
数据解读终极指南
我在Uber、Meta和高增长初创公司十年的经验教训。
数据可以帮助你做出更好的决策。
不幸的是,大多数公司更擅长收集数据,而不是解读数据。他们声称拥有数据驱动的文化,但实际上在做决策时仍然依赖经验判断。
作为数据科学家,你的工作是帮助业务相关方理解和解读数据,从而做出更明智的决策。你的影响力并不是来源于你进行的分析或构建的模型,而是来源于你帮助推动的最终业务成果。这是资深数据科学家与初级数据科学家的主要区别。
为了帮助实现这一目标,我根据我在Rippling、Meta和Uber将数据转化为可操作见解的经验,编写了这个指南。
我将介绍以下内容:
- 追踪哪些指标:如何为你的业务建立收入方程和驱动树
- 如何追踪:如何设置监控并避免常见陷阱。我们将讨论如何选择合适的时间范围,处理季节性变化,掌握分组数据等。
- 提取见解:如何以结构化和可重复的方式识别问题和机会。我们将介绍你可能遇到的最常见的趋势类型,以及如何解读它们。
听起来很简单,但细节决定成败,所以让我们逐一深入探讨。如果你想了解更多关于数据科学的相关内容,可以阅读以下这些文章:
所有数据科学家都应该知道的三个常见假设检验
如何开始自己的第一个数据科学项目?
导航数据驱动时代:为什么你需要掌握数据科学基础
数据科学家常见的13个统计错误,你有过吗?
第一部分:追踪哪些指标
首先,你需要确定应该追踪和分析哪些指标。为了最大限度的发挥影响力,你应专注于那些真正推动收入的指标。
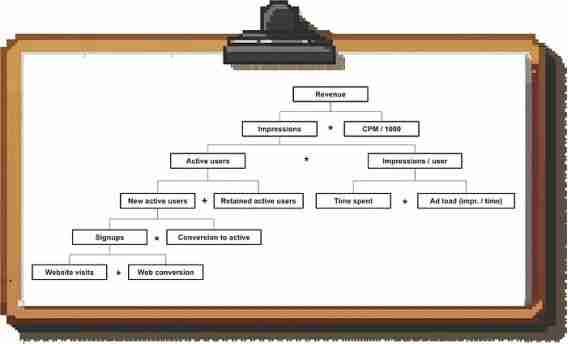
从高级的收入方程开始(例如,对于基于广告的业务,公式为“收入=展示次数*CPM/1000”),然后进一步分解每个部分,找到潜在的驱动因素。具体的收入方程取决于你所从事的业务类型,你可以在这里找到一些最常见的收入方程。
生成的驱动树,从顶部的输出到底部的输入,告诉你业务中哪些因素驱动结果以及你需要构建哪些仪表盘,以便进行端到端的调查。
例如:这是一个基于广告的B2C产品的(部分)驱动树。
理解领先指标和滞后指标
收入方程可能会让你觉得输入会立即转化为输出,但现实并非如此。
最明显的例子是营销和销售漏斗:你生成潜在客户,它们转变为合格的机会,最终成交。根据你的业务和客户类型,这可能需要数月时间。
换句话说,如果你在看一个结果指标(如收入),通常是在看几周或几个月前采取的行动所产生的结果。通常,越往下走,驱动树中的指标越是领先指标;越往上走,指标越是滞后指标。
量化滞后
值得查看历史转化窗口,了解你所处理的滞后程度。
这样,你就能更好地反向推理(如果你看到收入波动,你就知道需要追溯多远去寻找原因)以及进行前瞻性预测(你就知道需要多长时间才能看到新举措的影响)。
根据我的经验,制定经验法则(例如新用户平均需要一天还是一个月才能活跃)可以获得80%到90%的价值,所以没有必要过度设计。
第二部分:设置监控并避免常见陷阱
所以你已经有了你的驱动树,如何利用它来监控业务表现并为利益相关者提取见解?
