
成为Kaggle金字塔顶端的2%有那么难么?
Kaggle比赛是训练Machine Learning很重要的一个途径。对于ML的建模,将数据每个feature理解清楚是决定模型好坏的重要环节。下面讲的这些理解feature的小技巧曾经在Instacart Market Basket Analysis竞赛中获得前2%,并在比赛外的现实建模中也非常实用。
理解特征,对于建立任何高级的机器学习模型都很重要。我们可以通过观察每一个特征的的模型输出来理解这一特征。这次我们将用Python里的featexp package分析kaggle的真实数据Home Credit Default Risk。

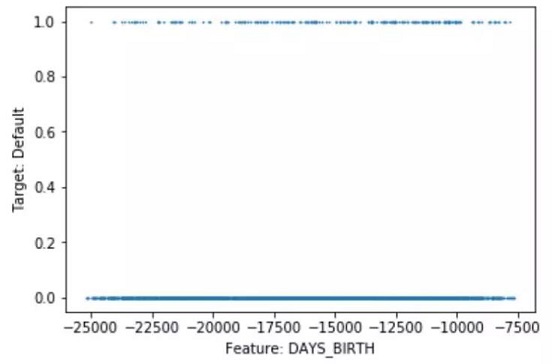
如上图👆所示,如果因变量Y是二进制的,那么scatter plot就很不适用,因为变量值不是0就是1。对于连续变量,由于数据太多,我们也很难解释因变量与feature之间的关系。Featexp可能会帮我们解决这一问题,我们来试试!

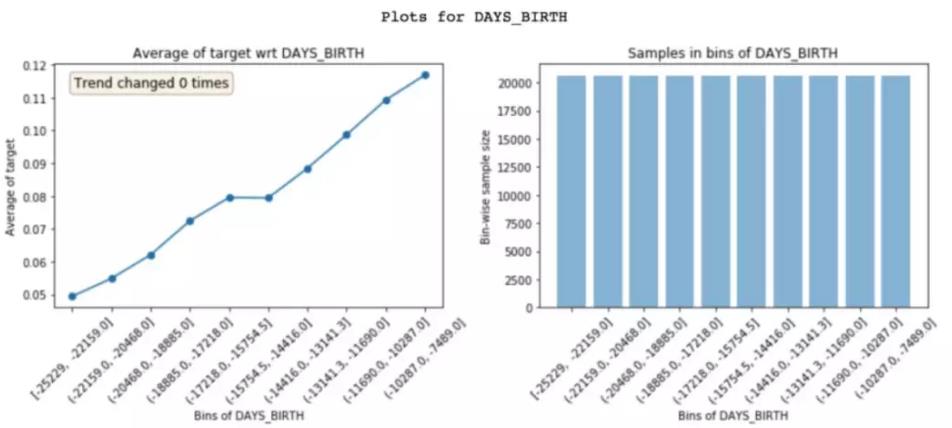
Featexp讲feature的数据分为多个区间并将每个区间的均值计算出来。这样做出的图片明显看到DAYS_BIRTH越低拖欠住房贷款的概率越高,也就是说越是年轻的人越倾向于拖欠住房贷款。右边的图显示了每个区间里的数据个数。

Noisy feature通常会导致模型overfitting,而且很难被辨别。Featexp可以通过测试feature trend在train set和test set的差异来辨别noisy feature。这里的test set不是真实中要运用的数据,而是本地的validation set。

