
Google新AI模型为何举足轻重
随着前沿AI模型表现出停滞迹象,新模型只是渐进的改进而不是突破性升级,小型语言模型(SLM)现在备受关注。
关键是,Google的新模型Gemma2-27B以66倍的缩小规模大幅度击败了原版GPT-4,而其较小的9B版本基本上匹敌了后者的实力,成为首个达到GPT-4水平的小于100亿参数的模型。
毫无疑问,Gemma2现在是行业中性价比最高的语言模型系列。
然而,真正令我对这些模型感到兴奋的是,出于下文提到的原因,这类模型,而非ChatGPT、Gemini或Claude,将引领全球GenAI的普及。
但为什么呢?如果你想了解更多关于人工智能的相关内容,可以阅读以下这些文章:
2024年每个开发人员都需要掌握的生成式人工智能技能
Google的Gemini AI模型:揭开人工智能的未来
世界上最好的人工智能模型:谷歌DeepMind的Gemini已经超过了GPT-4!
我尝试了50种人工智能工具,以下是我的最爱
效用与规模
如果AI是一种宗教,那么规模将是最受崇敬的神之一。
盲目信仰
自2019年初发布GPT-2以来,研究人员意识到,当Transformer架构扩大时会发生神奇的事情。
今天,这种架构是所有AI的支柱,不仅用于建模语言,还用于赋予机器视觉、读心术能力,甚至是机器人技术。
随着规模的扩大,结果变得好的多,“不惜一切代价扩大规模”已经成为许多实验室相当长一段时间以来的执念:几乎就像一种信条。
然而,我们最近遇到了一个瓶颈,自2023年3月发布GPT-4以来,没有出现任何跳跃式改进。
自那时起,其他前沿AI模型如Claude 3 Opus、GPT-4o、LLaMa 3-405B或Claude 3.5 Sonnet都远远超过了原版GPT-4,但与2022年完成训练的模型相比,改进是渐进的。
由于担心被打败,前沿AI实验室相信真正的多模态,即AI模型不仅能够以文本形式接收tokens,而且以视频、图像或音频的形式接收,并能够以真实形式生成这些模态(而不是通过补丁转换来适应LLM这些模态),将提供智能的下一个飞跃。
然而,正如OpenAI推理研究负责人Noam Brown所承认的那样,这种情况并没有发生。
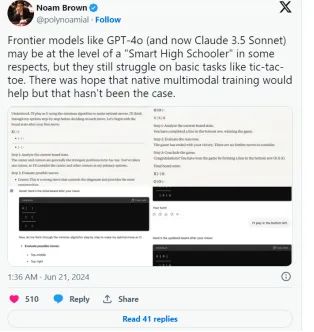
但是,我们公平地说,事实上,这种“瓶颈”可能是一种错觉,因为这些模型的大小并不比GPT-4大多少(如果有的话),根据SemiAnalysis的说法,它们的训练计算量都大致在同一个水平上。
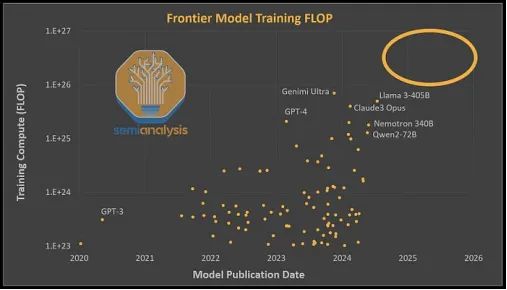
但问题是:虽然市场仍然乐于奖励那些为训练下一大堆矩阵乘法所做的值得称赞的努力,以换取这种所谓的“伟大的AI普及”,但今天这种说法只是一堆空话,几乎没有任何证据支持:
- 根据Mira Murati最近的评论,市场知道更大的AI模型不会很快出现,这种“需求就在眼前,相信我吧”的说法还能维持多久?
- 此外,Microsoft、Alphabet(Google)和Amazon今年迄今增加了1.6万亿美元,超过了澳大利亚2022年的国内生产总值(GDP),而预计2024年GenAI的运行率只有区区200亿美元,比这一数字少80倍,市场还能支撑多久?
