
终极Python可视化清单
Python是数据分析的重要工具之一。人们经常用这个工具将数据转化为有意义的图像。本文以代码和示例的形式,用清晰、有条理的方式列出了你日常最需要的图表内容。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据科学必备清单:22条最常用Python代码,快收藏!
用Python进行探索性数据分析(EDA)实例——扒了200多天的2万条聊天记录,我发现了群聊的秘密
Python中的高效编程:Lambda/Map/Filter/Sorted
教你轻松地创建漂亮的、可自定义的图表
本文以代码和示例的形式,用清晰、有条理的方式列出了你日常最需要的图表内容。在创建任何图表前,你可以快速浏览这份指南,在脑海中构思一下想做的可视化效果。毕竟,你能呈现给观众的信息,是会受你的图表包含的内容所限制的。
■ 数据可视化的步骤
- 根据你图表的维度准备相应的数据。比如,分布图distribution plot只有一个维度,而箱形图boxplot有两个维度,以此类推。
- 打开和图表美学相关的内容,比如样式或者色板。
- 创建图表。
- 使用标题、标签或其他功能来自定义图表。
■ 导入Library
我们会加载两个目前最流行的Python绘图库—– matplotlib和seaborn。我们会用它们的通用缩写名:plt和sns,以便在无需输入它们完整冗长的名称的情况下,快速访问它们的功能和属性。
import matplotlib.pyplot as pltimport seaborn as sns
■ 启动Graph World
在创建图形时,需要指定出图形的大小。
