
数据清理必备的Python Packages
很多人会认为数据科学工作主要在开发机器学习模型和评估技术指标这两个部分。虽然没有错,但数据科学的工作责任远不止于此。数据科学家们还需要对数据进行收集、清洗、分析、理解等工作。
那么,数据科学家在哪些任务上花费的时间最多?根据CrowdFlower的一项调查,数据科学家 80% 的时间都在做数据清理。这其实并不奇怪,因为我们的数据科学项目很大程度上会取决于我们数据的清洁程度。
但是,有一些方法可以帮我们通过使用数据清洗包来缩短数据清洗处理时间。这些包是什么,它们是如何工作的?接下来就让我们一起学习。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
长文总结数据清洗的完全指南
年收入$500和$225,000的数据科学家之间有什么区别?
Data Scientist生产力进阶—Python OOP编程快速入门
Bridgerton(布里奇顿):对现在Netflix 最受欢迎的电视剧的分析
1► Pyjanitor
Pyjanitor是R语言的Janitor包的一个实现,用于在 Python 环境中使用链接方法(chaining methods)清理数据。它易于使用,有直接连接到 Pandas 包的 API。
从历史上看,Pandas 已经提供了很多有用的数据清理功能,例如dropna用于删除空值和to_dummies用于分类编码。而另一方面,Pyjanitor 没有取代它,而是增强了 Panda 的清洁 API 能力。那Pyjanitor 是如何工作的?让我们尝试在我们的数据清理过程中使用 Pyjanitor。
作为一个项目案例,我将使用来自Kaggle的数据集 Coffee meet Bagel review :
https://www.kaggle.com/datasets/shivkumarganesh/coffee-meets-bagel-app-google-play-store-review
import pandas as pd
review = pd.read_csv('data_review.csv')
review.info()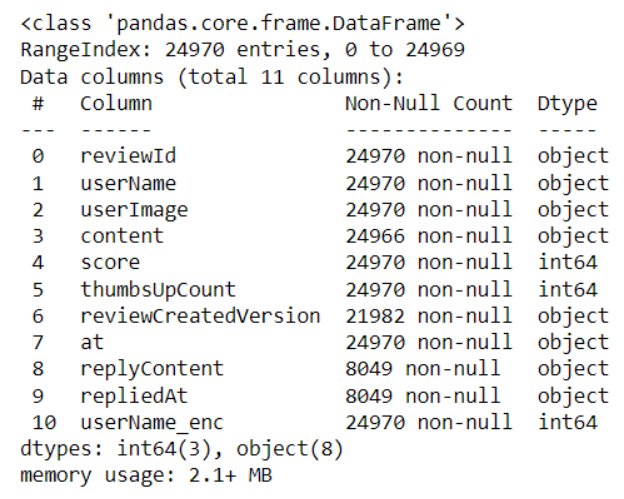
我们的数据集中有 11 列包含对象和数值的数据。乍一看可以发现,有些数据好像缺失了,列的名字也不规范。让我们尝试用 Pandas 和 Pyjanitor 清理数据集。
在开始之前,我们需要安装 Pyjanitor 包。
pip install pyjanitor当你安装完包后,我们只需要导入包,API 功能就可以通过 Pandas API 立即使用。让我们把 Pyjanitor 包用在数据集上。
import janitor
jan_review = review.factorize_columns(column_names=["userName"]).expand_column(column_name = 'reviewCreatedVersion').clean_names()在上面的代码示例中,Pyjanitor API 执行了以下操作:
- 1. 分解 userName 列,将分类数据转换为数值数据( factorize_columns ),
- 2. 展开 reviewCreatedVersion 列、 或者是独热编码(One-Hot Encoding)过程( expand_column ),