但是,没有什么比Apple更能证明收入的缺乏和事情的失控了。
Apple,投资者的生命线
自Apple在6月10日推出Apple Intelligence以来,公司市值增加了4000亿美元,几乎相当于Master Card的整体市值。
有趣的是,这是投资者奖励Apple的一款未发布产品,因此未经测试(在GenAI中这是一个巨大的警告;可以向Google打听),并且令人滑稽的是,这个产品只会向苹果现有客户群的约10%发布。
综上所述,Apple在多个方面巧妙地执行了这一叙述:
- 他们完全避开了使用“Artificial Intelligence”这个词,因为许多人目前非常讨厌这个词,所以他们称之为Apple Intelligence。
- 他们终于给出了升级到更好产品的真实理由,以访问AI,而不是几代人以来的“虽然是相同的,但更薄,现在支付1600美元”。
- 他们提出了一种非常合理的隐私保护方法,大部分任务在设备端或在最先进的私有云中运行
但更重要的是,如果你读过我关于这个主题的文章,你会发现他们提出了一些更符合现实的建议:没有提到AGI,没有夸张,只是一个在你的设备上运行的GenAI模型与云模型配对,只执行少量任务,但具有很高的准确性(再次强调,据称如此)。
然而,尽管存在巨大的不确定性,市场仍然喜爱它。为什么?
简单,因为即使没有人敢说出来,但我们也正处在泡沫中。
例如,红杉资本估计非硬件收入应扩展到6000亿美元以证明资本支出投资的合理性。根据我的估计,2024年非硬件GenAI的直接收入甚至还不到500亿美元(可能在300亿美元左右),这意味着我们处于12-20倍的差距。
祝你好运。
再说一次,投资者知道这一点,这解释了他们为什么对Apple如此疯狂;他们并不是被Apple Intelligence(这在当前AI标准下是一个相当平凡的技术)迷住了,而是迫切希望看到任何可能从GenAI获得收入的迹象。
但我离题了;本文的目的并不是要批评AI的现状。
话虽如此,Apple最近的股票成功是超大规模公司(Microsoft、Google、Amazon)改变策略的另一个原因;他们知道,如果不尽快提供可见的收入,审判日即将来临。
因此,他们都转向了SLM。
但为什么SLM是答案?
效用与幻觉
人工智能需求滞后的原因是企业采用率几乎为零。最大的原因不是成本;这些模型不再那么昂贵了。
主要原因是准确性。
由于它们对真相的完全无视和它们的随机性(幻觉是一个特性,而不是错误),这些模型在任务或过程中很少达到50-70%的准确性,即使使用检索增强生成(RAG)来减少错误的可能性。
对于需要95%或更高准确性的企业工作负载来说,这是不可接受的。正如Lamini.ai的研究所证明的那样,为了减少不准确性(不适当地称为幻觉),我们需要一个模型在训练期间至少运行100次数据。
考虑到其中一些模型每轮训练成本数千万美元,提议进行100轮训练是不现实的。例如,前述研究人员估计,对于LLaMa 3 70 B,进行微调阶段将需要6800万美元。
考虑到该模型比GPT-4或Claude 3小25倍,你告诉我,我们是否很快会看到幻觉消失。
由于所有这些原因,因为没有事实证明幻觉会随着规模的增加而减少,但会随着微调的减少,我预计大多数企业很快将更快地接受SLMs而不是任何前沿模型,因为它们可以被无限地重新训练(并且通过LoRA适配器等技术进行非常有效的训练),甚至在某些情况下进行过拟合,以彻底消除幻觉。
这引出了本文的主要观点:在越来越重要的SLM游戏中,没有什么比Gemma2更胜一筹。
David战Goliaths
在技术层面,最有趣的是他们在一个模型中使用了两种不同类型的注意力变体。
简单说来,Transformer有两个组件:
- 基于注意力层的tokens混合器,基本上处理输入序列。
- 基于MLP层的通道混合器,使模型能够回忆其核心知识,以增强模型的理解并更好地预测下一个词。
多种注意力是你所需要的
虽然标准注意力效果很好,但它相当消耗计算和内存。为了解决这个问题,Google
结合了两种不同的变体:
- 它在层与层之间交替使用局部注意力和全局注意力。换句话说,有些层只处理序列中最后的“k”个单词(在本例中有4096个单词)(滑动窗口注意力),而其他每一层处理整个序列。

为什么要这样做?
