
长上下文LLM会使RAG过时吗?
大型语言模型(LLM)的快速发展对人工智能领域,尤其是自然语言处理(NLP)产生了深远的影响。传统上,诸如检索增强生成(Retrieval-Augmented Generation,简称 RAG)这样的技术,通过允许模型动态访问外部知识源,在增强 LLM 能力方面起到了重要作用。然而,随着长上下文 LLM(能够处理多达 100 万个令牌的上下文窗口的模型)的出现,一个有趣的问题浮现出来:长上下文 LLM 是否会使 RAG 过时?
在本文的深入分析中,我们将探讨 LLM 上下文窗口的工作机制,分析为什么需要超长上下文窗口,检视 RAG 的原理,并比较这两种方法的优劣。此外,我们还将讨论关键因素,包括准确性、延迟、可扩展性,以及更大的模型是否能更好地处理历史数据和记忆。我们的目标是评估某一种技术是否会取代另一种,抑或两者结合的混合策略才是 AI 应用的未来方向。
如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
大语言模型:AI如何改变医疗现状
为什么大语言模型不适合编码?
AI驱动的财务分析:多代理LLM系统将数据转化为见解
2024年打造生产级LLM应用的最佳技术栈
理解 LLM 的上下文窗口
什么是上下文窗口?
在 LLM 中,上下文窗口是指模型在一次输入中可以处理的最大令牌数量(包括单词或子词)。它反映了模型交互期间的“记忆”,涵盖了输入提示和生成的文本。

- 令牌(Token): 文本的基本单元,可以是一个单词或子单词。
- 上下文长度(Context Length): 模型一次可处理的总令牌数量。
上下文窗口大小的重要性
- 信息保留: 较大的上下文窗口能让模型更好地利用先前的信息,从而提高生成内容的连贯性与相关性。
- 复杂交互: 支持处理较长的文档、对话或序列,避免忽略早期细节。
- 限制: 较小的上下文窗口可能导致模型“遗忘”输入的早期部分,生成的响应缺乏连贯性或上下文准确性。
对超长上下文窗口(1M 令牌)的需求
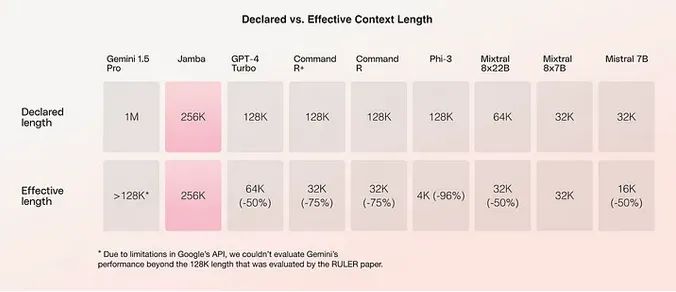
为什么需要 100 万令牌的上下文窗口?
推动超长上下文窗口发展的核心动力是对处理整本书、完整研究论文或大规模日志的需求,而无需分割文本。100 万令牌的上下文窗口可以:
- 处理完整文档: 一次性处理整个文档或数据集,避免分割引发的错误。
- 增强连贯性: 保持长篇段落的上下文完整性。
- 消除分割: 减少由于文本分块带来的上下文流失。
对准确性的影响
- 信息过载: 模型可能难以聚焦于超长上下文中的关键信息,导致准确性下降或“中间遗忘”问题。
- 注意力分散: 在超长上下文中,注意力机制可能失效,难以优先处理相关信息。
- 边际效益递减: 研究表明,超过一定上下文长度后,模型性能的提升逐渐趋缓,甚至可能下降。
更大的模型与历史数据处理能力
- 记忆容量: 参数更多的大型模型在处理历史数据和记忆方面表现更好,因其具备更强的表示能力。
- 训练数据的限制: 如果训练数据中不包含足够的长上下文样本,模型可能无法充分利用扩展上下文的优势。
- 架构创新: 分层注意力、内存压缩等技术为长上下文处理提供了优化潜力。
延迟与计算资源的影响
- 延迟问题: 处理超长序列会显著增加响应时间,不适合实时应用。
- 计算成本: 需要大规模内存和计算资源,提升了硬件要求。
- 可扩展性挑战: 对于需要快速响应的应用,处理长上下文可能不够实用。
探索检索增强生成(RAG)
什么是 RAG?