- 3. 替换所有空格(clean_names )。
以上只是一些我们可以用 Pyjanitor 执行的操作。当然,你也可以用 Pyjanitor 做更多的事情,常见的功能如下:功能性
- 清理列的名字(可以多索引)
- 删除空行和空列
- 识别重复条目
- 将列编码为分类数据
- 将数据拆分为特征和目标(用于机器学习)
- 添加、删除和重命名列
- 将多列合并为一列
- 日期转换(从 matlab、excel、unix)到 Python 日期时间格式
- 将具有分隔的分类值的单列展开为虚拟编码变量
- 基于分隔符,连接和取消连接列
- 根据列查询、过滤数据帧
- 关于金融、生物、化学、工程和 pyspark 的实验子模块
此外,chain 方法也同样适用于 Panda 的原始 API。你可以将两者结合起来应用,然后得到你想要的干净数据。
2► Klib
Klib是一个用于导入、清理、和分析的开源 Python 包。它是一个一站式包,可以轻松理解你的数据和预处理。这个软件包非常适合帮你用直观的可视化和易于使用的 API 来评估你的数据。
由于本文只讨论数据清洗,让我们重点关注数据清洗相关的 API。
对于数据清洗,Klib 依靠data_cleaning API 来自动清洗数据帧。让我们尝试用它清理我们的数据集示例。首先,我们需要安装包。
pip install klib安装后,我们会将数据集传递给data_cleaning API。
import klib
df_cleaned = klib.data_cleaning(review)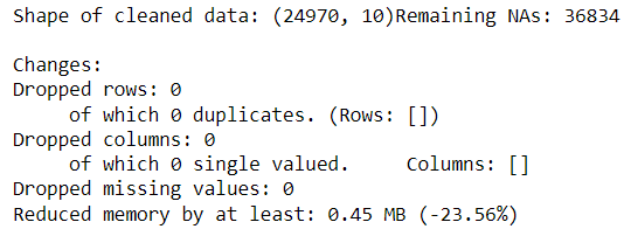
上述函数生成对我们的数据集示例进行的数据清理信息。Klib data_cleaning程序遵循当前步骤:
- 列名的清理
- 删除空的和几乎空的列
- 删除单个基数的列
- 删除重复的行
- 减少内存
3► DataPrep
DataPrep是为数据准备而创建的 Python 包,其主要任务包括:
- 数据探索
- 数据清洗
- 数据采集
出于本文的目的,我将重点介绍 DataPrep 的数据清理 API部分。
DataPrep 清理提供了 140 多个用于数据清理和验证的 API。我将在下面的 GIF 中展示所有可用的 API 。
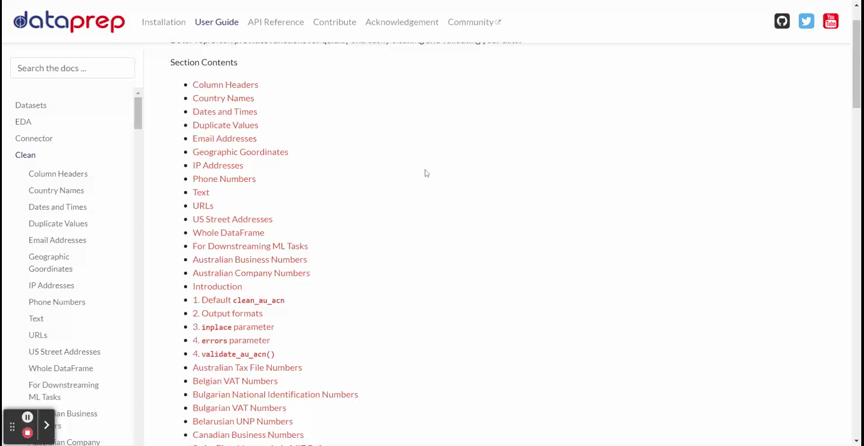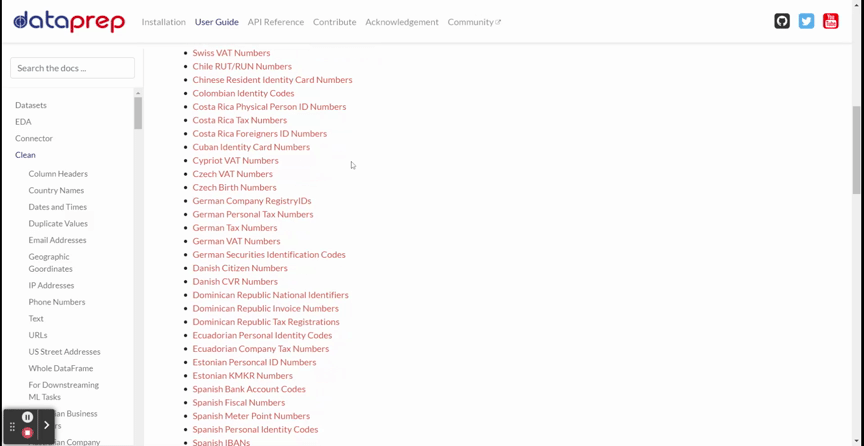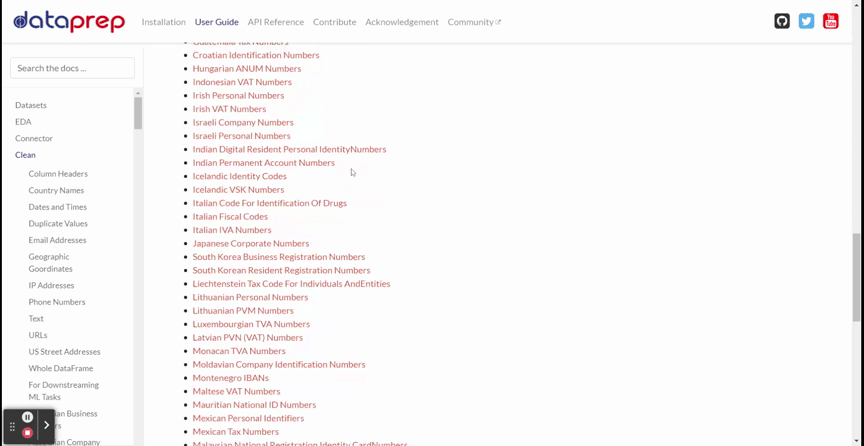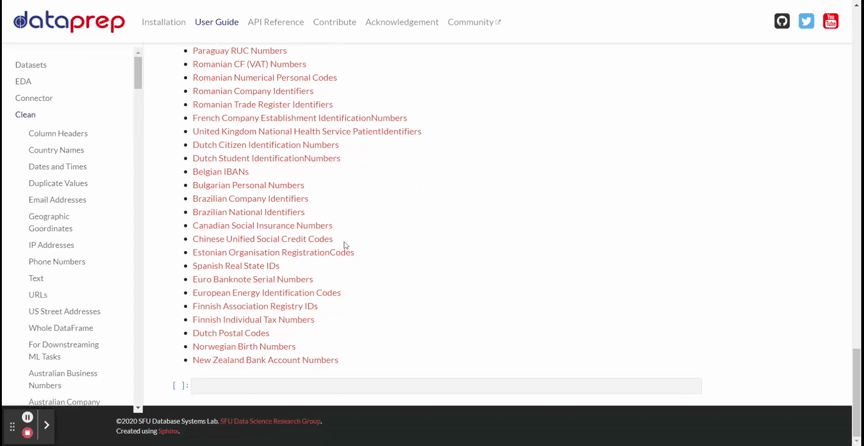
你可以从上面的 GIF 中看到,有多种 API 可供使用,例如列标题、国家名称、日期和时间等等。清洁所需的所有 API 都在那里。
如果你不确定要清理什么,您可以选择用DataPrep 中的clean_df API 自动清理你的数据,并让包推断你需要什么。让我们上手试一下这个 API, 了解更多信息。
首先,我们需要安装 DataPrep 包。
pip install dataprep安装包后,我们可以在前面的数据集示例中应用clean_df API。
from dataprep.clean import clean_df
