
通过案例数据集,带你了解Python数据分析和数据可视化
想要了解一组数据的特征,我们需要选择数据量、数据中的变量总数等基本方面来总结数据;同时也要识别数据问题,例如缺失值、不一致和异常值等等。
在本文中,我将向你展示如何用“房价数据集”进行一些简单的数据可视化,你可以从 Kaggle ( https://www.kaggle.com/ ) 获得这个数据集,上手练习。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
10个Python函数,帮你解决70%的数据分析问题
手把手教你用Python创建SQL数据库!
5个鲜为人知的 Python 库!帮你的下一个NLP项目起航
从Marplotlib到Plotly: 教你入门Python数据可视化
#Load the data by reading from a from a csv file using the pandas library
#用pandas载入csv文件
import pandas as pd
df_train = pd.read_csv('train.csv')
df_train.head()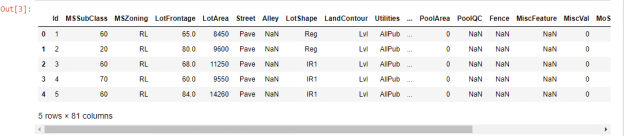
# Size of the data by rows and columns
# 数据库的总行数和总列数
df_train.shape
#Since we are determining houseprices, lets explore the "SalePrice"
#既然我们想要预估房价,我们需要探索“SalePrice”列
df_train['SalePrice'].describe()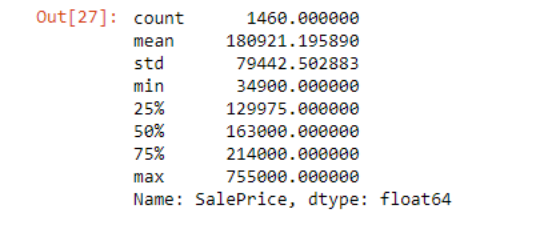
下面,我列出了这个数据集的关键数据可视化任务:
- 在给定范围内,展示“销售价格”的直方图。
- 2.相关矩阵(Correlation Matrix)
- 3.寻找异常值
- 4.散点图(Scatter plots)
首先,我们要导入数据可视化所需的一些库。 Matplotlib 和 Seaborn 是目前最流行的用于数据可视化的 Python 库,当然还有其他一些库可以用,常见的有 Plotly库。
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as sns
from scipy import stats
from scipy.stats import norm, skew, kurtosis
from plotly.offline import download_plotlyjs, init_notebook_mode, plot, iplot
init_notebook_mode()
import cufflinks as cf
import plotly.offline as pyo
cf.go_offline()
