
数据中常见的偏见问题有哪些?
机器学习模型越来越多地用于做出决策或为决策提供信息。例如,模型可能会影响是否批准贷款的决定、筛选求职简历申请工作等。
此类决定至关重要,所以我们需要确保我们的模型不会出现种族、性别、年龄或任何此类因素的歧视。许多机器学习模型通常可能会无意地出现偏见,从而导致了结果的不公,失去可靠性。构建和评估一个好的机器学习模型,需要做的不仅仅是计算损失相关的指标。在运行模型之前,重要的是要分析训练数据,有时还要分析数据源来寻找偏见。

在本文中,我们将深入探讨训练数据中可能出现的不同类型的偏见。在如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
教你如何用神经网络和机器学习进行动态定价
Machine Learning知识点:机器学习里的聚类分析技巧
三个月如何搞定机器学习的数学原理?
研究了2000+笔记本,我们总结了最适合机器学习、数据科学和深度学习的电脑
1. 报告偏见
Reporting Bias
报告偏见(也称为选择性报告偏见)发生在部分结果或数据捕获的结果中,通常只会涵盖整个实际数据的一小部分。这是因为,人们汇报的信息往往会少于所有的可用信息。
报告偏见有以下几种类型:
- 1) 引用偏见(Citation bias):当你的分析是基于其他人的研究引用时。
- 2) 语言偏见(Language bias):忽略了非母语的报告。
- 3) 重复发表偏见(Duplicate publication bias):某些研究因在多个地方发表而权重更大。
- 4) 定位偏见(Location bias):某些研究比其他研究更难定位。
- 5) 发表偏见(Publication bias):正面结果的研究比有负面结果/没有显着发现的研究更有可能被发表。
- 6) 结果报告偏见(Outcome reporting bias):有选择性地报告某些结果。例如,你只在公司季度报告中报告正收益。
- 7) 时间滞后偏见(Time lag bias):一些研究需要数年才能发表。
2. 自动化偏见
Automation Bias
自动化偏见是人类倾向于支持自动化系统产生的结果或建议,而忽略非自动化系统产生的矛盾信息,尽管后者是正确的。
3.选择偏见
Selection Bias
当数据的选择方式不能反映真实情况下的数据分布时,就会出现选择偏见。这是因为在收集数据时不够随机。
选择偏见有以下几种类型:
- 1) 抽样偏见(Sampling bias):在数据收集过程中不够随机。
- 2) 偏见(Convergence bias):选择的数据不够具有代表性。例如,当你只调查购买了你产品的客户,而没有调查未购买产品的客户来收集数据时,你的数据集不能代表未购买你产品的人群。
- 3) 参与偏见(Participation bias):数据由于数据收集过程中的参与程度不同而不具代表性。
假设苹果推出了新 iPhone,而三星在同一天推出了新的 Galaxy Note。你向 1000 人发送调,收集他们的评论。现在,你没有随机选择评论进行分析,而是决定选择对你的调查做出回应的前 100 位客户。这就导致了抽样的偏见,因为前 100 位客户很有可能对产品过于期待,从而给出好评。
接下来,如果你决定通过撇开三星客户,只调查 Apple 客户而收集数据,那么你的数据集就会出现收敛偏见。
最后,如果你将调查分别发送给 500 位 Apple和 500 位三星客户。400 名 Apple 客户回应,但只有 100 名三星客户回应。那么,该数据集将无法代表三星客户,这就属于参与偏见。
4. 过度概括偏见
Overgeneralization Bias
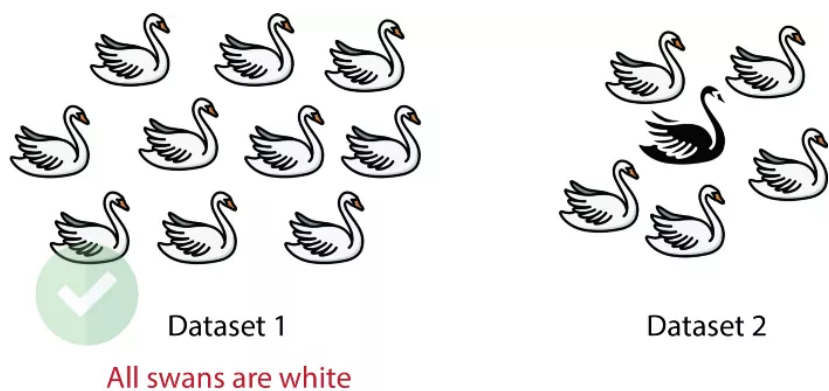
过度概括偏见,当你假设在一个数据集中看到的内容,会和其他评估相同信息的数据集时的内容一样,就会出现这种偏见。如上图,当你看到一个数据集中只有白天鹅,就以为其他数据里也只有白天鹅。
5.群体归因偏见
Group Attribution Bias
人们往往会因为群体中少数人的行为而对整个群体产生刻板印象。这种将个人情况概括为他所属的整个群体的倾向,就被称为群体归因偏见。
群体归因偏见有以下几种类型:
- 1) 群体内偏见(In-group bias):即偏向与你所属或有共同兴趣的群体的成员。例如,为数据科学家职位设置工作描述的经理,认为合适的申请人必须拥有硕士学位,因为这位经理也拥有硕士学位(与他们的工作经验无关)。
- 2) 群体外偏见(Out-group bias):即你对你自己不属于的群体中的个体成员有刻板印象。例如,为数据科学家职位设置工作描述的经理(拥有硕士学位)认为,没有硕士学位的申请人没有足够的专业知识来担任该职位。
6.隐性偏见
Implicit Bias
基于个人经验做出的假设,不一定适用于普遍的情况。人们倾向于根据偏见和刻板印象行事,但并不是有意而为之的。
例如,一位来自北美的计算机视觉工程师将红色标记为“危险”。但是,同样的红色,在中国文化中却非常流行,象征着幸运、欢乐和幸福。
隐性偏见有以下几种类型:
1)确认偏见或实验者的偏见(Confirmation bias or experimenter’s bias):倾向以确认或支持一个人先前的信念或经验的方式来搜索信息。例如,你训练了一个模型,该模型通过某些功能,根据跑车的速度进行排名。你的模型结果表明,法拉利比福特快。然而在几年前你记得看过一部福特跑赢法拉利的电影,所以你觉得福特比法拉利快,然后继续训练和运行模型,直到模型给出你认为的结果。
感谢阅读!如果有任何其他问题,欢迎通过各个渠道联系我们。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Swapnil Kangralkar
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://swapnilin.medium.com/types-of-biases-in-data-cafc4f2634fb




