
数据的特征选择技术
“数据素养包括阅读,使用,分析数据和与数据争论的能力”
——JordanMorrow,Qlik
特征选择的含义是从数据集中选择信息量最大的特征。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
如何成为全栈数据科学家?
成为高效数据科学家需要做的五步数据科学项目生命周期
大部分数据科学课程没有教给你的内容
数据科学面试中你应该知道的10个高级SQL概念
当数据集非常庞大时,我们很难建立模型。庞大的数据集需要大量的时间和强大的计算能力来工作,它们已然耗尽了模型所需要的一切。特征选择是一种方法,我们可以只选择重要或最有贡献的特征进行训练,同时所需的代价非常小或几乎不损失精度。但是,很多人误解了特征选择和特征提取的概念。
两者的基本区别在于,在特征选择中,你使用特征的组合或子集来获得最大的性能和准确性,而在特征提取中,我们根据数据集或特征的方差和其他因素从现有的特征中创建一组新特征。
在黑暗中选择特征是一件非常复杂的事情,就如早上我从抽屉里挑了两只袜子,虽然天还很黑,但这不重要,对吧?毕竟,它们的尺寸是一样的…一样的!?!——正如大数据时代的出现代表了人口统计事业的终结(也就是说,我们的模型不应该基于有限的属性和特征选择,也不应该受到这些属性和特征的偏见)。
特征选择的用途:
- 更快地训练算法
- 提高效率
- 减少冗余
- 减少过拟合
- 领域理解
- 模型和数据的简单解释
两种方法:
- ML 算法中的启发式方法和评估
- Wrapper & filter methods
过滤方法(Filter methods)
Filter方法使用有关特征的精确排名信息。根据排名,排列特征,我们不需要重复使用机器学习算法。它的准确性比filter方法稍低,但我们可以在特征和准确性之间进行权衡。
过滤方法:相关过滤
相关性可以定义为两个实体之间的统计关系。在机器学习中,相关性是两个或多个特征或属性之间的关联,以检查彼此之间的关联程度。
如果两个特征高度相关,或都携带相同的信息,那么其中一个就是冗余的。
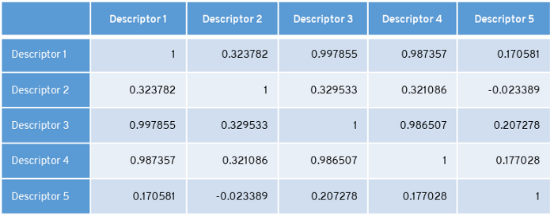
在表中,特征 1 、特征3以及特征4高度相关。我们选择删除方差较小的特征,即特征4。像这样,我们就减少了特征集。
在表中,descriptors 1和3、descriptors1和4、descriptors 3和4高度相关。删除方差较小的特征。这里,descriptors 4方差最小,descriptors 3方差最大。删除第四个descriptors。像这样,我们就减少了特征集。
互信息(Mutual Information)
互信息(MI)测量输入变量和目标变量之间的相关性。互信息应始终大于等于0。若MI等于0,即输入变量与目标变量无关。互信息越高则意味着两个变量更具依赖性。
信息增益(Information Gain)
信息增益计算数据平均信息量的减少。
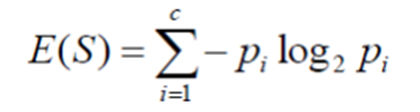
对于训练数据集,通过评估每个变量的信息增益,并选择使信息增益最大化的变量,即最小化熵。将数据分成组以进行有效分类的最大化信息增益,在目标变量中评估每个变量的增益。
特征选择的Chi-square方法:
计算每个非负特征和类之间的Chi-square统计量。统计检验应用于分类特征组,以利用其频率分布来评估它们之间相关性或关联性的可能性。χ 2 值越高,表示特征给出的信息越多。