pyo.init_notebook_mode()df_train['SalePrice'].iplot(kind='histogram', xTitle='price',yTitle='frequency',colors='darkred')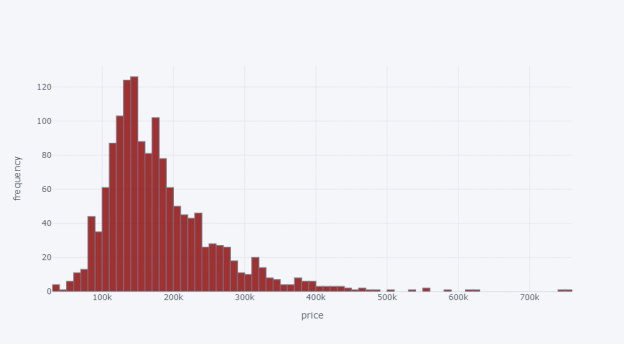
很明显,我们能从上图看出,住宅的“销售价格”大部分在 100,000 美元到 250,000 美元之间。
相关矩阵可以用来汇总数据、作为更高级研究的输入信息、以及作为数据集中变量之间的高级分析诊断。它在特征选择中特别有用,可以用于选择重要特征,同时去除不相关和不需要的特征。相关系数的值介于 -1 和 +1 之间,+1 表示完美的直接(增长)线性链接(相关性),-1 表示完美的逆(下降)线性关系。
#Let the number of the top twelve highly correlated variables = n
n=12
corr = df_train.corr()
cols = corr.nlargest(n,'SalePrice')['SalePrice'].index
cm = np.corrcoef(df_train[cols].values.T)
sns.set(font_scale=1.30)
fig, ax = plt.subplots(figsize=(12, 9))
final_plot = sns.heatmap(cm, cbar=True, annot=True, square=True, fmt='.2f', annot_kws={'size': 10},
yticklabels=cols.values, xticklabels=cols.values)
plt.show()
plt.savefig('Correlation Heat map')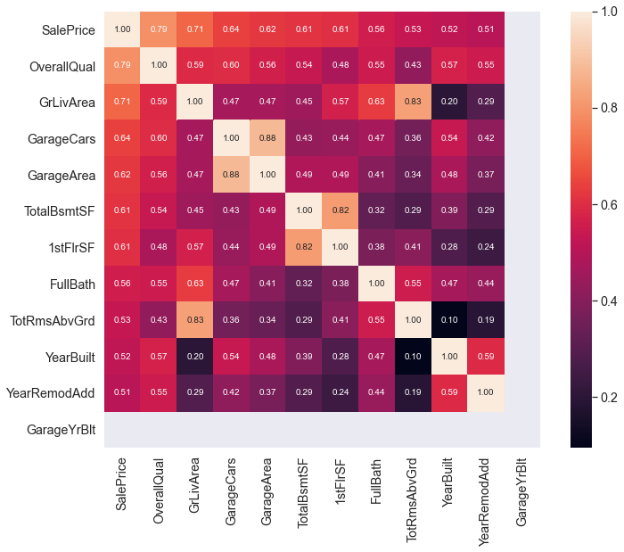
上面的热图,显示了哪些变量是高度相关的,哪些变量是极其相似的(在建模之前我们可以删除这些变量);在这个例子中,我们展示了前 12 个最相关的变量。
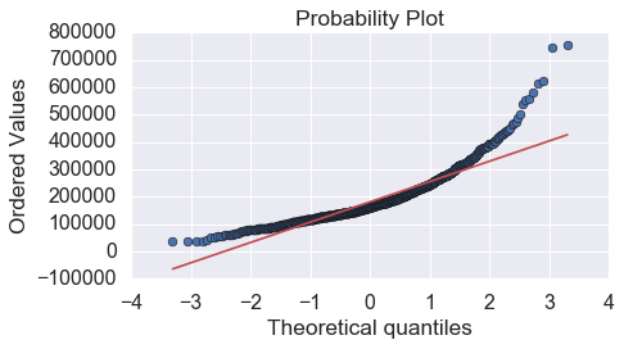
我们可以用分布图和概率图查找异常值。分布图能够描绘出数据分布的方差。根据 Chambers,1983 年的说法,概率图可用于判断数据是否按照了特定规律分布。
plt.figure(figsize=(6,3))
sns.distplot(df_train['SalePrice'])fig = plt.figure(figsize=(6,3))
res = stats.probplot(df_train['SalePrice'], plot=plt)
plt.show()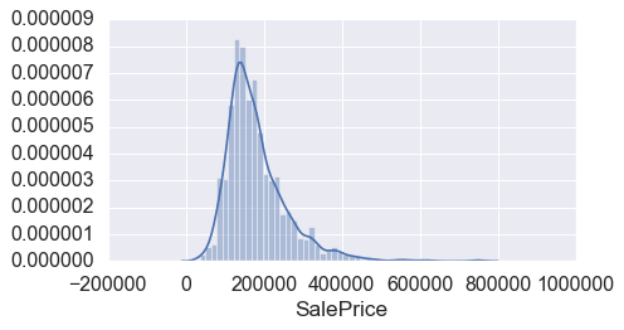
这张图和普通正态分布存在一些差异,这表明我们的目标变量是正偏态(positively skewed)的。它还具有峰值并且呈尖峰态,峰态得分高,表明数据中存在显着异常值。