虽然局部注意力仍然可以捕捉所有短期依赖关系,但它可能会错过一些重要的长期依赖关系。因此,通过结合这两种注意力机制,模型仍然可以从序列中检索到很久之前出现的重要信息,同时避免了过度计算。
有趣的是,Microsoft也成功探索了在Samba的混合SLM层级(使用Mamba块代替全局注意力)中结合SWA和长程token混合器的方法。
- 他们还使用了分组查询注意力(GQA),这基本上已成为标准,它也节省了大量内存和一些计算开销
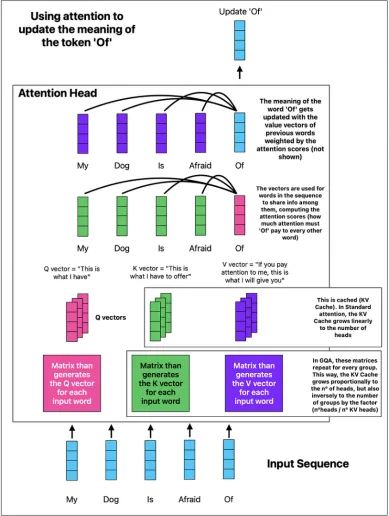
KV缓存存储冗余计算以提高效率。
如上所示,GQA将KV缓存的内存大小减少了一个因子,等于{heads数量/KV heads数量}。在Gemma2–27B的情况下,它有32个注意力heads和16个KV heads,因此模型将其KV缓存大小减少了一半。
考虑到KV缓存是长序列推理中的最大限制因素,在某些极端情况下单个序列的内存需求可达TB级,使用GQA可以大大减少内存限制和延迟。
接下来,值得一提的另一个重要训练适应是2B和9B Gemma2模型不是通过下一个token预测风格训练的,而是通过知识蒸馏训练的。
模仿模仿者
大多数LLM是通过给它们大量文本,遮蔽一些单词,并强迫它们预测缺失的单词来训练的。因此,这些模型被教导在序列中根据前面的单词来预测下一个单词。
然而,当有更强大的模型时,你可以使用该模型来训练较小的模型,并获得‘可比’的结果。这种过程称为‘知识蒸馏’,它改变了我们训练学生模型的目标。
简单来说,它们被教导模仿老师的分布,而不是预测序列中的下一个单词。
通俗地讲,学生模型被迫输出一个可能的下一个单词的概率分布,该分布与老师模型分配的概率相匹配:

这样,虽然模型小得多,但它学会了模仿老师,就像一个小孩子可以通过简单地逐字复述文本来重现‘成人级别的文本’一样。
综上所述,Gemma2取得了哪些实际成果?
独树一帜
Gemma2是一个强大的存在。
同名模型的第二个版本,在1000亿以下参数范围内是一款接近最先进水平的模型,甚至在lmsys聊天机器人排行榜上超过了LLaMa 3–70B,而且其较小的90亿参数模型也能与GPT-4的2023年3月版本匹敌,尽管它小了200倍,这真实的表明了我们在一年多时间里训练方法的巨大进步:
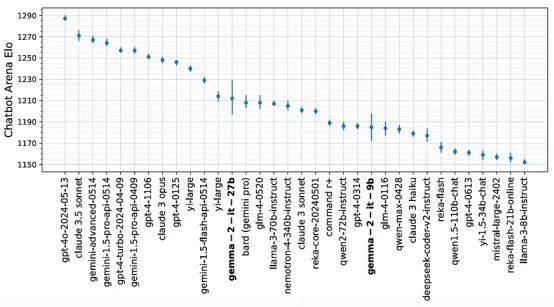
它还展示了非常强的基准测试结果(尽管我更看重LMSYS排行榜,因为它是由真实人群投票而非基于任意分数):
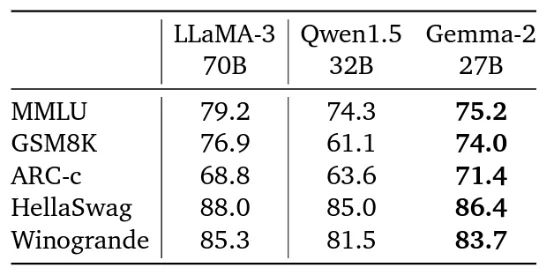
尽管有好消息,但Gemma2模型发布的许可证受到了严重批评,一些人认为由于禁止使用的用例太多,它甚至不是一个开源许可证。
在我看来,这个模型只是开放权重,因为他们没有提供数据集,这是被认为完全开源的必要条件。
寻求采纳者
基于所使用的相当标准的架构,似乎与以前的模型相比,大多数改进都来自于数据,遗憾的是这些数据并未公布。
尽管如此,这些结果仍然值得关注,因为截至撰写本文时,该模型在整体排名中位居前12,尽管比排名前列的其他所有模型都要小得多。
重要的是,出于文章中提到的原因,我认为像Gemma2这样的模型比表面上看起来更为重要,如果我是大公司的CTO/CIO,我更愿意部署针对特定任务进行微调的Gemma2模型,而不是ChatGPT或Claude,后者由于持续的不准确性,更多地成为协作和迭代工具,而不是实际的自动化机器。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Ignacio de Gregorio
翻译作者:文玲
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/why-googles-new-ai-model-is-serious-business-de39b9a184f4