Wrapper Method:正向选择
这是一种迭代方法,从模型中没有特征开始。在每次迭代中,我们都会不断添加最能改进模型的特征,直到添加的新变量不能改善模型的性能。
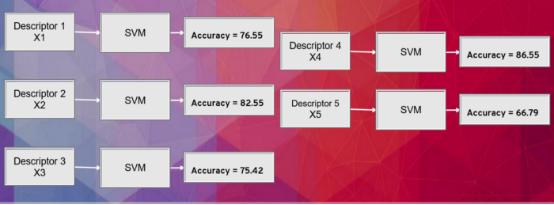
在这里,我们相信每个特征的准确性。而Descriptor 4 在特征组合中具有最高的准确度。
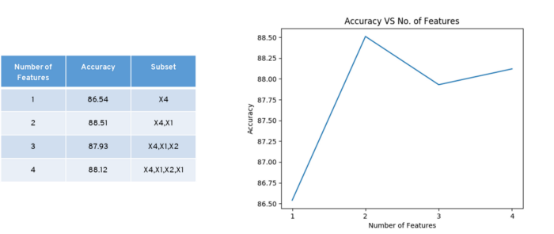
Descriptor 4、1和2与Descriptor的组合具有最高的准确度。
Wrapper Method:后向选择
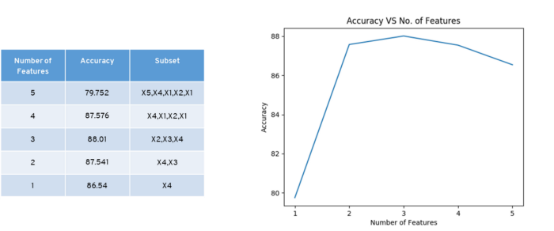
它从所有特征开始,并在每次迭代时删除最不重要的特征,从而提高模型的性能。我们重复这个过程,直到在特征的去除中没有观察到改进。精确度通过一次移除一个特征来计算,当我们移除 X5 时,我们得到了精确度的提高。
Embedded方法
Embedded方法结合了filter和wrapper方法的特性。它由具有自己内置特征选择方法的算法实现。Embedded方法中的特征选择与学习算法有着更深的联系,是分类本身的一部分。Embedded方法耗时少,不容易过拟合。举例来说,LASSO 回归和 RIDGE 回归具有内置的惩罚式函数以减少过度拟合。
✦++ 随机森林特征重要性
随机森林为特征选择提供了两种方法:
- 平均减少基尼系数:分类树的评估指标是基尼系数(Gini Impurity)或信息熵(information gain/entropy),回归树的评估指标是方差。训练树,计算加权基尼系数的减少。随机森林平均每个特征的基尼系数减少量,并根据该评估指标对特征进行排名。
- 平均降低准确率:对于随机森林中生长的每一棵树,找到 OOB 示例同时计算正确示例的投票数量。随机排列 OBB 示例中特征的值,并将这些情况放入树中。从未改变的 OOB 数据中的正确类的投票数中减去可变排列的 OOB 数据中的正确类的数。随机森林中所有树的此数量的平均值即为变量的原始重要性得分。
✦++ 特征选择的进化算法
大自然一直是灵感的源泉。在过去的几十年中,它引发了许多有效的计算工具和算法的发展,以解决具有挑战性的优化问题。进化算法用于特征选择。一些例子如下:
- Genetic Algorithm
- Ant Colony Optimization
- Simulated annealing
- Swarm Based Algorithms
- Black Hole Algorithm
进化算法的最大优点是不需要导数信息,我们可以在全局最优解附近采样一个子集。
我在著名的 analytics vidya 贷款预测问题上尝试了一个简单的特征选择方法,最终结果得到了改善。
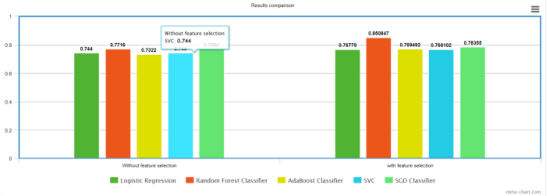
因此,像这样,你可以使用相同的模型来提高你的结果。有趣的是,特征选择目前由于其有效性而吸引了很多关注。
感谢阅读。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Chinmay Bhalerao
翻译作者:高佑兮
美工编辑:过儿
校对审稿:明慧
原文链接:https://medium.com/mlearning-ai/feature-selection-techniques-for-data-57f0eacd8fa8