print("Skewness: %f" %df_train['SalePrice'].skew())
print("Kurtosis: %f" %df_train['SalePrice'].kurt())
从这些值也可以看出,数据具有正偏度和高峰度分数。
偏度是衡量数据对称性的指标——如果分布或数据集左右看起来相同,则该分布或数据集是对称的;而峰度( Kurtosis)是与正态分布相比,衡量数据是严重拖尾,还是轻微拖尾。
当数据中存在大量偏度时,我们可能需要在训练机器学习模型后进行某些修改,让机器学习模型获得更好的结果。
#Using the numpy fuction log1p which applies log(1+x) to all to normalize the saleprice
import numpy as np
df_train["SalePrice"] = np.log1p(df_train["SalePrice"])#new distribution of the data
plt.figure(figsize=(6,4))
sns.distplot(df_train['SalePrice'] , fit=norm);#fitted parameters used by the function
(mu, sigma) = norm.fit(df_train['SalePrice'])
print( '\n mu = {:.2f} and sigma = {:.2f}\n'.format(mu, sigma))#plot the distribution
plt.legend(['Normal dist. ($\mu=$ {:.2f} and $\sigma=$ {:.2f} )'.format(mu, sigma)],loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')#QQ-plot
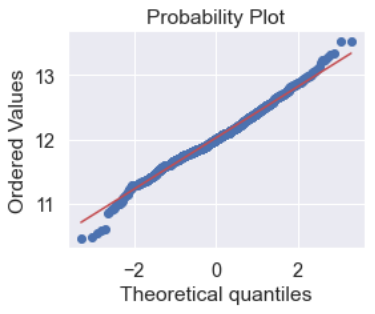
fig = plt.figure(figsize=(4,3))
res = stats.probplot(df_train['SalePrice'], plot=plt)
plt.show()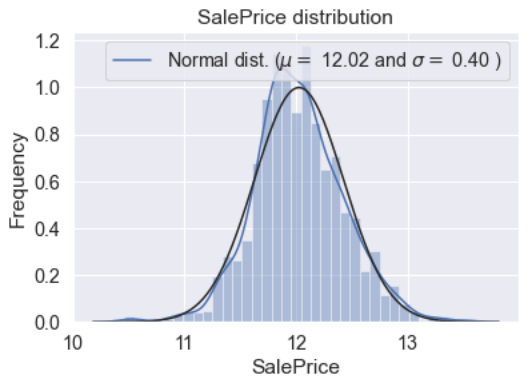
我们可以用散点图查看房屋的“销售价格”和其他数值变量之间的关系,例如地上(地面)居住面积平方英尺 (GrLivArea)、地下室总平方英尺(TotalBsmtSF)、房屋相连街道距离的英尺(LotFrontage)和一楼平方英尺(1stFlrSF)。
#Scatter plot for GrLivArea/saleprice
#地面居住面积/房屋价格的散点图
variable ='GrLivArea'