第一步是设置一个仪表盘来监控关键指标。我不会深入比较各种BI工具,本文中讨论的所有内容都可以在Google Sheets或任何其他工具中轻松完成,因此你选择的BI软件不会成为限制因素。
相反,我想集中介绍一些最佳实践,帮助你理解数据并避免常见陷阱。
1.为每个指标选择合适的时间框架
虽然你希望尽早发现趋势,但需要小心不要陷入查看过于细致的数据并试图从大多数噪音中得出见解的陷阱。
考虑你正在测量的活动的时间范围以及你是否能够根据数据采取行动:
- 实时数据对于像Uber这样的B2C市场很有用,因为1)交易周期短(通常Uber行程在不到一小时内请求、接受并完成)以及2)因为Uber有工具可以实时响应(例如,动态定价、激励、司机通信)。
- 相比之下,对于B2B SaaS业务中,由于交易周期长,每日销售数据将会很嘈杂且可操作性较差。
你还需要考虑设定目标的时间范围。如果你的合作团队有月度目标,那么这些指标的默认视图应该是月度的。
但:月度指标(或更长时间段)的主要问题是,你只有很少的数据点可供使用,并且你需要等待很长时间才能获得更新的表现视图。
一个折衷方案是以滚动平均值的基础上绘制指标:这样,你会捕捉到最新的趋势,同时通过平滑数据去除大量噪音。
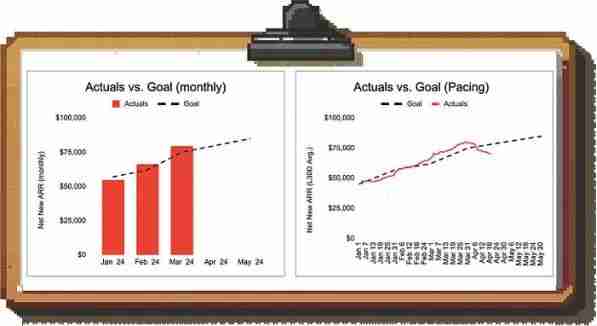
例如:查看左侧的月度数字,我们可能会得出结论,我们有能力实现4月份的目标;然而,查看30天滚动平均值,我们注意到收入产生量急剧下降(我们应该尽快深入研究这个问题)。
2.设置基准
为了从指标中得出见解,你需要能够将数字置于上下文中。
- 最简单的方法是随着时间推移对指标进行基准化:指标是在改善还是恶化?当然,如果你知道你希望指标达到的确切水平,那就更好了。
- 如果你有一个针对指标设定的正式目标,那就太好了。但即使没有,你也可以通过推导隐含目标来判断你是否在正轨上。
例如:假设销售团队有月度配额,但他们没有一个正式目标来确定需要生成多少销售线索以达到配额。
在这种情况下,你可以查看历史上开放销售线索与配额的比率(“销售线索覆盖率”),并将其作为你的基准。注意:通过这样做,你隐含地假设绩效将保持稳定(在这种情况下,团队将以稳定的比率将销售线索转化为收入)。
3.考虑季节性因素
在几乎所有业务中,解释数据时都需要考虑季节性因素。换句话说,你所关注的指标是否有按时间段/星期几/月初月末/日历月份重复的模式?