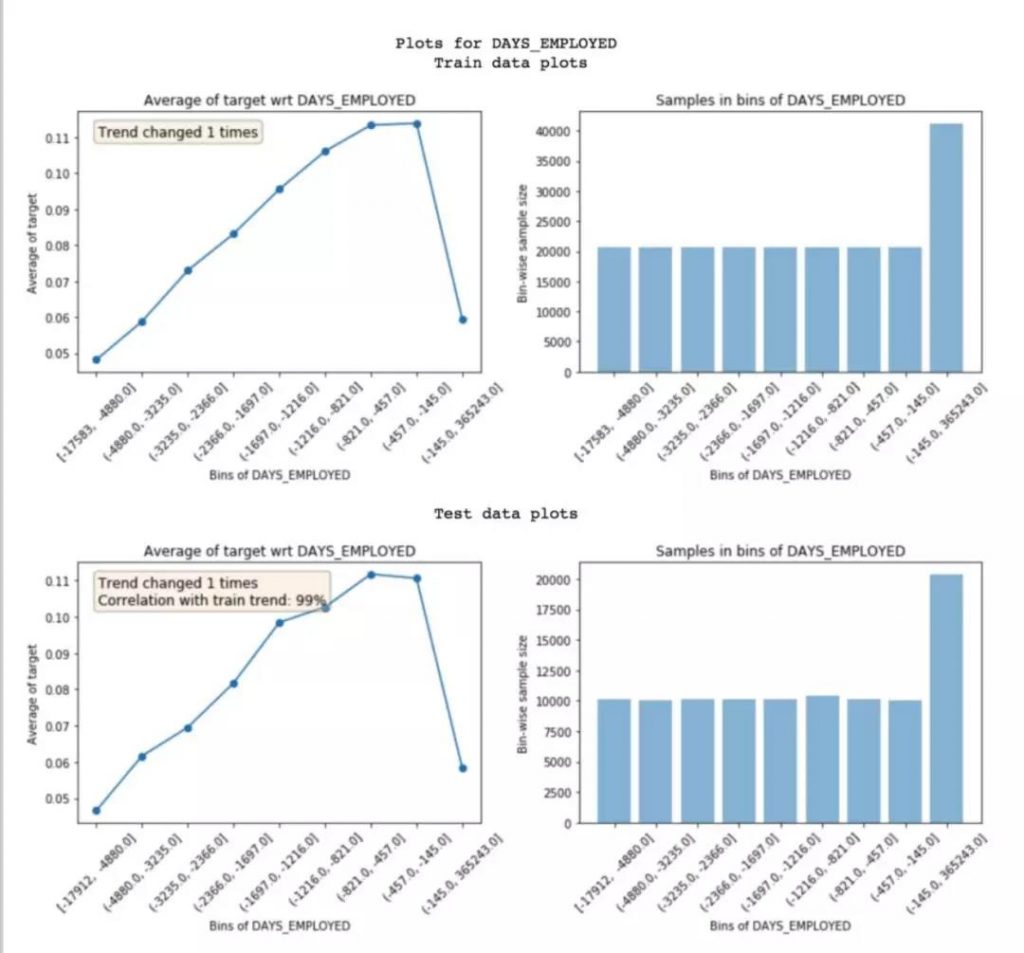
Trend Change通常暗示feature noisy的存在,但有时也是因为每个区间的个数不同导致的。Trend Correlation指提取的feature trend在train set和test set吻合度的大小。上图得到的结果是非noisy feature。下图👇我们展示一个noisy feature的图作为对比。
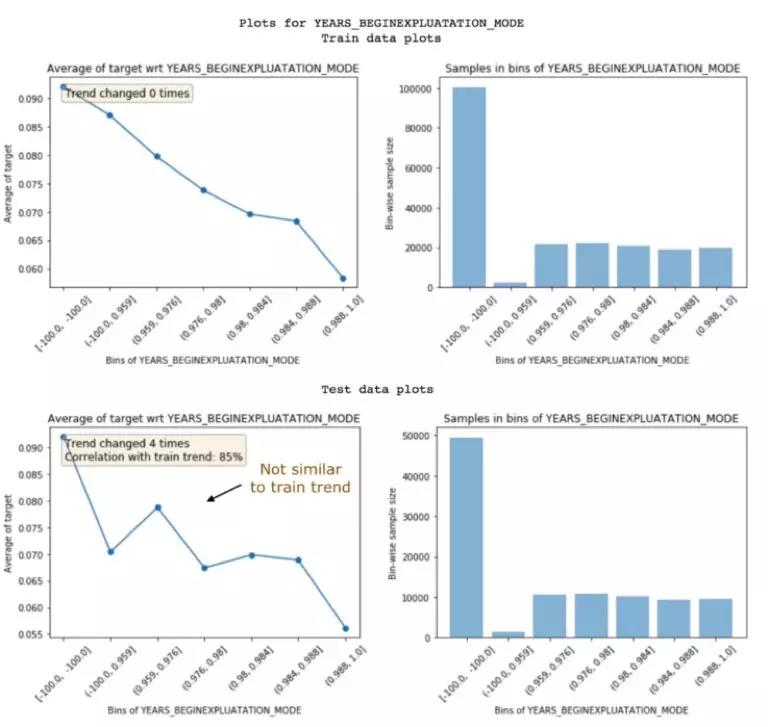
合理的删减noisy feature是可以降低overfitting。但是不小心删减掉一些重要的feature也会大大降低模型的表现。所以我们就要用feature importance来权衡。
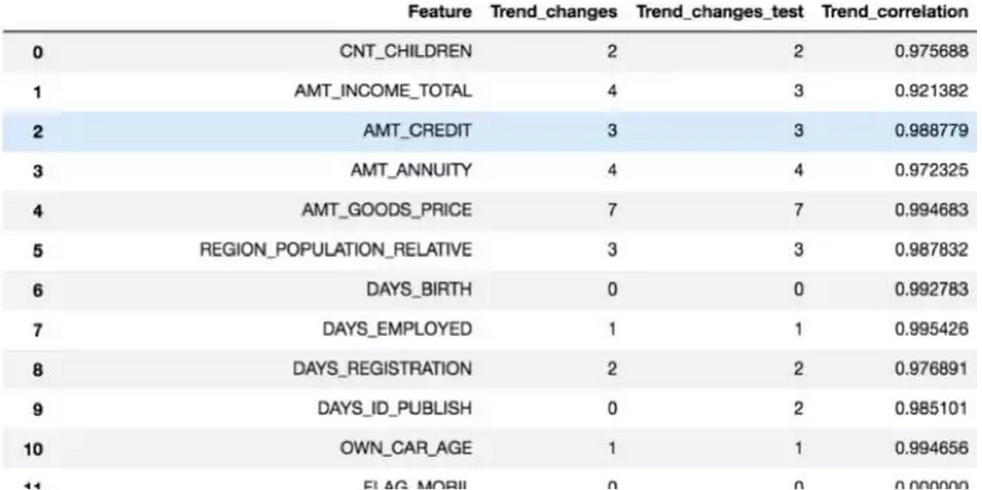
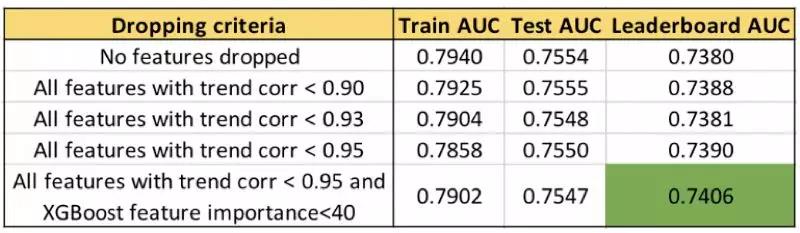
这样选择性的删减feature的效果到低怎样呢,我们用AUC作为参考来比较。AUC越靠近1说明模型表现越好,下图结果现实合理的删减feature的确可以一定程度的提高模型表现。

