
20大数据科学家面试问题
非技术数据科学面试问题
1.请谈谈你曾经如何向一个非技术背景的人解释一个复杂的数据概念,你是如何确保他们理解的?
这个问题评估你的沟通技巧和简化复杂话题的能力。下面是一个例子:
在我之前的工作中,我必须向我们的营销团队解释机器学习的概念。我用教孩子识别不同种类水果来类比。就像你会给孩子看很多例子来帮助他们学习一样,机器学习模型是用数据训练的。这种类比有助于使一个复杂的概念更容易理解。
2.描述一个你必须和一个难相处的团队成员合作的项目。你是如何处理这种情况的?
这将探索你的团队协作技能和解决冲突的能力。你可以这样回答:
在一个项目中,我和一个有着非常不同工作风格的同事一起工作。为了解决我们之间的分歧,我安排了一次会议来了解他的观点。我们在项目目标上找到了共同点,并就共同的方法达成了一致。这段经历让我明白了团队合作中开放沟通和共情的价值。
3.你能举一个你必须在紧迫的最后期限内完成工作的例子吗?你是如何管理你的任务并按时交付的?
这个问题是关于时间管理和优先排序的。下面是一个例子:
有一次,我必须在很紧的期限内提交一份分析报告。我对项目中最关键的部分进行了优先排序,向团队传达了我的计划,并专注于高效的执行。通过分解任务和设定小期限,我设法在不影响质量的情况下按时完成了项目。
4.你曾经在分析中犯过重大错误吗?你是如何处理的?你从中学到了什么?
在这里,面试官着眼于你承认错误并从中吸取教训的能力。
你可以这样回答:有一次,我误解了数据模型的结果。在意识到我的错误后,我立即通知了我的团队,并重新分析了数据。这段经历教会了我反复检查结果的重要性,以及工作场所透明度的价值。
5.你是如何跟踪最新的数据科学趋势和进展的?
这表明你致力于不断学习,并在你的领域保持相关性。下面是一个示例答案:
我通过阅读行业期刊、参加网络研讨会和参加在线论坛来了解最新情况。我每周也留出时间来尝试新的工具和技术。这不仅能帮助我跟上潮流,还能不断提高我的技能。
6.你能告诉我们你在一个需求不明确或不断变化的项目中工作的经历吗?你是如何适应的?
这个问题评估适应性和解决问题的能力。举个例子,你可以说:
在以前的项目中,需求经常发生变化。我通过与利益相关者保持开放的沟通来了解他们的需求。我还使用敏捷方法使我的方法更加灵活,这有助于有效地适应变化。
7.描述你必须在数据驱动的决策与其他考虑因素(如道德问题、业务需求等)之间取得平衡的情况。
这将评估你考虑数据之外的各个方面的能力。举个例子:
在我的上一份工作中,我必须在数据驱动决策的需求与道德考虑之间取得平衡。我确保所有数据的使用都符合道德标准和隐私法,并在必要时提出替代方案。这种方法有助于在尊重道德界限的同时做出明智的决定。
技术数据科学面试问题
8.使用什么特征选择方法来选择正确的变量?
有三种主要的特征选择方法:过滤器法、包装器法和嵌入法。
过滤器方法
过滤方法通常用于预处理步骤。这些方法从独立于任何机器学习算法的数据集中选择特征。它们速度快,所需资源少,并且可以删除重复的、相关的和冗余的特性。
一些常用的技术包括:
- 方差阈值
- 相关系数
- 卡方检验
- 相互依赖
包装器方法
在包装器方法中,我们使用特征子集迭代地训练模型。根据训练模型的结果,添加或删除更多的特征。它们在计算上比过滤方法更昂贵,但提供更好的模型精度。
一些常用的技术包括:
- 前向选择
- 后向消除
- 双向消除
- 递归消除
嵌入式方法
嵌入式方法结合了过滤器和包装器方法的特性。特征选择算法作为学习算法的一部分,为模型提供了内置的特征选择方法。这些方法像过滤器方法一样更快,像包装器方法一样准确,并且还考虑了特征的组合。
一些常用的技术包括:
- 正则化
- 基于树的方法
9.如何避免模型过拟合?
