
五大原则判断是否要用Clustering
Clustering是最广泛使用的无监督学习形式之一。它是用于理解未标记的数据以及将数据分组到类似组中的一个很好的工具。强大的Clustering算法可以处理对于人眼不明显的数据集中的结构和模式! 总的来说,Clustering是一个非常有用的工具,可以添加到你的Data Science工具包中。
但是,Clustering并不总是适合数据集。如果你有兴趣通过Clustering进入无监督机器学习的世界,请遵循以下五个简单的指导原则来查看Clustering是否真的是适合数据的解决方案:
1. 数据是否已有潜在的类别标签?
在数据中使用现有的类标签通常比尝试Clustering为数据创建新标签更好。 如果你有选择权,有监督的Machine Learning几乎总是优于分类任务中的无监督学习。
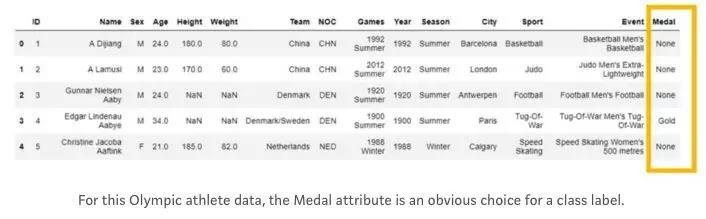
如果你有数据但是无法将数据组织成有意义的组,那么Clustering便是有意义的。 但如果你的数据集中已有直观的类标签,则Clustering创建的标签可能无法与原始类标签相媲美。
2. 数据是Categorical还是Continuous的?
许多Clustering算法(如DBSCAN或K-Means)使用距离来计算观测值之间的相似性。 因此,某些聚类算法在Continuous变量下表现更好。但是,如果你有Categorical数据,则可以对属性进行One-hot编码或使用为Categorical数据构建的Clustering算法,例如K-Modes。 应该注意的是,计算二进制变量之间的距离并没有多大意义。
了解不同的Clustering算法如何在不同的数据类型上执行,对于是否对数据使用Clustering方法至关重要。

3. 数据是什么样的?
使用散点图是简单地可视化数据的方法,同时可以深入了解数据是否适合Clustering。例如,下面是奥运会运动员身高和体重的散点图。 显然,除了少数异常值之外,这两个属性具有强烈的正相关性并形成密集的中心分组。
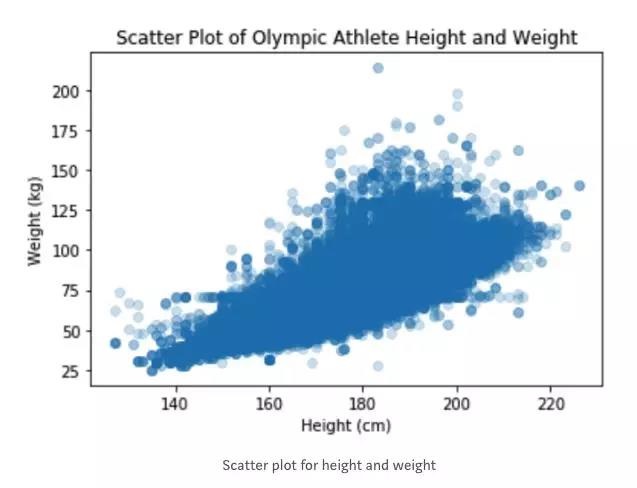
在对此数据运行多个Clustering算法后,没有形成明显或有意义的组,因此确定这些属性不适合Clustering! 然而通过在分析的早期简单地可视化数据,可以更快地得出这个结论。
如果可视化数据没有明显的分离或形成不同的组,则Clustering可能不合适。
4. 有办法验证你的Clustering算法吗?