df_train.iplot(kind='scatter', x='GrLivArea', y='SalePrice', xTitle='SalePrice', yTitle='GrLivArea',mode='markers',size=6, color='blue')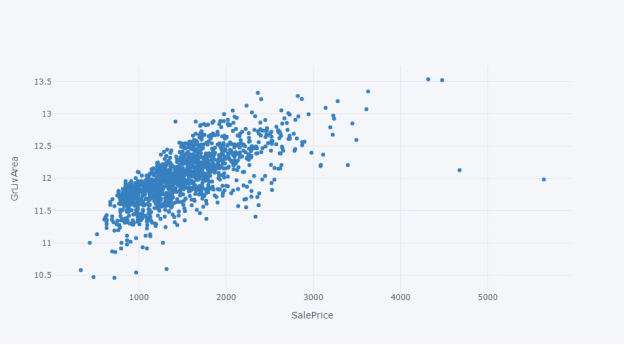
#scatter plot for TotalBsmtSF/saleprice
#地下室面积/房屋价格的散点图
variable ='TotalBsmtSF'
df_train.iplot(kind='scatter', xTitle='SalePrice', yTitle='TotalBsmtSF', x='TotalBsmtSF', y='SalePrice',mode='markers',size=6, color='cyan')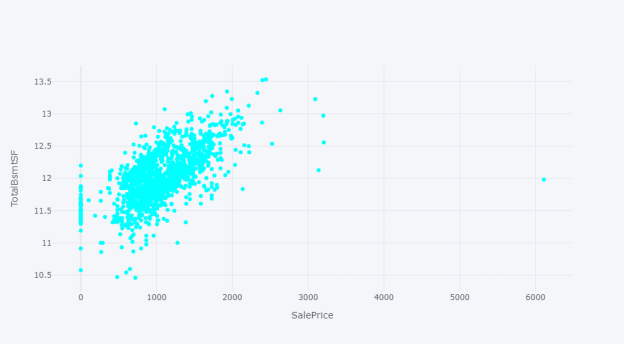
#scatter plot for LotFrontage/saleprice
#房屋到街道距离/房屋价格的散点图
variable ='LotFrontage'
df_train.iplot(kind='scatter', x='LotFrontage', y='SalePrice', xTitle='SalePrice', yTitle='LotFrontage',mode='markers',size=6, color='brown')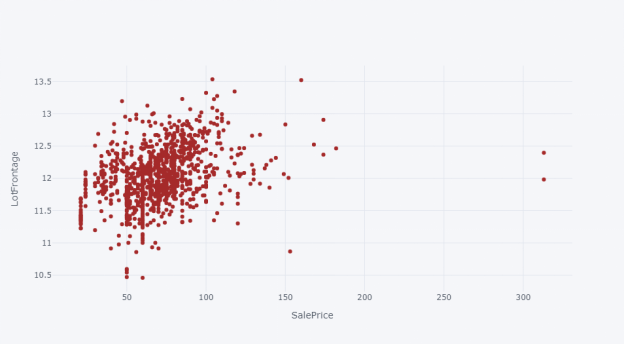
#Scatter plot for 1stFlrSF/saleprice
#房屋一楼面积/房屋价格的散点图
variable ='1stFlrSF'
df_train.iplot(kind='scatter', x='1stFlrSF', y='SalePrice',xTitle='SalePrice', yTitle='1stFlrSF',mode='markers',size=6, color='green')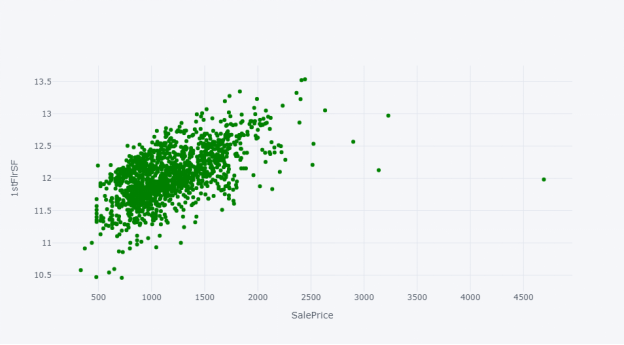
我们可以看到数据中有多个异常值,可以进一步选择是否删除它们;另外,我们也可以在应用机器学习技术或建模之前,使用 RobustScaler 对异常值进行缩放。
总结
因为很多时候,我们需要依靠事实和统计数据来支持我们的论点,因此,理解数据帮助了我们以全新的方式进行思考和决策。
由于“数据消费者(data consumers)”接受信息的方式,使用图表或图形来显示大量复杂数据,往往比电子表格或报告更简单,这也是数据可视化的魅力之一。你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Adrian Kasito
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://medium.com/@adriankc910/understanding-data-interesting-data-visualizations-in-python-c2c3073c8d23





