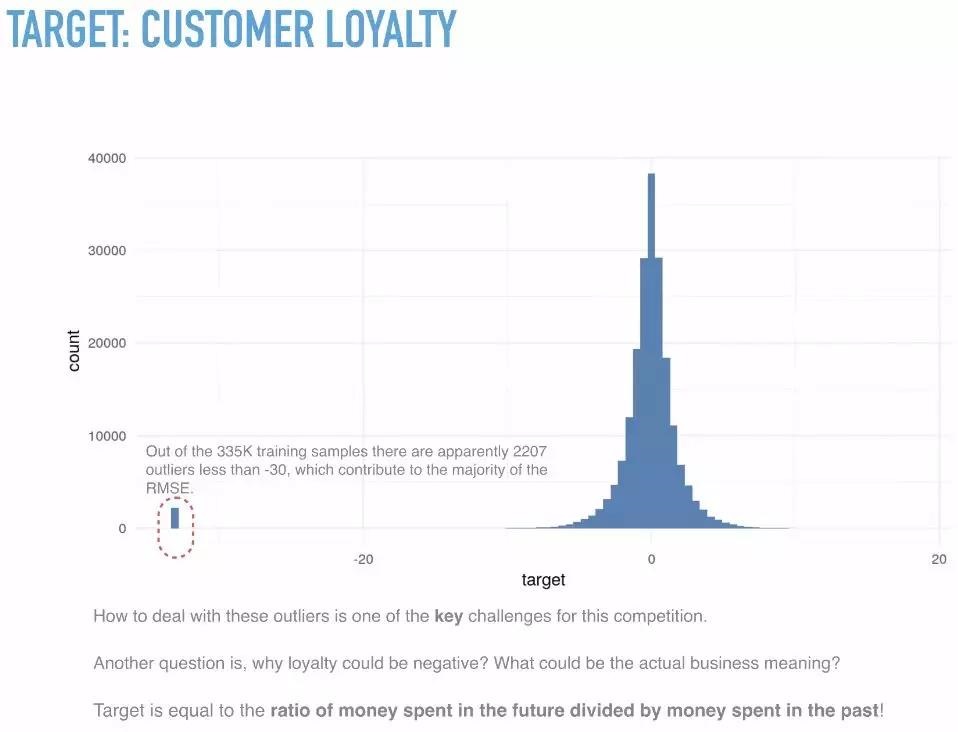
对数据的特点心中有数之后,我们就可以进行数据的聚合了。
Numerical Data Aggregation
对于numerical data,传统的聚合方式通常是根据card ID分组,然后对各组求和、求平均值、最大值、最小值等。
除此之外呢,我们还有更高级的,那就是使用数据透视表创建新feature。
在进行探索性分析的时候,我们通常会尽可能的创造feature,反正之后会通过feature selection的方法选择我们需要的feature。
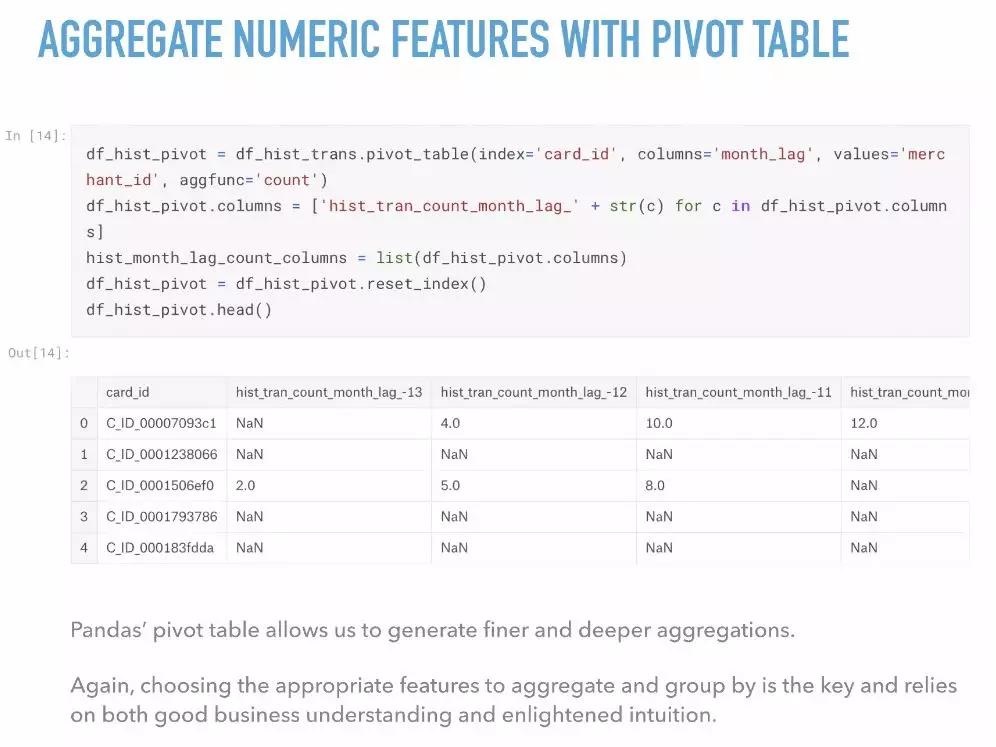
Categorical Data Aggregation
对Numerical Data的聚合方法相对而言容易想到,那么Categorical Data通常如何聚合呢?
