—-你需要知道这3个指标.jpg "评估回归模型(Regression)— 你需要知道这3个指标")
评估回归模型(Regression)— 你需要知道这3个指标
基于回归的机器学习模型(Regression-based machine learning models)被数据科学家们用来预测连续属性的值。
和所有监督机器学习(supervised machine learning)问题一样,回归模型会用一组特征 (X) 进行训练,学习到目标变量 (y) 的影响。在回归分析中,我们的目标是一个连续变量,例如:房子的价格。
可以说,最简单的回归算法就是线性回归(linear regression)了。简单的线性回归只包含有一个特征和一个目标,由下面显示的等式表示。
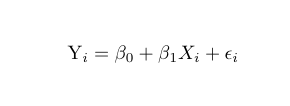
举个简单的例子,假设我们想根据一辆车的马力来预测汽车的每加仑的英里数 (MPG)。在这种情况下,公式中各个符号会是下面这些情况:
- Yi表示目标变量或 MPG。
- Xi代表特征,在这种情况下,代表马力。
- β1是马力将乘以的系数或值。
- β0是直线与 y 轴的交点,参考文章后面的图。
- εi是模型中的误差,用来衡量估计关系的方差。
我们可以使用Seaborn Python 库,为这个问题绘制一个简单的线性回归。
import numpy as npimport seaborn as snsimport matplotlib.pyplot as pltmpg = sns.load_dataset('mpg')sns.regplot(x='horsepower', y="mpg", data=mpg).set_title('Simple Linear Regression')
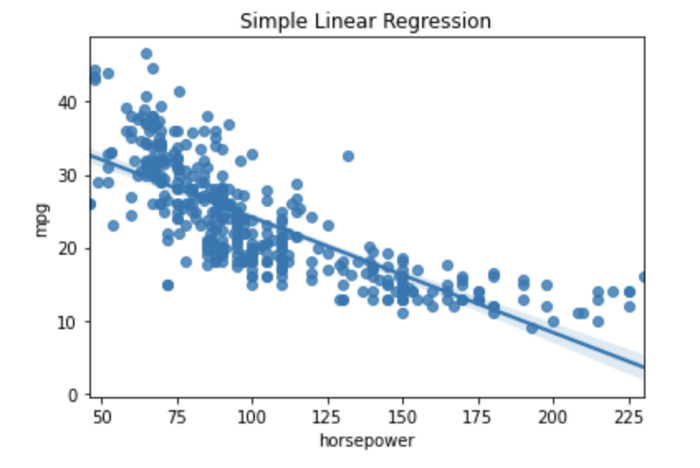
上图中的线代表了我们预测的值。我们可以看到,并非所有数据点都完全符合这条线,这些点代表了模型中的错误。线性回归的目标是通过确定β0和β1的最佳值,来最小化该误差的大小。
和任何机器学习问题一样,会有几个指标用来确定模型的整体性能。换句话说,模型在最小化整体误差方面的表现有多好?在本文的剩余部分,我将分享三个可用来评估回归模型的性能的指标。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
数据分析新工具MindsDB–用SQL预测用户流失
DS数据科学家和DA数据分析师:要学习什么不同内容?
数据分析师需要知道的10个Excel函数
数据分析如何在Fintech中发挥作用?