inferred_dtypes, cleaned_df = clean_df(review)API 将有两个输出——推断的数据类型和清理后的 DataFrame。此外,这个过程还会生成数据帧的清理摘要。

上面的报告为我们提供了处理了哪些数据类型、已清理的列标题以及减少了多少内存的信息。如果你觉得清理已经足够,可以将清理后的数据框用到下一步。如果没有,那么你可以测试使用其他的清洁API。
4► scrubadub
Scrubadub是一个开源 Python 包,用于从文本数据中删除个人身份信息。Scrubadub 通过删除检测到的个人数据,并将其替换为文本标识符(例如 {{EMAIL}} 或 {{NAME}})来工作。
目前,Scrubadub 仅支持删除以下个人数据:
- 名字
- 电子邮件地址
- 地址/邮政编码(美国、英国、加拿大)
- 信用卡号码
- 出生日期
- 网址
- 电话号码
- 用户名和密码组合
- Skype/twitter 用户名
- 社会安全号码(美国和英国的国民保险号码)
- 税号 (GB)
- 驾驶执照号码 (GB)
下面,让我们尝试用 Scrubadub 清理我们的示例数据集。首先,我们还是需要安装包。
pip install scrubadub正如我们在上图中看到的,我们可以用 Scrubadub 删除各种个人数据,例如姓名和电子邮件地址。让我们用一个包含姓名和电子邮件个人信息的数据样本。
审查['replyContent'].loc[24947]
数据包含了我们要删除的姓名和电子邮件数据。让我们使用 Scrubadub 来完成它。
review['replyContent'].loc[24947]
清理后,数据将电子邮件数据删除并替换为了标识符 {{EMAIL}}。但是,数据中的名字并没有被识别和替换。那Scrubadub 怎么才能去掉这个名字呢?
为了增强 Scrubadub 名字标识符,我们需要添加来自其他包的名字检测。在这个案例中,让我们添加 TextBlob检测器。
scrubber = scrubadub.Scrubber()
scrubber.add_detector(scrubadub.detectors.TextBlobNameDetector)
scrubber.clean(sample)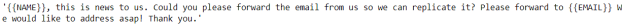
现在,我们成功把名字删除了,并替换成了 {{NAME}} 标识符。你可以浏览Scrubadub包的文档以,更好更深入地了解 Scrubadub。
结论
数据清理是数据科学家工作中花费最多时间的过程。为了帮助清理工作,开发了许多用于数据清理的 Python 包。
在本文中,我介绍了自己最常用的几个数据清理 Python 包;他们是:
- 1. Pyjanitor
- 2. Klib
- 3. DataPrep
- 4. Scrubadub
希望它们能对你的数据科学道路有所帮助!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Cornellius Yudha Wijaya
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/top-data-cleaning-python-packages-e6bde24b273b