plt.figure(figsize=(horizontal_length,vertical_length))Seaborn styles可以在图表中添加网格和样式。seaborn中有四种样式,你可以用.set_style加载。
sns.set_style(name_of_style)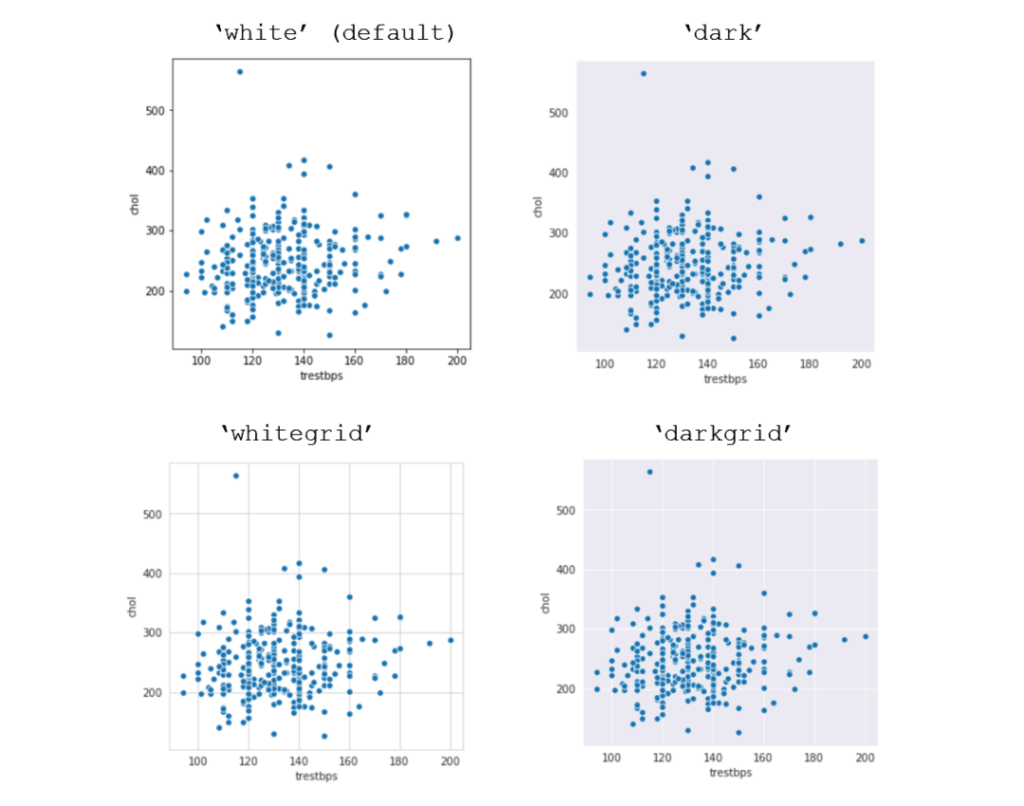
Seaborn contexts是内置预设的软件包,可以显示你想要的绘图外观,这会改动标签、线条、和一些其他的绘图元素,但不会影响图表的整体样式。
sns.set_context(name_of_context)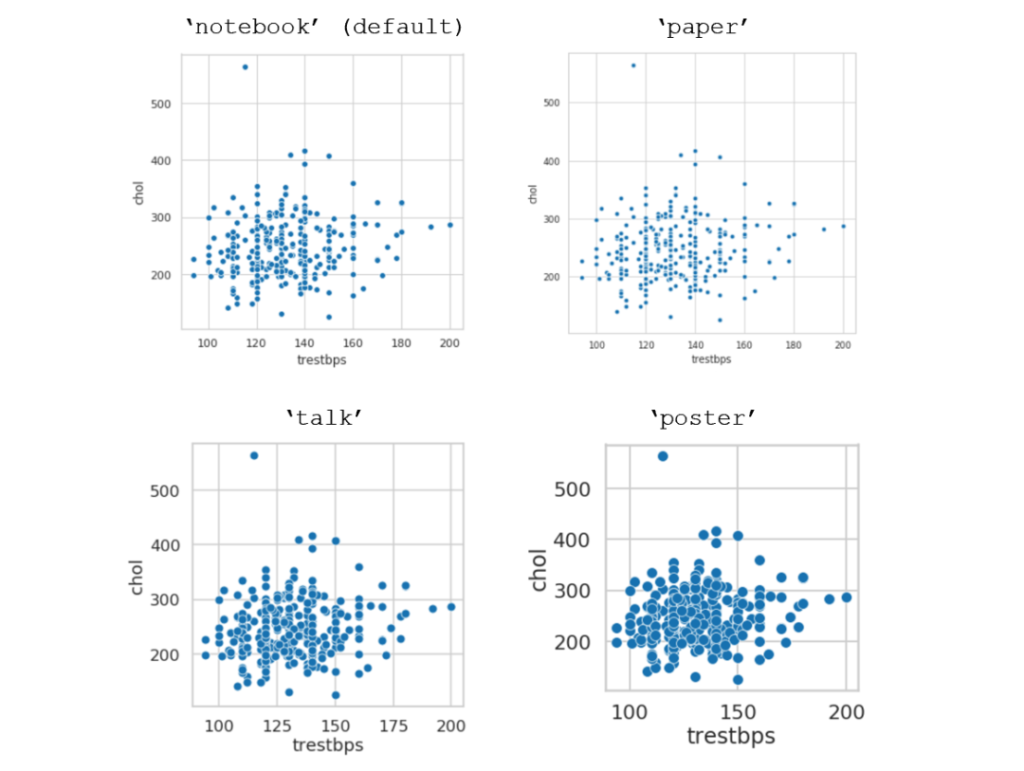
Seaborn color palettes提供了一组颜色,可以让图表展现出你想要观众体会的内容和环境。
Seaborn有几十种精选调色板。你可以通过以下代码来加载它们。
sns.set_palette(name_of_palette)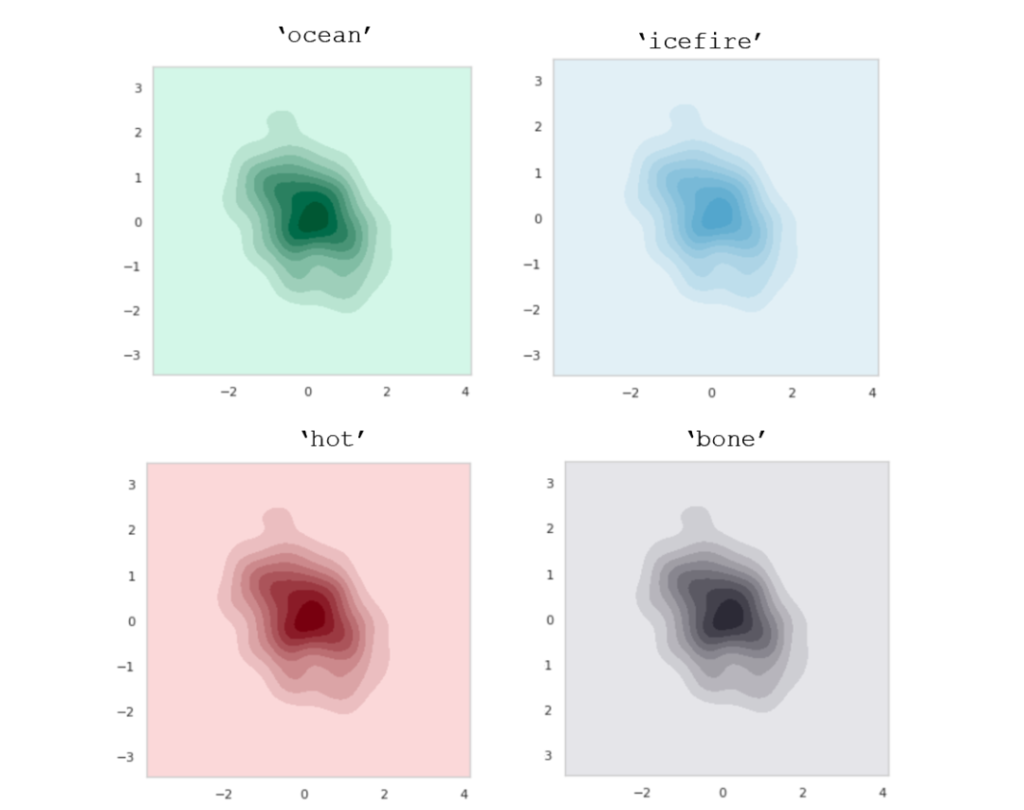
你可以故意输错调色板名字,这样seaborn就会列出它所有调色板的名称:
sns.set_palette('a string deliberately entered to get an error')
然后,你可以使用seaborn的palpot(palette plot调色板图)来查看每个调色板。你传给seaborn的color_palette的第一项内容是调色板的名称;第二项内容是你想显示的颜色的数量。在绘图时,seaborn会自动判断颜色的数量,但你也可以在palpot中控制它。
sns.palplot(sns.color_palette('GnBu', 15))