说出来你可能不太信,现在大家都在使用NLP的技术进行文本数据的聚合了,比如Token-Count,TF-IDF甚至Word Embedding。
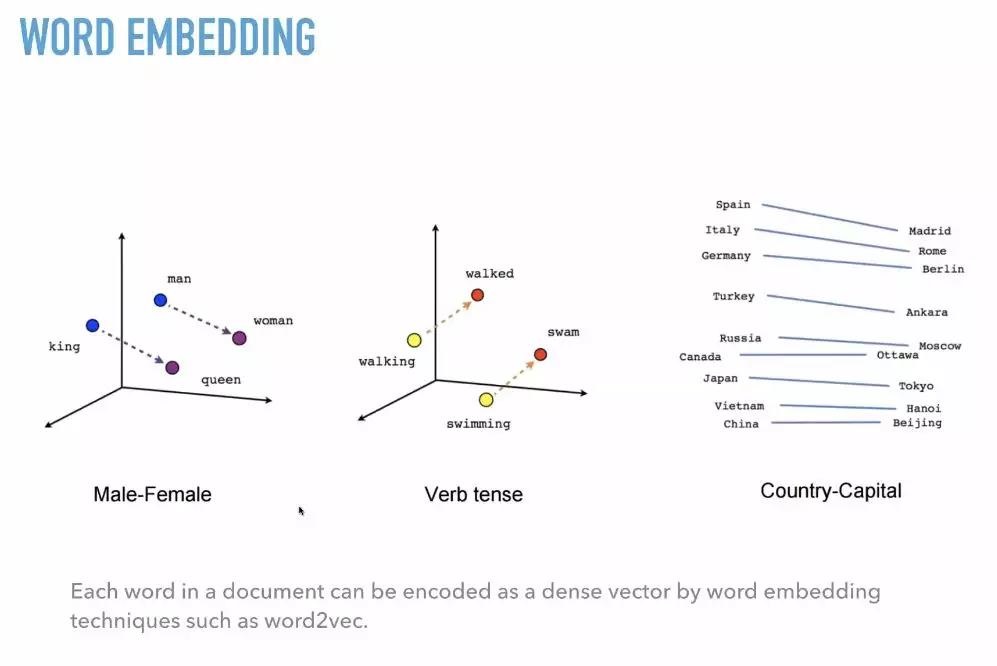
有没有觉得自己稍微有些跟不上时代?我们这就让你开开眼界。基本的Token-Count和TF-IDF方法大家肯定已经不陌生了,我们就来了解一下Word Embedding。
所谓Word Embedding,就是通过计算两点之间的距离,将每一个词转换成一个词向量。比如,我们可以发现man与woman的距离和King与queen的距离差不多,那么在我们不知道queen的时候,就可以用其他向量来代替。
具体在Elo这个kaggle比赛中如何使用NLP技术呢?看下图让你一目了然。

这里将每一个card ID对应的merchant ID拼接起来,创建了一个新的feature。这波操作强势之处在于,它进行了有效的聚合,保留了所有的原始数据,避免了数据的损失。
比赛的结果证明,这个方法的效果也是顶呱呱的,排名比较靠前的众多grandmasters都心照不宣地采用了这个技巧。