检索增强生成(Retrieval-Augmented Generation,简称 RAG)通过集成外部知识检索机制,增强 LLM 的生成能力。与直接依赖模型内参数不同,RAG 动态检索外部信息以生成准确且时效性强的响应。
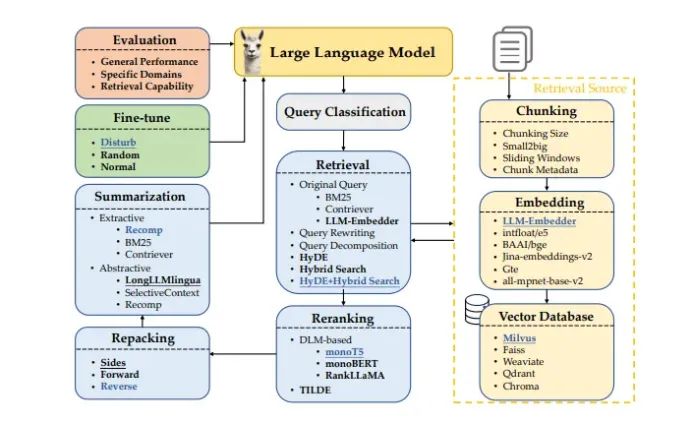
RAG 的工作原理
RAG 的核心架构包括:
- 检索器: 从外部数据库或知识库中检索与查询相关的文档。
- 生成器: 利用查询和检索到的信息生成上下文相关的响应。
RAG 的优点
- 效率高: 检索相关数据避免了不必要的计算,响应更快。
- 可扩展性强: 可处理广泛的知识领域,无需在模型参数或上下文中嵌入所有信息。
- 及时性: 能访问最新数据,非常适合时间敏感的应用场景。
- 计算负担低: 相较于超长上下文模型,处理的数据量较少,计算需求更低。
RAG 的局限性
- 复杂性:集成检索机制会增加系统架构的复杂性。
- 对外部资源的依赖:需要依赖外部数据库的可用性和质量。
- 潜在的延迟:尽管检索步骤可能引入一些延迟,但通常比处理超长上下文的延迟要少。
比较分析:RAG 与长上下文 LLM
为评估长上下文 LLM 是否会使 RAG 过时,我们从以下几个方面进行比较:准确性、延迟、可扩展性,以及对历史记录和内存的处理能力。
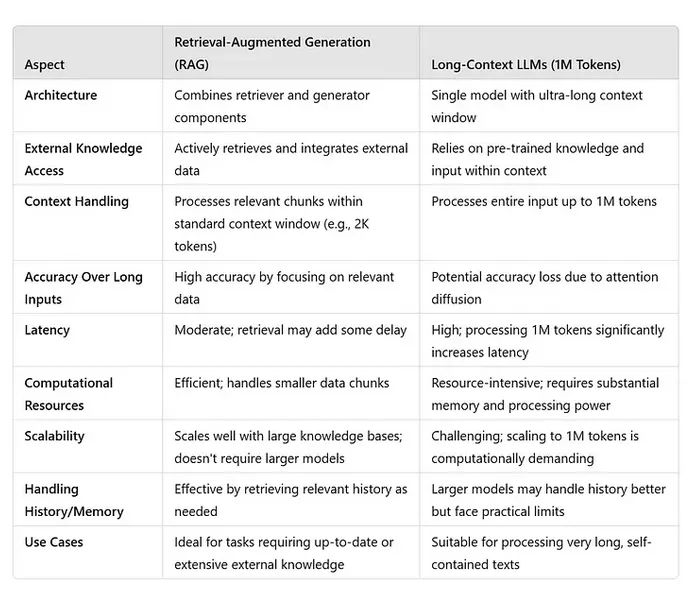
长上下文 LLM 会使 RAG 过时吗?