你也可以通过十六进制颜色码(Hex Codes)来手动设置Seaborn的调色盘:
sns.set_palette(['#ffffff', ...])■ 创建图表
seaborn中的所有图,都是用 sns.name_of_plot(x, y)创建的,具体取决于图的维度数量。像箱形图这样的一维图就只需要x,而散点图则需要x和y。
■ 分布图
分布图一般使用的是单变量数据—-也就是仅有一维的数据,然后用一条线沿着数据点的走势表示。Seaborn对二维分布图进行了适配,能够同时显示两个分布图。
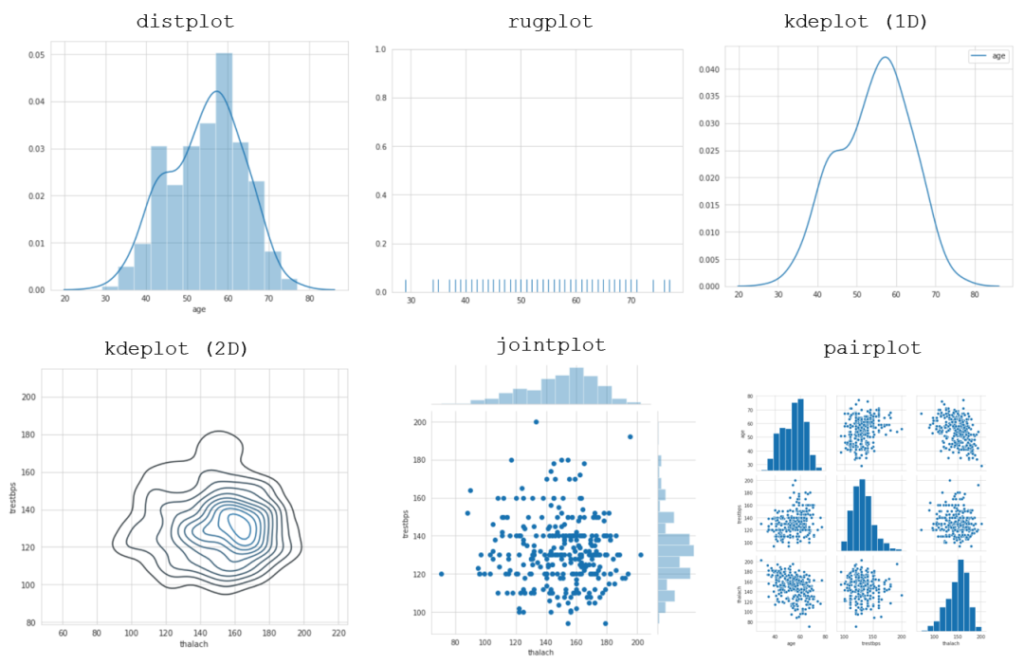
- Distplot可以用来绘制带直方图的一维kdeplot。
- Rugplot通过绘制刻度线的点,来展示数据点的聚类情况。
- 当输入一维数据时,kdeplot可以绘制分布曲线。在输入二维数据时,它能绘制出等高线图。
- Jointplot可以绘制一个散点图,图的每个边都带有直方图,显示相应维度的信息。
- pairplot通常被用来进行探索性数据分析(EDA)。它能绘制出各个维度间相互的数据关系,并在变量与自身作用的时候绘制出一个直方图。上图采用了pandas里的一个数据集。
■ 定量Quantitative和定性Qualitative的变量关系
以下这些图结合了两种类型的变量—-定量变量(例如13、16.54、94.004等连续数字)和定性变量(如红色,蓝色,男性,离散等等)。
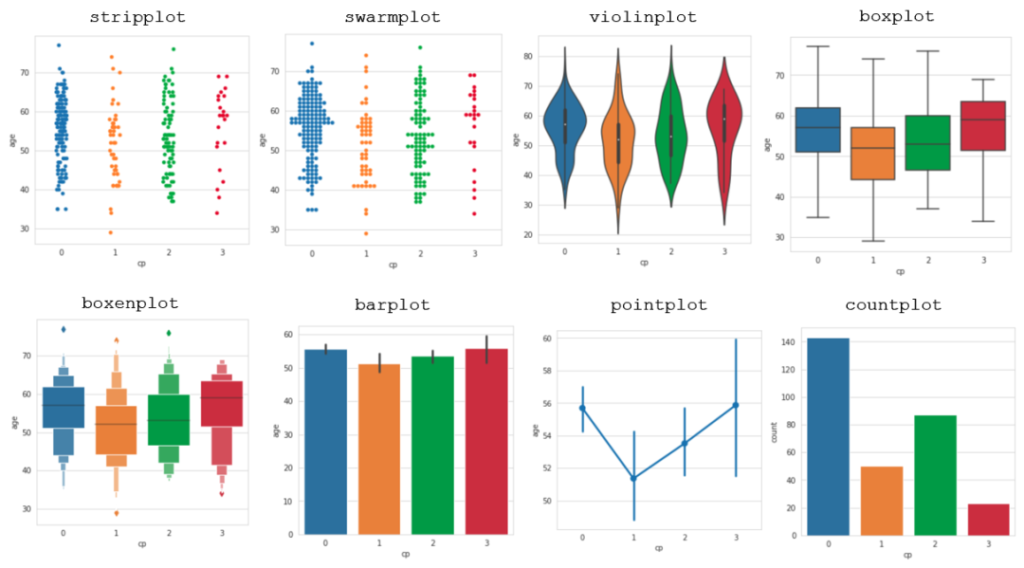
- stripplot 能水平地绘制垂直的数据点,以便看到值相同的多个数据点。这需要用到定性的x和定量的y。
