
解密OpenAI控制时空的秘密武器—Sora
最近,OpenAI发布的重量级模型Sora占据了各大媒体的头条。它可以生成一分钟的视频,超越了现有的视频生成模型。大家都被它的效果惊呆了。不过,从披露的信息来看,OpenAI似乎并没有使用新的模型架构。与GPT类似,这个Sora模型也是基于Diffusion和Transformer这样的结构。通过扩大模型规模,提供更丰富的训练数据,就像GPT3的另一个奇迹一样,他们创造了这个强大的武器—Sora。
我想试着用通俗易懂的语言和大家聊天:Sora背后的技术是如何实现的?Sora的出现对产品设计有什么影响?如果你想了解更多关于OpenAI的相关内容,可以阅读以下这些文章:
OpenAI新的嵌入模型和API更新
OpenAI刚刚证明了人类并没有为即将到来的事情做好准备
OpenAI近期发布了GPTs:创建自己的ChatGPT并从中赚钱(无需编码)
OpenAI是否秘密创造了类脑智能?
我的目标是让普通人也能轻松理解。

动图链接:https://miro.medium.com/v2/resize:fit:640/format:webp/0*YDdQaHyGJyunSXWY,
图片来自作者
动图中,几头毛茸茸的巨型猛犸象在雪景中穿越草原,长长的毛发在微风中轻轻摇摆。远处是白雪覆盖的树木和雄伟的雪山,午后的阳光透过薄薄的云层,洒下温暖的光辉。
而这一切都是由OpenAI的最新旗舰产品Sora自动生成的。

Sora是一款可以根据用户的文字描述生成视频的人工智能产品。想象一下,在未来,你只需要给Sora一个大致的故事描述,比如“一个小怪物在玩蜡烛”,Sora就能制作出相应的视频来讲述这个故事。

简而言之,通过学习大量视频数据,Sora可以理解不同场景、动作和物体的视觉表现。然后,它利用这些获得的知识,根据文字提示生成新的视频内容。这就好比邀请一位电影导演根据你的提示来创作一部电影,只不过这位导演是人工智能。
虽然目前Sora生成的内容还存在一些缺陷,但是整个影视行业都感受到了前所未有的冲击,就像23年初Midjourney V5发布时对设计行业的冲击一样。
浅谈sora背后的技术实现
第一点
Sora应该模拟人类观察、描绘和表现世界的方法。例如,如果让一位经验丰富的人类艺术家用钢笔画出三个场景,我们人类的大脑中并不需要三维建模。
因为人类已经对世界有了基本的了解,我们知道透视原理。我们知道,随着镜头的移动,每个物体的视觉形象都会发生变化。我们知道如何画出毛茸茸的头发,如何画出皑皑白雪。当一只狗转过身来时,我们知道整个画面会发生什么样的变化。我们不需要了解粒子效果三维建模或物理定律;依靠对世界的观察,我们可以捕捉到高耸的波浪的感觉,而不需要这些。
通过大量的训练,Sora掌握了人类观察、描绘和表现世界的能力。这使他能够通过在表面上生成看似二维的图像,完全理解这个三维世界的物理规律。
第二点
Sora使用一种名为“视频压缩网络”的特殊网络来“压缩”视频,将图像块转换成统一的、更小的信息形式。为什么这种压缩很重要?因为压缩后的图像块可以大大减少计算负荷,让Sora在训练过程中更有效地处理大量数据。
压缩视频数据后,Sora会生成所谓的“隐时空块”(Spacetime Latent Patches)。顾名思义,这些图像块包含时间和空间信息,是Sora核心技术的一部分。这项技术能让Sora在处理视频数据时保持空间一致性,就像艺术家在绘画时确保运动物体在三维空间中的运动连贯合理一样。
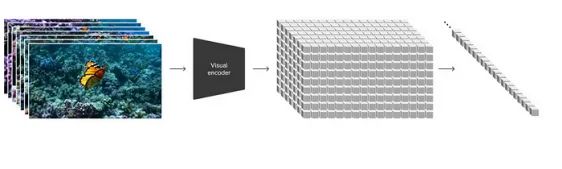
如果你还不清楚“图像块”的概念,可以将其类比为GPT中的“标记”概念。这种方法受到大型语言模型处理文本数据的启发。在这里,图像块就像GPT用于文本处理的标记。这可以看作是OpenAI Transformer架构的扩展和发展。与主流视频生成模型中常用的U-Net架构不同,OpenAI在经验和技术选择上都体现了其独特性。
第三点
Sora使用扩散模型生成视频,这一过程被称为“视频生成的缩放变换器”。扩散模型是一种生成模型,它通过学习如何去除数据中的噪音来创建新的数据样本。

因此,当我们向Sora提供提示时,Sora生成的初始图像充满了“噪音”,每个像素都被随机分配了一个颜色值,就像老式电视屏幕上的静态图像。通过训练,Sora会不断调整图像块的位置、大小、角度和亮度等参数,以预测这些噪声图像背后的“清洁”状态。通过逐步去除噪音,视频会显得更加自然流畅。
这个过程就好比艺术家先勾勒出大致轮廓,然后一步步添加细节,直到作品从模糊变得清晰为止。对于视频来说,这意味着一次预测多个帧,并将这些嘈杂的帧转化为清晰的图像,然后将这些图像无缝地组合在一起,形成最终的视频。
结论与总结
在本文即将结束之际,我们不禁对Sora模型所展示的技术深度和创新能力感到惊叹。通过本文,我们试图揭开这一人工智能里程碑式成就的神秘面纱,深入探讨其技术架构、训练过程及其核心模块的工作原理。
需要指出的是,尽管我已尽最大努力提供尽可能准确的分析,但有关Sora模型的一些技术细节尚未完全正式披露。因此,我提出的解释和猜测完全基于现有信息和我的理解,其中可能包含某些偏差或误解。此外,由于工作繁忙,我在撰写这篇文章时可能比较仓促,因此在引文、格式、描述、内容分类级别和逻辑等方面可能存在一些问题。我计划在今后有更多时间时逐步解决和纠正这些问题。
我热忱欢迎并鼓励业内专家、学者以及对人工智能充满好奇的朋友们提出问题或指出错误,以便进一步讨论。Sora作为一个不断发展和完善的模型,我们对它的理解和应用也将随着时间和技术的进步而不断发展。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Frank Lee
翻译作者:Qing
美工编辑:过儿
校对审稿:Jason
原文链接:https://generativeai.pub/decoding-openais-secret-weapon-that-controls-time-and-space-sora-9255d168aab6





