
成为高效数据科学家需要做的五步数据科学项目生命周期
如果你和我一样,那么检查清单和流程就是你的生命线。它们不仅能让你井井有条,还能帮你提前检查项目进展过程中可能出现的问题。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
数据科学家/分析师应该避免的5大编程错误
如何准备娱乐/游戏行业数据科学家面试
如何成为FAANG自驱式数据科学家的一员?
2022年,数据科学家文凭能让你赚多少钱?
由于有软件开发的教育背景,我对“软件开发生命周期”(SDLC)烂熟于心,我为自己准备了许多检查清单,确保我尽可能地编写最好的代码。
然而,当我开始在网上查阅大量的数据科学课程和证书时,我注意到有一个重要的东西被遗漏了:任何对项目生命周期的提及。直到我自己挖掘,我才知道数据科学确实有一个通用的生命周期,而且它足够灵活,可以进行修改,能适应每个团队或项目的需求。
熟悉数据科学项目生命周期是有好处的,原因有几个:
- 首先,它能让你成为一名高效的团队成员和数据科学家。只有当团队的每个成员都在一致地工作,或者当一个人完成了所有的任务,创建了一个有凝聚力的项目时,这个项目才会团结起来。
- 其次,你可能会得到一个关于数据科学项目生命周期的面试问题,你的回答可以让招聘人员了解到你有多么适合这个职位。
- 最后,也许不需要多说,数据科学项目生命周期有助于指导你的数据科学项目。它提供了一组循序渐进的里程碑,将帮助你计划和执行一个全面的项目,还将帮助你避免后续可能出现的任何潜在问题。
数据科学生命周期
首先需要注意的是,对于每个人来说,数据科学生命周期可能看起来有点不同。有几种不同的解释,尽管它们一般都类似于以下结构:
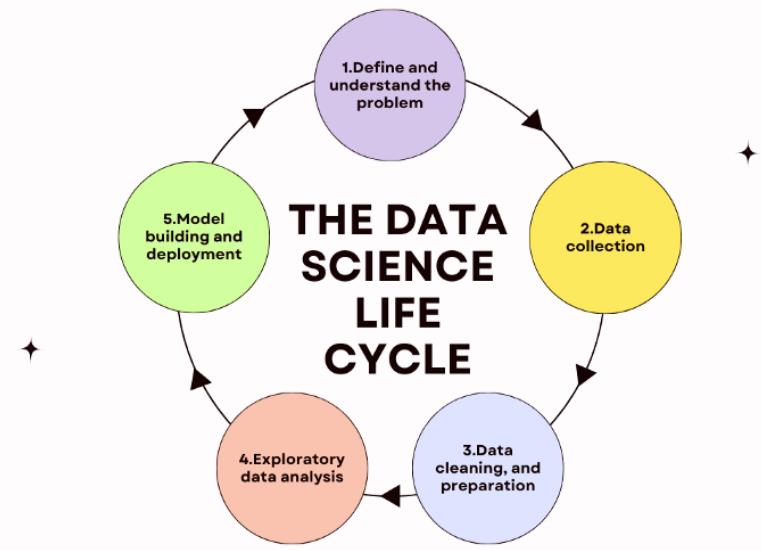
1 定义和理解问题
如果你不知道问题是什么,那肯定无法解决问题。
很多高管会去找他们的数据科学团队,声称有一个问题,数据科学团队需要解决这个问题,但却不知道如何清晰地表达这个问题,为什么需要解决这个问题,以及商业案例和技术案例之间有什么联系。
第一步是对问题或业务案例产生清晰的定义和理解,然后将其转化为具有可操作步骤和目标的数据科学问题。这需要与业务主管进行清晰、简明的沟通,并提出足够多的问题,以免结果产生矛盾。
应该问高管的一个关键问题是,解决这个问题将如何使公司(或其客户)受益,以及这个问题如何与公司的其他流程相适应。这不仅可以帮助你和你的团队确定提取哪些数据集,还可以帮助你运行分析类型和你要寻找的答案。
2 数据收集
如果你问了正确的问题,并且对你想要解决的问题有一个清晰的概念,你就应该做好准备为工作收集正确的数据。
数据收集可能会出现各种各样的问题。不是所有的公司都有优秀的数据集,也不是所有的公司都一定有适合这项工作的数据。为了确保你从一开始就有正确的数据,在这一步上你需要多花一些时间——再说一遍,这些项目需要大量的时间和精力,所以你不妨在第一次就把它做好。
数据集可能因为其他原因而不完整或错误,所以有额外的数据总是好的,以备不时之需。这样,不管数据的质量如何,你的整个项目都可以完成。这只需要你仔细的检查数据,确保你只使用了项目中最好的数据。
3 数据清理和准备
正如我在前一步所描述的,一旦你开始梳理原始数据,挑出不完整或错误的条目,收集更多的数据总是有价值的。
