
Kumu的ML工程:将模型转化为产品
让我们面对事实吧,机器学习(ML)已经成为每个人都想参与的时髦热词,但并不是很多人都理解如何真正利用它。如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
用合成数据创建机器学习欺诈模型
一文了解机器学习中的F1分数(F1 Score)
机器学习中的文本分类是什么?
Ins 数据科学、机器学习及AI宝藏博主推荐
机器学习工程(MLE)是将软件工程和数据科学技能相结合的过程,目的是将机器学习模型转化为可用的产品。它包括训练模型并通过Inference endpoints公开这些模型,以及优化数据处理和数据检索,以实现生产的延迟性和稳定性。
在现实中,一些公司能够构建机器学习模型,但却无法充分利用其潜力。虽然数据团队已经想出了如何开发机器学习模型,但其中大多数都停留在Jupyter notebook等离线代码编辑器中运行这一现状中。这是因为在真实环境中部署模型需要的一系列技能,数据科学家们通常不具备,也因此,这些模型通常在研究或探索阶段,而不是作为实际的产品去使用。
Kumu 的 MLE
在 Kumu,我们有很多人工智能产品的用例——内容推荐、用户审核和视频分析。所有这些都可能为我们的产品带来巨大的商业价值。为了提取具体的商业价值,这些模型被用作其他产品团队可以轻松集成的 API 或 Inference endpoints。
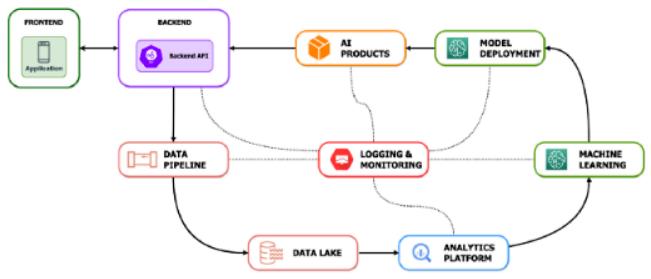
不过,在一个 ML 工程师对三个数据科学家的粗略比例之下,这些人工智能产品的推出规模存在明显的瓶颈。最重要的是,这些工作属于生产服务,因此需要大量时间来构建和维护其正常运行时间、延迟和效率。
Kumu早期的模型部署
作为标准数据科学工作流程的一部分,数据科学家通常会花费很长时间准备数据、进行探索性分析、设计特征和训练模型。根据模型的复杂程度,模型将在大约两周的模型开发后通过离线测试。之后,模型对象将移交给 MLE 团队进行部署。接着,预处理和后处理功能用于标准化进出模型服务的数据的错误处理和格式。完成后,使用开源模型部署框架BentoML将模型容器化,然后将其传递给 AWS SageMaker,以作为端点托管模型。
整个部署过程将需要一个 ML 工程师全身心投入1-2 周时间才能完成(但实际上,这从来没有发生过哈哈)。ML 工程师和数据科学家就如何检索输入特征、优化代码以及处理不同类型的模型框架(例如 TensorFlow、CatBoost、PyTorch)的复杂性进行反复讨论,这也将耗费大量时间。一般来说,我们能做到每两周生成3个模型,但所有这些模型的部署大约需要 3-4 周。对于数据科学家来说,长时间等待他们的模型得到部署是非常煎熬的,同时对于 ML 工程师来说,不断地部署模型和无休止的积压模型也是令人疲惫的。
显然,目前的部署进程实际上是不可持续的。我们需要重新评估我们是如何做事的,并去更聪明地进行工作,因为我们知道,在雇佣更多的数据科学家之前,雇佣更多的机器学习工程师只是一个权宜之计。我们在外部搜索,能很方便地找到由 Google 云架构中心发布的指南:MLOps:机器学习中的持续交付和自动化管道。不得不说,这很容易成为我们思考如何应对这一挑战的可靠参考点。
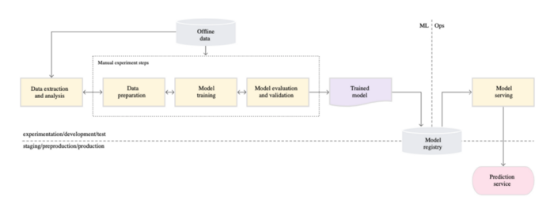
参考:MLOps Level 0 taken from Google Cloud Architecture Center MLOps: Continuous delivery and automation pipelines in machine learning
模板
我们意识到,为了最大限度地减少对 ML 工程师的依赖,我们需要找到一种简化部署过程的方法。最花时间的是考虑如何保存每个模型,而这取决于它使用的模型框架。经过多次手动部署后,我们能够创建一个模板来抽象化这一繁琐但重复的任务。这意味着任何数据科学家都可以使用任何支持模型的框架,将模型提交到模板,而输出的将是一个可用于生产的 API 端点。