过拟合是指一个模型在训练数据集上训练得太好,但在测试和验证数据集上失败。
你可以通过以下方式避免过拟合:
- 通过降低模型复杂度、考虑更少的变量和减少神经网络中的参数数量来保持模型的简单性。
- 使用交叉验证技术。
- 用更多的数据训练模型。
- 使用增加样本数量的数据增强。
- 使用集成方法(Bagging和Boosting)
使用正则化技术来惩罚可能导致模型过拟合的某些模型参数。
10.解释置信区间
置信区间是对未知参数的估计范围,当你再次进行实验或对总体进行类似的重新采样时,你期望在某个百分比的情况下,这个参数会落在这个范围内。
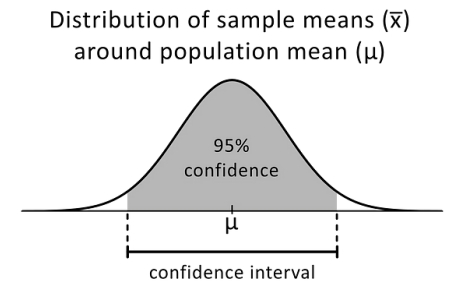
95%置信水平通常用于统计实验,它是你期望重现估计参数的时间百分比。置信区间具有由alpha值设置的上限和下限。
你可以对各种统计估计使用置信区间,例如比例、总体均值、总体均值或比例之间的差异,以及组间变化的估计。
11.如何管理不平衡的数据集?
在非平衡数据集中,类的分布是不均匀的。例如,在欺诈检测数据集中,只有400个欺诈案例,而非欺诈案例有30万个。不平衡的数据会使模型检测欺诈的性能变差。
要处理不平衡的数据,你可以使用:
- 欠采样
- 过采样
- 创建合成数据
- 欠采样和过采样的组合
12.如果在一个聚类项目中标签是已知的,你会如何评估模型的性能?
在无监督学习中,评估聚类项目的性能可能会很棘手。良好聚类的标准是相似度低的不同群组。
在聚类模型中没有精度度量,因此我们将使用组之间的相似性或独特性来评估模型的性能。
三个常用的指标是:
- 轮廓系数
- Calinski-Harabaz指数
- Davies-Bouldin指数
13.编写一个函数,从正态分布中生成N个样本,并绘制直方图。
要从正态分布中生成N个样本,你可以使用Numpy(np.random.randn(N))或SciPy (sp.stats.norm.rvs(size=N))。
要绘制直方图,你可以使用Matplotlib或Seaborn。
如果你知道正确的工具,这个问题很简单。
- 你将使用Numpy randn函数生成随机正态分布样本。
- 使用Seaborn通过KDE绘制直方图。
- 绘制10K个样本的直方图并返回Numpy数组。
import numpy as np
import seaborn as snsN = 10_000def norm_dist_hist(N):
# Generating Random normal distribution samples
x = np.random.randn(N)
# Plotting histogram
sns.histplot(x, bins = 20, kde=True);
return x
X = norm_dist_hist(N)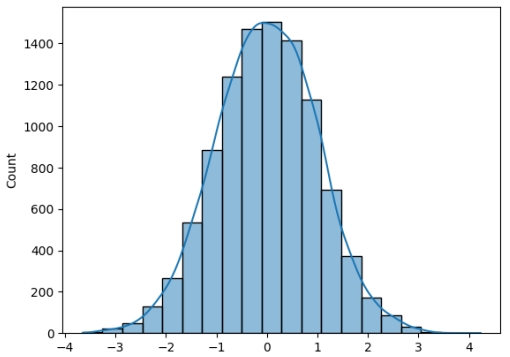
未完待续。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Asad iqbal
翻译作者:文玲
美工编辑:过儿
校对审稿:Jason
原文链接:https://deasadiqbal.medium.com/top-20-data-scientist-interview-questions-c0dc48142953