1. R平方()
R平方,也称为决定系数(coefficient of determination),是衡量观察值与拟合回归线之间的接近程度的指标。因变量会包含一定数量的变化,而 r 平方被用来衡量模型解释这种变化的多少。
让我们再次查看上图,我们可以看到,我们有一条直线表示学习模型。这条线就被称为回归线。然而,很多真实的数据点并没有落在这条线上。这些线与每个观察到的数据点之间的距离就被称为残差(residual)。
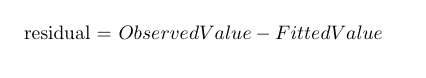
要计算 r 平方,我们要先导出每个数据点的残差,然后对结果进行平方。最后,我们把结果数字加在一起,这成为模型中方差的度量。它的公式通常如下所示。

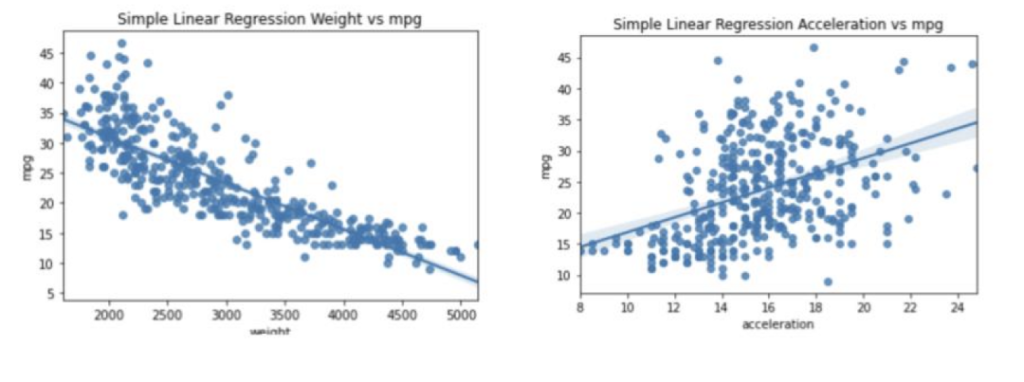
r 平方值范围从 0 到 1,其中 1 分表示模型能够解释因变量中的所有方差。下面的图像比较了两个不同自变量的回归线。我们可以看到,车重量的值在回归线周围聚集得更紧密。
如果我们比较一下 r 平方值,我们也会看到很大的差异。对于车辆重量和 MPG,r 平方值为 0.69。换句话说,该模型能够解释因变量中 69% 的方差。而加速度的 r 平方值要低得多,为 0.18,这个模型只能解释 18% 的方差。
R-squared 很少被单独用来估计模型的性能,因为它没有给出任何偏差的度量。因此,对于有高偏差的模型,可能会有高 r 平方值。这就是为什么我们还需要查看其他性能指标。
2.均方根误差(RMSE)
上文描述的残差也可以被认为是衡量回归模型中的一种误差方式。RMSE 本质上衡量了这些残差分布程度的指标,它也是量化回归模型整体误差的标准方法。
我们要首先计算均方误差 (MAE) ,才能计算 RMSE。你要先获取代表因变量的每个数据点的残差,并将它们的值平方。然后将结果值相加,并除以总点数减去 2。RMSE 就是这个最终数字的平方根。
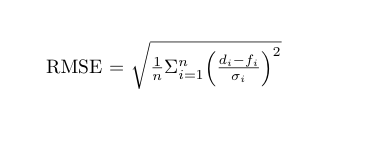
RMSE 越小,模型与数据的拟合就越接近。RMSE通常被作为解释模型的最佳方法之一,因为它有与因变量相同的单位。
RMSE 的一个潜在缺点是,由于它的计算方法,针对 RMSE 的优化将比其他的度量方法更加惩罚大型的错误。因此,当我们特别不希望模型出现大误差时,它是最有用的。
RMSE 分数“好坏与否”没有标准,因此,与基准分数(例如用朴素模型生成基线)相比,它是更有用的。
3.平均绝对误差(MAE)
MAE 是另一种衡量预测值与观测值的距离的方法。它与 RMSE 相似,因为它的单位也和因变量的单位匹配。然而,在 MAE 分数中观察到的变化会是线性的,因为 MAE 的值将随着误差的增加而增加。因此,MAE 不会更加惩罚较大的错误。
MAE 的指标始终是正数,数字越小,说明模型的拟合效果越好。和 RMSE 一样,没有一个标准的“好”分数,因此,要记得用这个指标和基线模型进行比较。
MAE 的计算方法是:首先对残差的绝对值求和,然后将结果除以观察的总数。
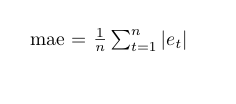
和其他机器学习问题一样,不会有单一的最佳指标来评估回归模型的性能。你选择的指标将取决于训练模型的数据,以及模型的使用方式。考虑到偏差的风险、错误的大小、以及在实践中使用模型时可能产生的影响,在大多数情况下,我们通常需要用几个不同指标来评估整体性能,并且,通常与基准进行比较是最有用的。
在本文中,我简单介绍了三个最常用的回归评估指标。当然还有更多指标可以选择,sckit learn 就介绍了一个很好的列表,其中列出了可以在此处使用的其他指标:
https://scikit-learn.org/stable/modules/model_evaluation.html
感谢你的阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Rebecca Vickery
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/3-evaluation-metrics-for-regression-80cb34cee0e8





