")
你可能不熟悉的5种数据结构(但非常有用!)
本文介绍5种你可能不熟悉的数据结构,相信我,它们非常有用!如果你想了解更多关于编程的相关内容,可以阅读以下这些文章:
Meta正在做上帝的工作:向世界发布令人震惊的优秀编程模型!
畅销编程书籍中的10个编码秘密
Mojo:比Python快35000倍的AI编程语言
作为一个数据科学家/分析师,不要重复这5个编程错误
1. 布隆过滤器
它是一种概率数据结构,用于确定元素是否存在于集合中。
换句话说,它可以判断一个元素是否可能(而不是绝对)存在于集合中。
它具有高效的空间利用率,因为它不存储实际的元素(如哈希映射)。
此外,布隆过滤器可以给出假阳性结果,但没有假阴性。
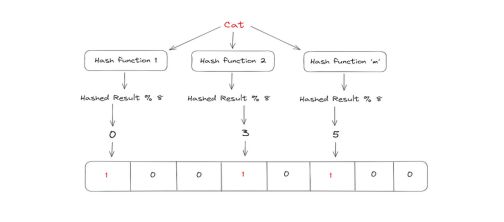
布隆滤波器由n个的比特矢量(下图中的8个)组成。

接下来,我们使用m个快速哈希函数对要添加到布隆过滤器中的元素(例如下面的‘cat’)进行哈希处理。
在这一步之后得到这些哈希结果的模数。对于特定的元素,这些模数是布隆过滤器的位将被切换为1的索引位置。
为了检查布隆过滤器中是否存在另一个名为“Dog”的元素,重复哈希和求模步骤。
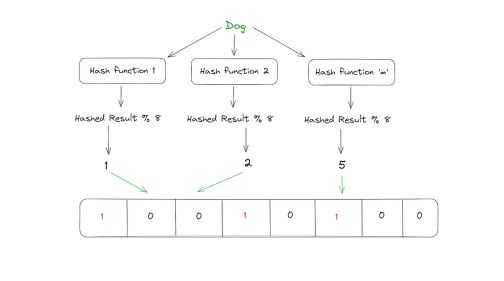
由于打开的位与上述步骤后获得的位不匹配,因此’ dog ‘不在原始数据集中。
应用领域
- Medium的推荐引擎使用布隆过滤器过滤掉用户已经看到的文章。
- Quora使用布隆过滤器过滤掉用户已经看到的故事。
- 比特币系统使用布隆过滤器来加速SPV(简化支付验证)钱包的同步。
2. Rope
Rope是一种用于高效执行字符串操作的数据结构。
与传统的字符串数组相比,Rope可以更快地插入和删除文本(时间复杂度为O(log n)),而传统字符串数组的操作时间复杂度为O(n)。
Rope是一棵二叉树,每个叶节点包含一个字符串和一个长度(称为权重)。
树中的每个节点都包含其左子树中所有叶节点的长度总和。
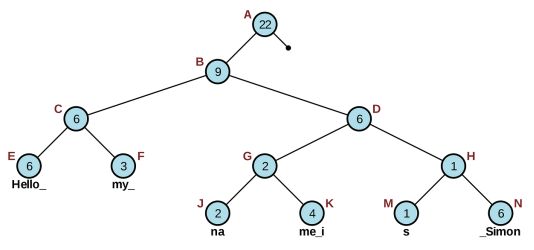
应用领域
以下使用Rope进行有效的文本处理:
- 文本编辑器和文字处理器
- 代码编辑器和集成开发环境(IDE)
- 文本搜索引擎
3.四叉树
它是一种树状数据结构,用于通过递归地将二维空间细分为四个象限来划分二维空间。
要创建一个四叉树,我们从一个2D区域开始。如果该区域内的数据满足某些条件,则该区域成为叶节点。
如果不符合条件,则将该区域划分为四个相等的部分(象限)。这将创建四个子节点。
此过程递归地应用于每个子节点,直到满足条件为止。
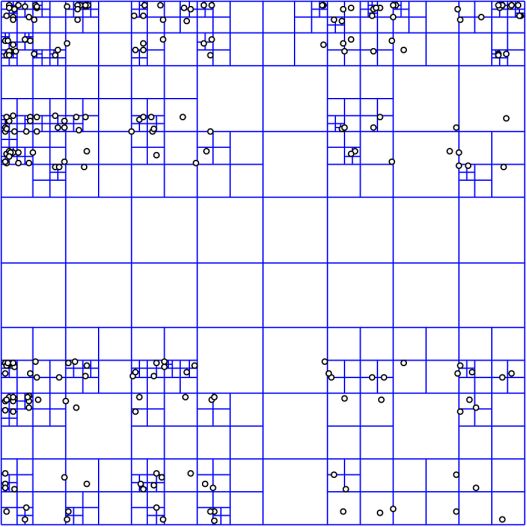
应用领域
- 图像压缩
要执行此操作,我们首先将整个图像作为树的根。
接下来,我们检查该区域的颜色差异是否低于阈值。如果是,则该区域用单一颜色表示。如果不是,则将该区域划分为四个象限。
这个过程对每个象限递归地重复。