import bentoml
from bentoml.io import JSON
# Your custom imports here!
from my_feature_store import FeatureStore
from aws import s3
from models import MyModel
# BentoML Custom Runnable
class CustomRunnable(bentoml.Runnable):
"""
Model Custom Runnable
Notes:
- A runnable is considered to be a K8s pod, which can scale to multiple instances
- You can create 1 or more Runnable classes inside this template
"""
SUPPORTED_RESOURCES = ("cpu",) # or "nvidia.com/gpu"
SUPPORTS_CPU_MULTI_THREADING = True
def __init__(self):
"""
A function for starting up a pod/service
Notes:
- Create connections to specific services (e.g. feature stores)
- Download and load model artifacts (e.g. network, weights, etc.)
- Initialize/instantiate 1 or more models (i.e. ensemble)
"""
# Examples
self.feature_store = FeatureStore()
model_artifact = s3.download("my_bucket", "model_path")
# Example initialization of a model instance (e.g. TF, PyTorch, etc.)
self.model = MyModel(model_artifact)
@bentoml.Runnable.method(batchable=False)
def predict(self, input_data):
"""
A function that continuously handles model requests
Notes:
- Input data is usually ready for model consumption (e.g. image urls that are ALREADY converted to arrays)
- As much as possible we don't want to do pre/post processing inside a "model runnable"
- We can create another runnables for pre/post processing functions
"""
# Example of retrieving features
features = self.feature_store.get_features(input_data["id"])
# Example of making an inference from a Model class instantiated during initialization (__init__())
return self.model.predict(features, input_data)
# Declare Runnable class/es here!
custom_runner = bentoml.Runner(CustomRunnable)
# preprocess_runner = bentoml.Runner(PreprocessRunnable)
svc = bentoml.Service("my_bentoml_service", runners=[custom_runner])
# Note: add preprocess_runner in the runners list if there's any
# Service logic here!
@svc.api(input=JSON(), output=JSON())
def predict(input_json):
"""
A function that handles API requests and consolidates outputs.
It is also the name of the REST API (e.g. http://modela.pi/predict)
Notes:
- All model input will be processed as JSON input via REST API endpoint
- The output of this function should be a JSON serializable object
- Can mix and match multiple Runnables here
"""
# Add input preprocessing scripts here or define your runnable!
# e.g. processed_data = preprocess_runner.transform.run(input_json)
result = custom_runner.predict.run(input_json)
# Add additional postprocessing scripts here or define your runnable!
# e.g. df_to_list = result.values.tolist()
return {"data": result, "status": 200}这种自助模板允许数据科学家部署自己的模型,并让他们对自己的工作有更多的控制权。此外,该模板的实施还将部署时间从一周大幅缩短到了半天。这让MLE团队有时间和精力专注于构建这个平台,并解决一个更大的问题:我们如何在生产中扩展这项服务?