例子:看看这个B2B SaaS业务中新ARR的月度趋势图:
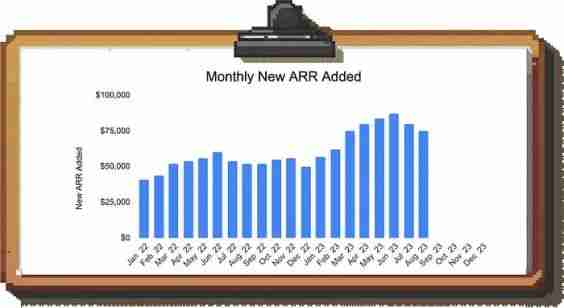
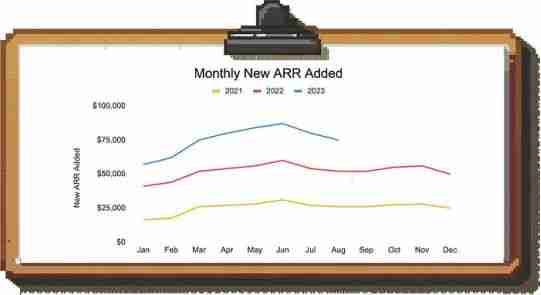
如果你在这个简单的条形图中看到7月和8月的新ARR下降,你可能感到震惊并开始深入调查。然而,如果你将每年的数据叠加在一起,你就会发现季节性模式,并意识到每年夏天都有一个低谷,并预计业务将在9月份会再次回暖:
但季节性因素不一定是按月的;可能是某些工作日的表现更强或更弱,或者通常会看到业务在月底回升。
例子:假设你想看看销售团队在当月(四月)的表现。现在是这个月的第15个工作日,迄今为止你已经实现了2.6万美元的销售额,而目标是5万美元。忽略季节性因素,似乎团队会错失目标,因为只剩下6个工作日了。
然而,你知道团队通常在月底会完成很多交易。
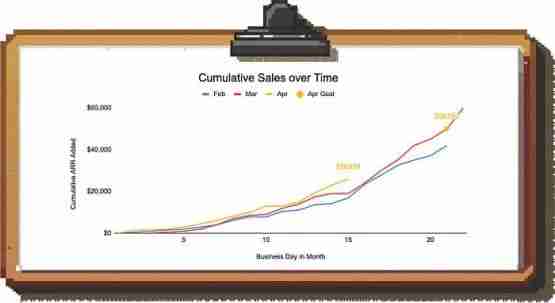
在这种情况下,我们可以绘制累积销售额并与前几个月进行比较,以理解模式。这使我们看到对于本月的这个时间点,我们实际上处于一个良好的位置,因为轨迹并不是线性的。
4.处理“成熟”指标
分析指标时最常见的陷阱之一是查看未充分“成熟”即未达到最终值的数字。
以下是一些最常见的例子:
- 用户获取渠道:你正在测量从流量到注册再到激活的转化;你不知道最近的注册用户中有多少将在未来转化
- 销售渠道:你的平均交易周期持续数月,你不知道最近几个月的开放交易中有多少将会成交
- 留存率:你想了解某一用户群体在你的业务中的留存情况
在所有这些情况下,最近群体的表现看起来比实际情况更糟糕,因为数据尚未完整。
如果你不想等待,通常有三种方法来解决这个问题:
选项1:按时间段划分指标
最直接的方法是按时间段划分汇总指标(例如,第一个星期转化率、第二个星期转化率等)。这使你可以在进行同类比较的同时获得早期读数,并避免对较老的群体产生偏见。
你可以将结果显示在群体热图中。以下是一个追踪从注册到首次交易转化的获取渠道示例:
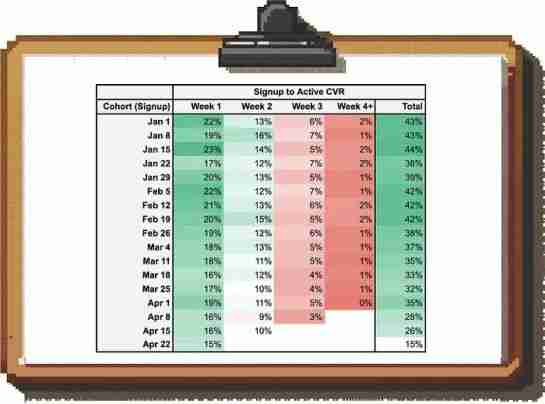
这样,你可以看到,从同类比较来看,我们的转化率在下降(我们第一周CVR从20%以上下降到约15%左右)。如果仅看汇总转化率(最后一列)我们无法区分实际下降和不完整的数据。
选项2:改变指标定义
在某些情况下,你可以改变指标的定义以避免查看不完整的数据。
例如,与其查看3月份进入管道的交易到目前为止的成交情况,不如查看3月份成交的交易中成功与失败的比例。这个数字不会随着时间而变化,而你可能需要等待数月才能看到3月份交易群体的最终表现。
选项3:预测
基于过去的数据,你可以预测某一群体的最终表现。时间越长,收集到的实际数据越多,预测将越接近实际值。
但要小心:预测群体表现需要谨慎,因为这很容易出错。例如,如果你在一个赢率较低的B2B业务中,那么一个交易可能会显著改变群体的表现。准确预测这一点非常困难。
第三部分:从数据中提取见解
这些数据都很好,但我们如何将它转化为见解呢?