最后的树状结构表示颜色一致的区域,然后被编码成压缩格式。

- 用于地理信息系统(GIS)空间数据的存储和查询
4. 伸展树
它是一种二叉搜索树,具有最近访问过的元素可以快速再次访问的附加属性。
伸展树执行插入、查找和删除等基本操作的时间复杂度为O(log n)。
伸展树背后的关键思想是展开操作。
每当执行操作(如搜索、插入或删除)时,树将被重新排列,并将访问或修改的节点放置在树的根部。
这是通过三种潜在旋转的组合来实现的:
- zig
- zig-zig
- zig-zag
应用领域
- 伸展树在缓存实现中被用于最近访问的项目很可能再次被访问的情况
- 它们也用于某些用于内存管理的垃圾收集器
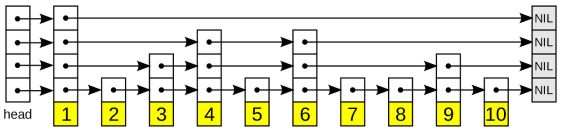
5. 跳跃表
它是一种概率数据结构,允许对有序的元素序列进行快速插入、删除和搜索操作。
当使用跳跃表时,所有这些操作的平均时间复杂度为O(log n)。
跳跃表由多个级别的链表组成。
基本级别包含所有元素(就像常规排序链表一样)。然而,每个后续级别都包含前一个级别的元素的一个子集。
在下一个级别中包含一个元素的决定是根据概率进行的(通过使用随机函数/抛硬币)。
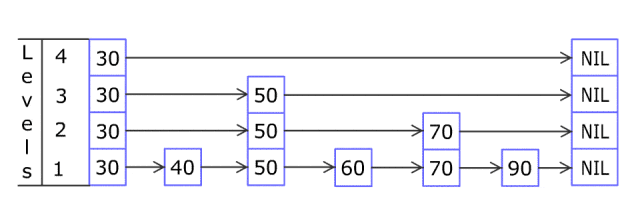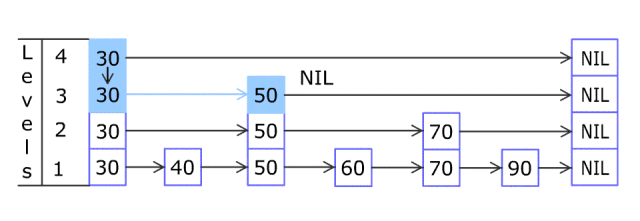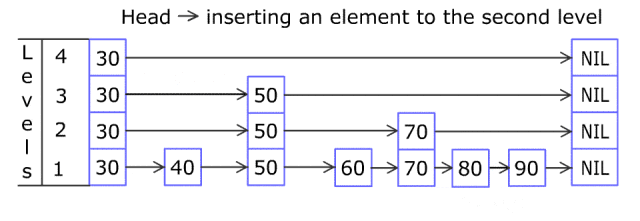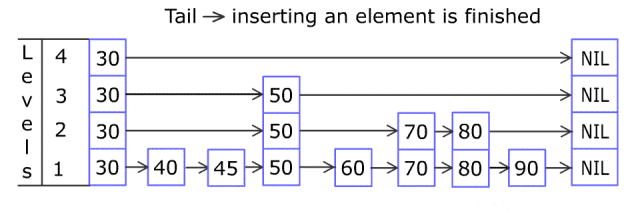
搜索
要搜索一个元素,我们从最左上角的节点Header开始。
遍历该列表,直到遇到大于目标值的值或到达当前级别的末尾。当这种情况发生时,我们向下移动一级。
这个向右和向下移动的过程一直持续,直到我们找到目标值或者到达基本级别并超过了目标所在的位置。
插入
当插入一个新元素时,我们首先使用上面描述的搜索机制找到它的位置。
接下来,我们随机决定这个新元素的级别数,并通过更新相应的指针将该元素插入到所有列表中,直到其指定的级别。
删除
要删除一个元素,我们首先使用上面描述的搜索机制定位它的位置,然后通过更新指针将元素从它出现的所有级别中删除。
应用领域
- 在Redis中,排序集使用哈希表和跳跃表数据结构的组合来实现。
- LevelDB是谷歌开发的一个快速键值存储库,它在内存数据结构中使用跳跃表。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Dr. Ashish Bamania
翻译作者:文杰
美工编辑:过儿
校对审稿:Chuang
原文链接:https://levelup.gitconnected.com/5-data-structures-that-you-probably-are-unfamiliar-with-but-are-extremely-useful-6d3b47f51b0c