支持长上下文 LLM 的理由
长上下文 LLM 具备以下显著优势:
- 统一处理:能够一次性处理整个文档或数据集。
- 增强连贯性:在无需拆分文本的情况下,保持长段落的上下文连贯性。
- 简化交互:减少对输入进行分块或拆分的需求。
长上下文 LLM 面临的挑战
尽管如此,长上下文 LLM 也存在一些挑战:
- 准确性下降:在超长上下文中可能失去重点或忽略细节。
- 延迟问题:处理时间显著增加,使实时应用难以实现。
- 计算需求:高计算资源的需求限制了其可扩展性和广泛部署。
- 收益递减:在超过某一上下文长度后,性能提升趋于平缓,甚至可能无法抵消成本。
支持 RAG 的理由
RAG 由于以下独特优势,依然具有重要价值:
- 效率:仅处理相关信息,降低计算负担。
- 可扩展性:无需扩展模型大小或上下文窗口即可处理大规模知识库。
- 准确性:通过专注于检索的相关数据,保持较高的生成准确性。
- 延迟优化:尽管检索步骤引入一定延迟,但通常低于处理超长上下文的延迟。
延迟与可扩展性对比
- RAG:通过处理更小的数据块,实现更高的可扩展性和更低的延迟。
- 长上下文 LLM:因处理 100 万令牌的高计算需求,在可扩展性方面存在挑战。
对更大模型与历史处理的分析
- RAG:可以动态检索并提供相关的历史数据,而无需增加模型大小。
- 长上下文 LLM:更大的模型可能更好地处理历史数据,但在训练和部署时受到实际限制。
潜在的混合方法
与其让一种方法完全取代另一种方法,不如采用一种融合两者优势的混合策略:
- 将 RAG 与长上下文 LLM 集成:使用 RAG 检索相关数据,并将其提供给长上下文 LLM 进行处理。
- 动态上下文管理:通过智能检索机制,动态填充上下文窗口中最相关的信息。
- 优化注意力机制:开发高效的注意力机制,集中处理必要数据,减少资源浪费。
结论:长上下文 LLM 是否会使 RAG 过时?
长上下文 LLM 通过能够处理极长的输入,为自然语言处理(NLP)领域带来了重大进展。然而,它们也面临着准确性下降、延迟增加和计算成本过高的挑战,在某些应用中显得不够实际。
另一方面,RAG 专注于相关信息的检索,仍然是一种高效、可扩展且准确的解决方案。相比一次性处理海量数据,RAG 通过减轻计算负担和减少延迟,提供了更加务实的选择。
考虑到目前的技术现状和实际需求,长上下文 LLM 不太可能完全取代 RAG。未来可能会采用一种混合模式,结合两种方法的优势:
- 效率:通过 RAG 管理计算需求。
- 连贯性:在需要处理长输入时,利用长上下文 LLM 保持上下文连贯性。
- 准确性:通过整合集中检索与扩展上下文的优势,提升生成的准确性。
最终展望
人工智能领域的快速发展,使长上下文 LLM 和检索增强生成(RAG)都成为 NLP 的重要进步。在未来,我们应聚焦于开发能够:
- 高效处理大规模上下文:在上下文长度与计算可行性之间实现平衡。
- 精准获取外部知识:进一步优化检索机制,确保实时获取相关信息。
- 优化性能:通过架构创新,处理更长的上下文,同时降低资源需求。
长上下文 LLM 与 RAG 的结合可能是人工智能应用实现更加丰富且准确解决方案的关键。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Mastering LLM (Large Language Model)
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://masteringllm.medium.com/will-long-context-llms-make-rag-obsolete-17ddbc6f6412