MLE 的环状生命周期
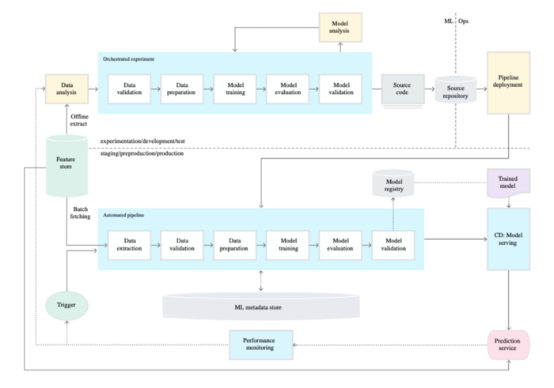
参考:MLOps Level 1 taken from Google Cloud Architecture Center MLOps: Continuous delivery and automation pipelines in machine learning
退一步讲,我们发现任何 ML 驱动的产品都包含以下内容:问题陈述、特征假设、数据提取、探索性分析、特征生成、模型训练、测试、部署和监控。虽然每个模型的每个组件都可能不同,但我们注意到其中存在一个重复的循环。对于其中的大多数步骤,我们的数据科学家将经历无数次的试验和错误,直到产生一个性能足够且可靠的模型。最后,我们需要管理模型的版本,以确保迭代是对以前版本的实际改进。
我们决定将重点放在 3 个关键领域来实现这一目标:
- 代码可维护性
- 自动化测试和部署
- 部署管理
代码可维护性
在传统的软件开发中,Github 被广泛用于跟踪版本间的代码更改。这可以帮助开发人员获得更改内容和更改者的版本历史记录。它很方便,因为我们可以轻松地修复被推到生产中的错误,而同样的原理也可以应用于机器学习模型。虽然 Github 通常用于观察脚本中的更改,但它也可以用于跟踪 Jupyter notebook IDE 中的更改。
在 Kumu,我们的大多数数据科学家使用运行在 Jupyter notebook IDE 之上的 Databricks 或 Sagemaker notebook云服务进行分析和模型实验。通过 Github 与这些云服务的本地集成,我们能够管理notebook中机器学习管道的代码更改,例如数据提取、数据验证、特征生成、模型训练和模型创建。同时,过程中每一步的更改都将保存到我们的 Github 存储库中。
除了在notebook上进行控制之外,我们还在 Python 中实施了编码标准,如 PEP 8,它是编写干净易懂代码的风格指南。我们通过一个名为 Github Actions 的 CI/CD 平台来自动化这一检查过程。我们使用了预提交挂钩(pre-commit hooks),它扫描并通知不遵循特定样式指南的代码更改。这有助于我们对代码库强制实施标准化的格式样式。此外,它还检测未使用的变量和导入,以确保编写的代码有效地使用资源。
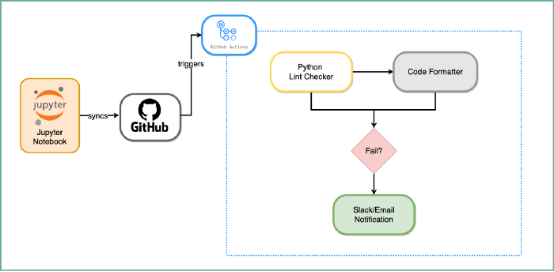
流程自动化
仅仅对部署进行模板化是不够的,因为模型一旦投入生产,就必须每天不断地进行监控和重新训练。如果你同时拥有三到五个实时模型,那确实是一场噩梦,你需要手动重新运行管道,并验证每个模型是否都已成功部署。
因此,我们决定使用 Airflow 作为我们的编排工具,通过 Airflow Directed Acyclic Graphs(DAG)自动可靠地运行这些重复性作业。每个 DAG 将被安排在每天特定的时间触发,从而按顺序运行模型部署步骤:
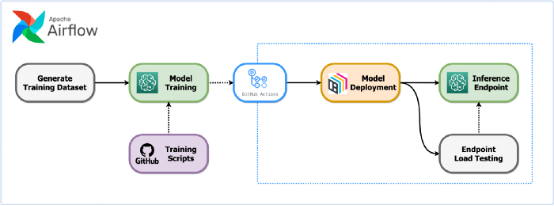
第一步是运行一个查询,生成一个更新的数据集,并将其输入到模型中重新训练。通过重新训练生成模型工件后,将向 Github Actions 发送一个 API 调用,以触发部署工作的启动。部署工作流将运行以下步骤:
- 将 EC2 服务器配置为运行程序
- 安装模型的必要项(例如,第三方库)
- 使用 BentoML 打包模型
- 部署到生产服务器
- 注意:我们最初考虑使用 Lambda 函数。但由于执行时间的限制,我们决定配置 EC2 提供更高的稳定性。
除了部署成功之外,稳定性的一个重要考虑因素是确保端点为生产级通信做好准备。作为行业惯例,我们将负载测试作为自动化工作流的一部分,以模拟端点如何处理超过峰值流量水平的流量。如果第90百分位P90的结果在我们的延迟率和错误率在阈值范围内,则模型端点可以继续。
与部署流程类似,我们需要执行以下操作以进行负载测试:
- 将 EC2 服务器配置为运行程序
- 安装用于运行负载测试的必要项,如 locus(负载测试框架)、Python 等。
- 使用预设配置(例如,模型端点 URL、用户数、持续时间等)执行负载测试
- 记录结果以供报告和后续考虑
- 必须记住,关键部分是确保股东了解正在发生的事情,这将我们引向下一个也是最后一个方面-部署管理。
部署管理
在所有这些步骤之后,流程的最后一个也是最关键的部分是确保股东了解正在发生的事情。进行模型部署管理意味着除了可见性之外,他们还需要拥有响应问题的能力。通过部署工作流,这一过程被抽象到维护工作最小化的程度,但基本步骤仍需要人工干预。
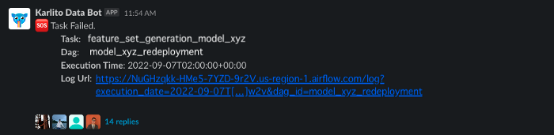
这就是为什么无论自动化管道的结果如何,Slack 警报都会发送到公共频道以方便讨论。否则,这些任务会以最小的开销自循环。然而,完全自动化也可能通过引入意想不到的更改危及平台的稳定性。在生产有重大变更之前,通知并要求股东确认来实施保护。针对任何环境触发的自动化 GithubActions 工作流在继续部署之前都需要审核者的批准(如数据科学经理或技术主管)。
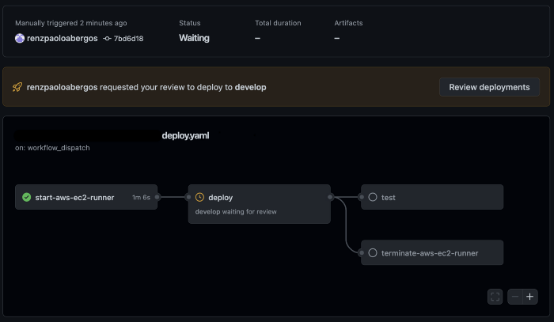
最后,我们遇到的一个更大的棘手问题是,当问题进入生产阶段时,我们该如何解决这些问题?设计更多配置驱动的服务消除了我们必须现场调试代码并加快整个开发-测试-部署周期的麻烦,在配置要使用的实例类型或端点的自动扩展策略时,能够使用简单参数应用更改对基础架构很有帮助。
结语
代码维护、自动化和治理对我们的团队产生了重大影响。过去的部署流程需要耗费大量人力,而且容易出现瓶颈,每两周就会推出一个模型。现在,MLE 团队能够以几乎不受限制的容量支持数据科学项目,而只需增加最少的人手。
很明显,我们对机器学习的需求已经远远超过了团队能够跟上的供应。这可能是一个极其复杂的挑战,但我们相信这一MLE 战略一定是可行而得当的 。不知不觉中,你也将获得更加智能和可扩展的功能,这无疑会为你带来更多可能性。欢迎来到机器学习的世界!
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Kumu Data Team
翻译作者:高佑兮
美工编辑:过儿
校对审稿:明慧
原文链接:https://medium.com/@karlitodata/ml-engineering-at-kumu-turning-models-into-products-b2b4faeb2b40