- 与stripplot类似,swarmplot也是用水平的方式绘制垂直数据点,但绘制方式更有条理。它用结构化的方式消除了数据点重叠的问题。
- violinplot在两个定量轴的方向绘制分布图,它被人们认为是boxplot的有利替代方案。
- boxplot绘制了数据的五数概括法(Five-number summary) —– 最小值,第一四分位数(第25个百分位数),中位数,第3四分位数(第75个百分位数)和最大值。缺点是,它有隐藏不规则分布的倾向。
- boxenplot通过在箱形图顶部的拓展,来更准确描述数据的分布。
- 标准的barplot绘制与数据相应的高度的条形图。Countplot可以表示相同的可视化效果,但只会使用一个变量,并展示每个不同值出现的次数。
- Pointplot会找到带有适当误差线的点,来适当地表示这个数组。这种图非常适合用来比较数字形式的定性变量。
■ 定量关系
下列图显示了两个定量变量之间的关系。
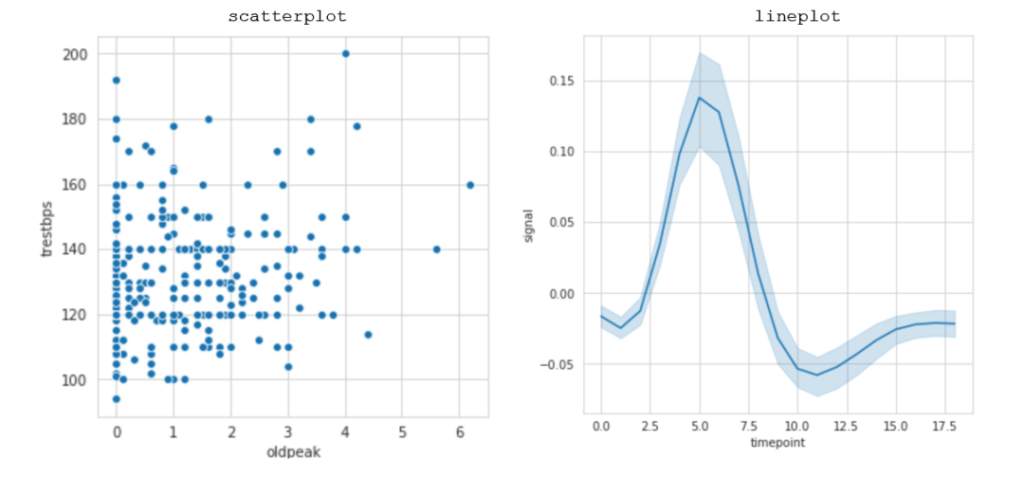
- scatterplot绘制了两个定量变量相互的关系。
- lineplot沿着时间变量绘制了一个定量变量,这里的时间变量可以是定量的,也可以是日期的形式。
■ 统计模型
统计模型的可视化利用了统计模型的特点来可视化数据的性质。
在许多统计模型可视化中,都可以用一些参数来调整可视化的性质。
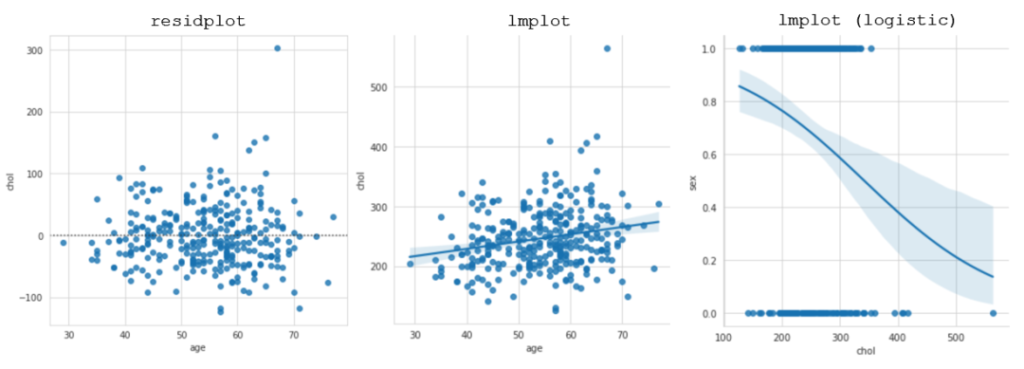
- residplot显示线性回归的残差(即每个数据点偏离线性回归拟合的距离,这里是欧几里得距离)。
- lmplot在散点图上显示了置信区间的线性回归拟合。这个图具有几个参数(在这里我们可以把它看做长度),这些参数可以用来调整图的性质。例如,设置logistic = True,就能把y变量假定为二进制,并创建Logistic(S型)回归模型。
■ 自定义图表
对图表的自定义,包括在图的顶部添加内容,来增加可读性或信息。
可以使用这两个命令来添加x轴和y轴的标签:plt.xlabel(’X Label’)和plt.ylabel(’Y Label’)。
可以使用plt.title(’Title’)来添加标题。
可以用plt.xticks(rotation = 90)旋转x轴刻度线,用yticks旋转y轴刻度线,这里的90 可以用任何你想用的度数代替。
可以用plt.xlim(lower_limit,upper_limit)和plt.ylim(lower_limit,upper_limit)指定轴上数值的范围。轴上显示的所有值都会在你指定的区域之间。它们还能用来为图形设置合适的y轴基线。
如果图表中没有默认的图例,你可以用plt.legend()添加图例。你还可以用参数loc来指定图例所在的位置。默认情况下,matplotlib会帮你找到最佳位置,让它与数据点不重叠。
你能很容易地用plt.show()来显示图表。尽管这不是完全必要的,但它可以避免一些matplotlib和seaborn显示的文本,并最终化图表。
除了本文给大家总结的知识点之外,本周六我们也为大家准备了直播课程,欢迎扫描图片二维码报名!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Andre Ye
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/your-ultimate-python-visualization-cheat-sheet-663318470db