你没有时间定期深入研究每一个指标,因此请优先考虑您的时间,先查看最大的差距和变化因素:
- 团队在哪些方面没有达到目标?哪里出现了意外的出色表现?
- 哪些指标在下滑?哪些趋势在逆转?
一旦选择了感兴趣的趋势,你需要深入挖掘并找出根本原因,以便你的业务合作伙伴能够提出有针对性的解决方案。
为了给你的深入研究提供结构,我将介绍你会遇到的关键指标趋势的关键原型,并根据现实生活中的经验提供具体示例。
1.净中性变化
当你看到某个指标发生剧烈变化时,先往上查看驱动树,然后再往下查看。这样,你可以看到这个数字是否真的影响了你和团队最终关心的问题;如果没有,那么找出根本原因就没那么紧迫了。
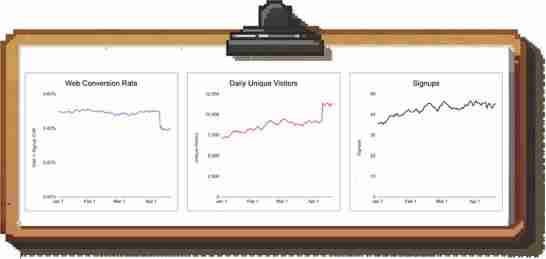
示例场景:在上图中,你看到你的网站访客到注册的转化率大幅下降。你没有惊慌,而是查看了总注册人数,发现这个数字是稳定的。
事实证明,平均转化率的下降是由于网站的低质量流量激增造成的;而“核心”流量的表现没有变化。
2.分母与分子
在处理比率指标的变化时(每个活跃用户的展示次数、每个司机的行程次数等),首先检查是分子还是分母发生了变化。
人们往往假设是分子发生了变化,因为这通常是我们试图在短期内增长的参与度或生产力指标。然而,很多情况下事实并非如此。
示例:
- 你看到每个销售代表的线索数量下降,因为团队刚刚招聘了一批新人,而不是因为你有需求生成问题。
- Uber司机每小时的出行次数下降,并不是因为乘客请求减少,而是因为团队增加了激励,更多司机上线。
3.孤立/集中趋势
许多指标趋势是由产品或业务中特定部分发生的事情驱动的,汇总数字并不能说明全部情况。
用于隔离根本原因的一般诊断流程如下所示:
步骤1:不断分解指标,直到你隔离了趋势或无法再细分指标。
类似于数学中每个数字都可以分解为一组质数,每个指标都可以不断分解,直到达到基本输入。
这样,你可以将问题隔离到驱动树的特定部分,从而更容易找出问题所在及相应的对策。
步骤2:细分数据以隔离相关趋势
通过细分,你可以找出业务特定区域是否是问题所在。通过以下维度进行细分,你应该能捕捉到90%以上的问题:
- 地理位置(地区/国家/城市)
- 时间(月内时间、星期几等)
- 产品(不同SKU或产品界面,例如Instagram Feedvs.Reels)
- 用户或客户人口统计(年龄、性别等)
- 个人实体/参与者(如销售代表、商家、用户)
我们来看一个具体示例:
假设你在DoorDash工作,发现波士顿的完成交付量逐周下降。与其头脑风暴如何推动需求或提高完成率,不如尝试找出问题所在,以便开发更有针对性的解决方案。
第一步是分解“已完成交付”指标:
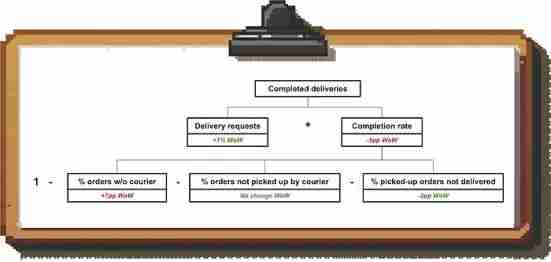
根据这个驱动树,我们可以排除需求方面的问题。相反,我们看到最近难以找到司机接单(而不是餐厅和快递员交接或食品投递的问题)。