这个过程反复出现的话题是,你必须在第一次就把每一步都做好,减少重新来过的可能性。数据科学就是要聪明地工作,而不是努力地工作。这意味着,为了在流程的第五步中生产出正确的模型,你需要对计划使用的数据进行适当的清理和准备。重要的是要记住,你的模型可能会改变你公司的经营方式,这意味着你需要在开发模型的第一时间是正确的。
你需要注意的一些关键类型的错误数据包括格式错误的数据、损坏的数据、重复或空值、异常值,甚至丢失的数据。
这是数据科学项目生命周期中最长的一步,许多数据科学家会认为,它占据了项目的大部分时间。“20%的成果来自80%的工作”这句谚语在这里是对的。然而,糟糕的数据会产生糟糕的模型,这意味着你必须把时间花在现在,而不是在以后不得不纠正你的错误。
4 探索性数据分析
这可以说是数据科学项目生命周期中第一个“有趣”的步骤,因为你终于可以编写一些代码,并看到你苦心处理的数据想要告诉你什么。
探索性数据分析用于总结数据集的主要特征,通常通过开发数据可视化来完成。这些可视化将帮助你快速看到数据中的模式和发现异常。现在也是你进行假设检验或检查任何假设的时候了,你可能已经在你与公司高管的最初讨论中提出。你在这一阶段的发现将帮助你在以后开发不含假设或错误见解的模型。
在探索性数据分析过程中,你可能会发现自己使用的一些工具是聚类和降维技术、单变量可视化、双变量可视化和汇总统计、多元可视化、K-means聚类或线性回归。
需要注意的是,这可能是项目的最后一个阶段,这取决于你解决的业务问题。如果最初的问题是一个关于置信区间或标准偏差的简单问题,那么你的项目将随着一些可视化的生成而完成,这将有助于执行人员理解。然而,如果这个问题在本质上更具预测性,那么你将继续进行循环的最后一步:模型构建和部署。
5 模型构建与部署
现在,你已经到达了数据科学项目生命周期的最后一个“有趣”步骤。现在是时候把你的数据集分成训练集和测试集了,它们将被用来开发你的机器学习模型。
在这里,你将决定是否需要创建有监督的还是无监督的机器学习模型。有监督模型用于对看不见的数据进行分类,并通过训练数据中的“学习”模式来预测未来的趋势和结果。无监督模型用于发现数据内部的相似性,理解集合中不同数据点之间的关系,并执行额外的数据分析。例如,有监督模型可以用来保护公司不受垃圾邮件的影响,或者用来预测市场的变化。无监督模型可用于将客户划分到营销环境中,或根据客户以前的购买情况向客户推荐产品和服务。
你的模型可能需要在这里做一些调整,但如果你已经正确地完成了前面的所有步骤,应该没有任何必要的重大更改。
一旦你构建了一个满意的模型,它就会被部署到生产环境中。
最终的想法
虽然数据科学项目的生命周期很重要,但却很少有在线证书或课程教授。这在你所学的技术技能和如何在工作场所使用它们之间留下了巨大的脱节。
然而,通过学习上面描述的基本结构,你将成为一个更全面的数据科学家,你将能够回答在面试中任何生命周期问题,你将更好地帮助你的团队准备和交付一个重要的数据科学项目。你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Madison Hunter
翻译作者:过儿
美工编辑:过儿
校对审稿:明慧
原文链接:https://towardsdatascience.com/the-5-step-data-science-project-life-cycle-you-need-to-be-an-effective-data-scientist-9343684b96cf