为了信任聚类算法结果,你必须有一种方法来衡量算法的结果。 可以使用内部或外部验证指标验证Clustering的算法性能。
内部验证的一个例子是Silhouette评分,一种衡量每个观测值被聚类程度的方法。Silhouette图显示了Clusters的相对大小,平均Silhouette得分以及观测值是否被不正确地Clustered。 下图中的红线表示六个Clusters的平均Silhouette得分:约为0.45(1表示完美,0.45表示不是很好)。
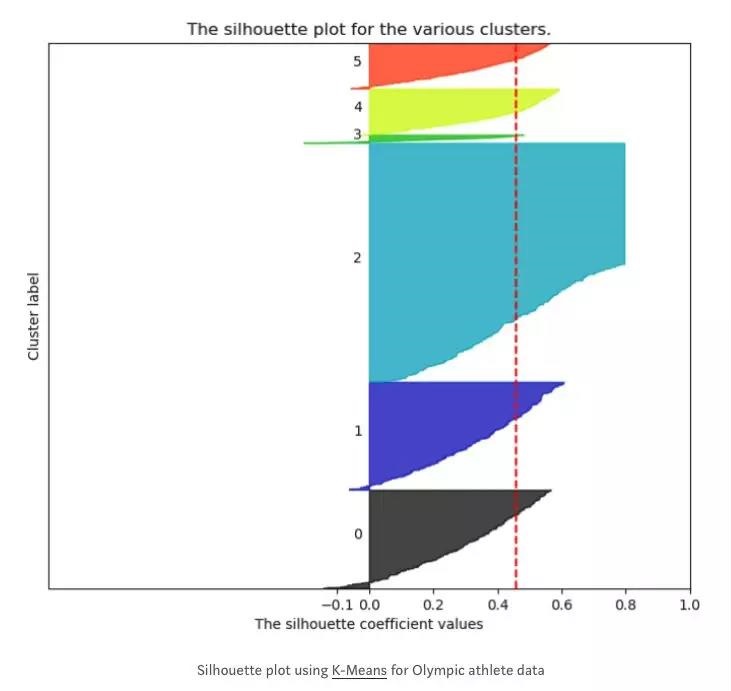
外部验证的一个示例是,当数据集的类标签已知时,你希望测试特定Clustering算法在预测现有类时的执行情况。 对外部验证方法的一个值得注意的警告是,如果数据已经有类标签,那么再使用Clustering的例子就不多了!
为了对Machine Learning模型有信心,你必须具有一致的度量标准来衡量模型性能。Clustering也不例外。 你必须有一种方法来定量评估模型对数据进行Clustering的程度。
在进行聚类分析之前,需要考虑哪种类型的验证以及哪种指标对数据最有意义。 某些算法可能会使用某些验证指标欺骗性地显示相对较好的结果,因此你可能需要使用多种性能指标组合来避免此问题。 如果你始终获得较差的模型性能,那么证明Clustering不适合你的数据。
5. Clustering是否提供了对数据任何新的总结?
假设满足以上所有考虑因素:拥有没有类别标签的连续数据,可视化数据并且存在一些分离,选择了对你的分析有意义的验证度量标准。你对数据运行Clustering算法并获得相当高的Silhouette分数。但是还不够,在执行Clustering分析之后,检查各个聚类中的观测值至关重要。 这一步评估Clusters是否提供对数据的任何新的总结。算法是否真的找到了相似的观测值并最大化了类内相似性,同时最小化了Cluster的相似性?
检查Clusters的一种简单方法是计算每个Clusters中观察值的简单统计量,例如均值。以下是使用K-Means Clustering 算法对于奥运会运动员产生的三个Clusters的平均身高和体重。
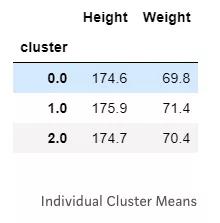
有注意到什么奇怪的地方吗? 平均高度和重量几乎相同。 这表明,虽然算法确实对数据进行了Clustering,但这些Clusters并没有显著不同! 如果Clustering无法对数据产生任何新的或有用的见解,那么数据就不适合Clustering。

与任何Data Science任务一样,不能只是简单的在数据上运行算法。 你必须了解你的数据并理解算法的最初意图。即使数据不适合Clustering,你仍然可以尝试。这对于探索数据并不会造成伤害,同时你也可能学到新东西!
感谢阅读,以下网址可以找到本文中使用的示例数据集。https://www.kaggle.com/heesoo37/120-years-of-olympic-history-athletes-and-results
原文作者:Mallory Hightower
翻译作者:Yishuo Dong
美工编辑:过儿
校对审稿:Yishuo Dong
原文链接:https://towardsdatascience.com/when-clustering-doesnt-make-sense-c6ed9a89e9e6