最后,我们将检查这是否是一个普遍存在的问题。在这种情况下,一些最有希望的切分方法是查看地理位置、时间和商家数据。商家数据表明这个问题普遍影响了许多餐厅,因此这不能帮助我们缩小范围。
然而,当我们为“找不到快递员的送货请求”指标创建时间和地理位置的热图时,我们发现晚上受影响最大的是波士顿郊区:
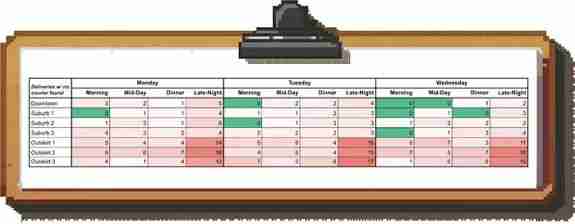
我们如何利用这些信息?能够像这样找出问题所在,使我们能够在这些时间和地点部署有针对性的快递员招聘和激励措施,而不是在整个波士顿泛泛而施。
换句话说,隔离根本原因使我们能够更有效地部署资源。
你可能会遇到的其他集中趋势的示例:
- 在线游戏中的大部分内购都是由少数“鲸鱼”玩家完成(因此团队会将保留和参与努力集中在这些玩家身上)
- 升级到工程部门的大部分支持工单是由少数支持代表引起的(通过培训这些代表,为公司提供了有针对性的杠杆,以释放工程师的时间)
第四部分:组合变化
在诊断绩效时,最常见的困惑来源之一是组合变化和辛普森悖论。
组合变化只是指总人口组成的变化。辛普森悖论描述了一种反直觉的效果,即当观察子成分时,你在总人口中看到的趋势消失或逆转(反之亦然)。
实际操作中是什么样的呢?
假设你在YouTube(或任何其他运行广告的公司)工作。你看到收入在下降,深入数据后,注意到CPM已经下降了一段时间。
CPM作为一个指标无法进一步分解,所以你开始对数据进行细分,但难以找出根本原因。例如,各地区的CPM看起来都很稳定:
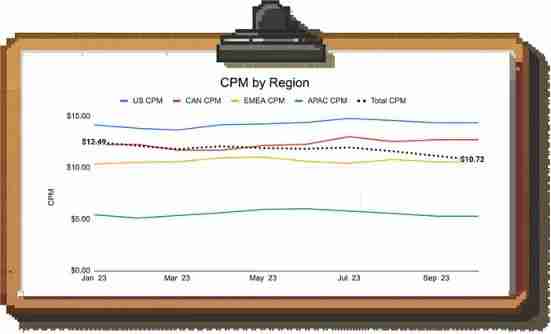
这时组合变化和辛普森悖论就显现出来了:每个地区的CPM都没有变化,但如果你查看按地区划分的展示次数组成,你会发现组合正在从美国转移到亚太地区。
由于亚太地区的CPM低于美国,因此整体CPM正在下降。
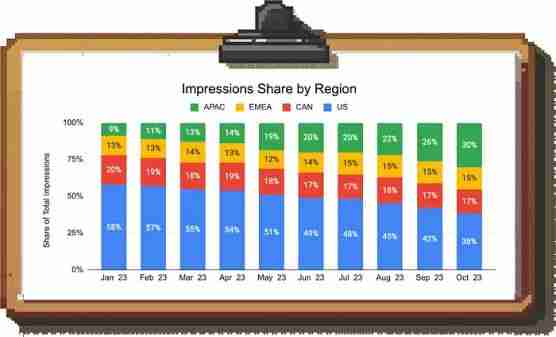
再次说明,了解确切的根本原因可以让应对措施更加有针对性。基于这些数据,团队可以尝试重新点燃高CPM地区的增长,考虑亚太地区的额外货币化选项,或者通过在庞大的亚太市场中实现展示量的超高速增长来弥补单个展示价值的不足。
总结
记住,数据本身没有价值。只有当你用它来为用户或内部利益相关者生成见解或建议时,它才会变得有价值。
通过遵循一个结构化的框架,你将能够可靠地识别数据中的相关趋势,并通过遵循上述提示,区分信号和噪声,避免得出错误的结论。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Torsten Walbaum
翻译作者:文杰
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/the-ultimate-guide-to-making-sense-of-data-aaa121db1119