Featexp还可以提高保留后feature的表现。取另一个feature EXT_SOURCE_1为例,除了第一组区间,总体呈现递减的趋势。但是在linear model里为了保持线性关系,可以将第一组区间的值添加到具有类似default rate的区间里。


同样的还可以比较feature的重要性。比如DAYS_BIRTH与EXT_SOURCE_1都有很好的trend表现,但由于EXT_SOURCE_1有特殊区间的存在,所有他的重要性就要靠后一点。


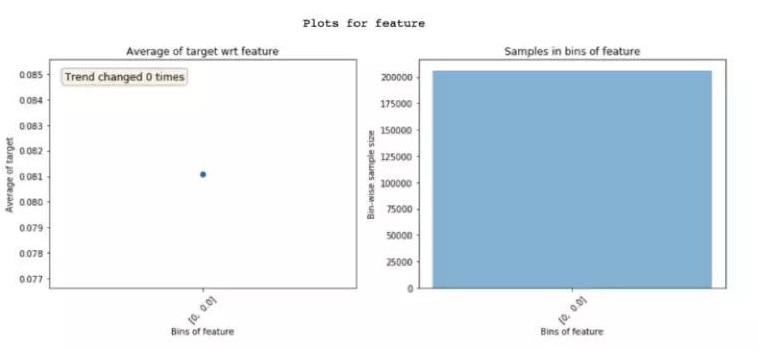
Featexp当然还可以检测feature的错误,比如观察feature的分布是否正常,feature trend的结果是否与你做图前预测的相差过大。下图👇就是一个极端的例子。

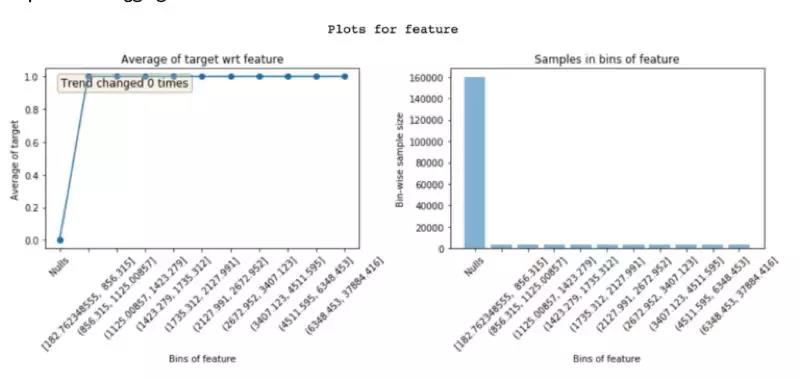
Leakage feature也是导致overfitting的因素之一,也同样也较难理解。但是featexp有时就很有力的呈现leakage feature产生的原因。比如下图,很明显的阐释了这个leakage feature的原因是Default成立后才会产生数据。

在把所有feature相关的图都做好以后,一旦我们在之后的模型中将数据做了调整,都可以回头快速重新画图来检测并做出相应的修正,来保证所有feature都是有意义并有效地。
Featexp看似很简单,但是在现实应用中非常实用且高效。
原文作者:Abhay Pawar
翻译作者:创作小废物最后的作品
美工编辑:送别小废物的Narcia
校对审稿:一定会走运的卡里
原文链接:https://www.kdnuggets.com/2018/11/secret-sauce-top-kaggle-competition.html





