
随机森林回归的一个局限
随机森林是一种流行的机器学习模型,通常用于分类任务,在许多学术论文,Kaggle竞赛和博客文章中都可以看到。除分类外,随机森林还可用于回归任务。随机森林的非线性特性可以使其比线性算法更具优势,使其成为一个不错的选择。但是,重要的是要了解您的数据并记住随机森林无法推断。它只能做出是以前观察到的标签平均值的预测。从这个意义上讲,它与KNN非常相似。换句话说,在回归问题中,随机森林可以做出的预测范围受训练数据中最高和最低标签的约束。在训练和预测输入的范围和/或分布不同的情况下,此行为会成为问题。这称为协变量平移,大多数模型难以处理,但对于随机森林尤其如此,因为它无法推断。
例如,假设您正在使用随时间推移具有潜在趋势的数据,例如股票价格,房屋价格或销售。如果您缺少训练数据的任何时间段,那么根据趋势,随机森林模型将低于或过度预测训练数据中时间范围以外的示例。如果将模型的预测相对于它们的真实值进行绘制,这将非常明显。让我们通过创建一些数据来了解一下。
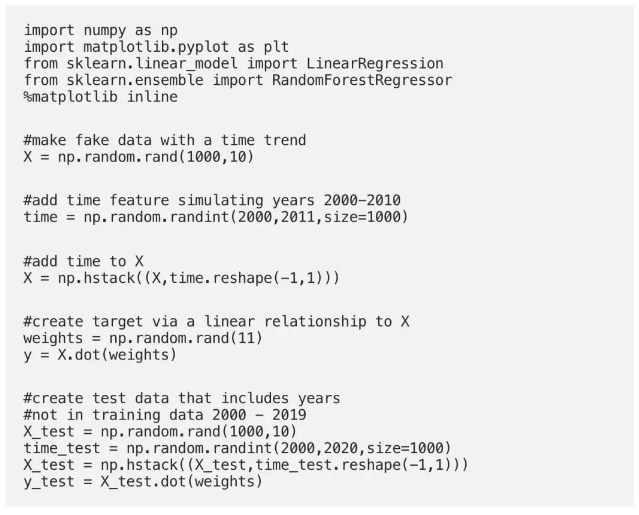
让我们来看看随机森林对测试数据的预测有多好。

这个结果不是很好。我们用它们的已知值和预测进行对比,看看发生了什么。
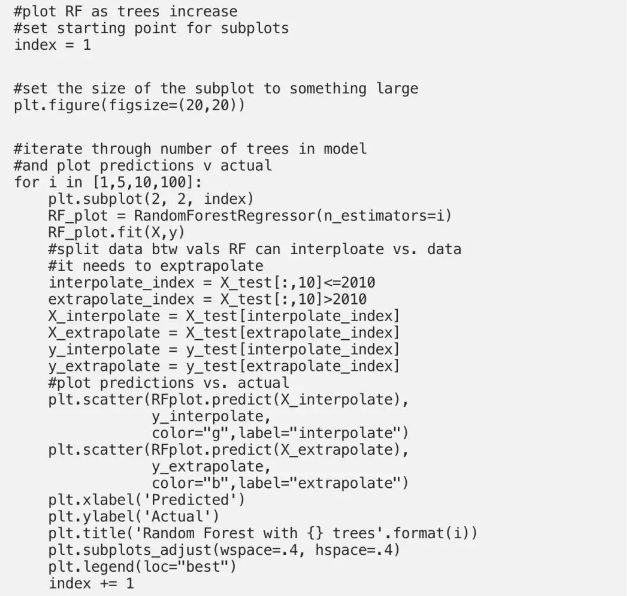
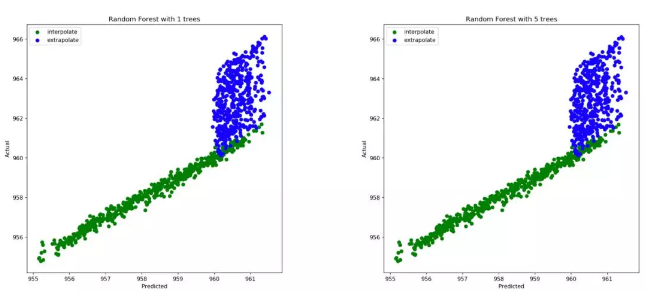
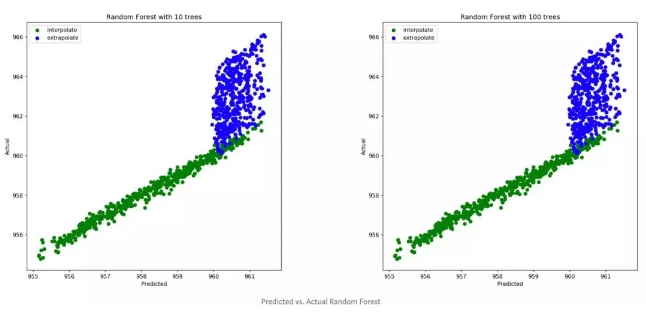
该图清楚地表明,该模型可以预测的最高值约为961,而数据中的潜在趋势将最新值推至966。不幸的是,Random Forest无法推断线性趋势并准确预测时间值高于训练数据值(2000-2010年)的新示例。即使调整树木数量也无法解决问题。在这种情况下,由于我们对数据施加了完美的线性关系,因此像“线性回归”这样的模型将是一个更好的选择,并且在检测数据趋势以及对训练时间范围之外的数据进行准确预测时都不会出现问题。

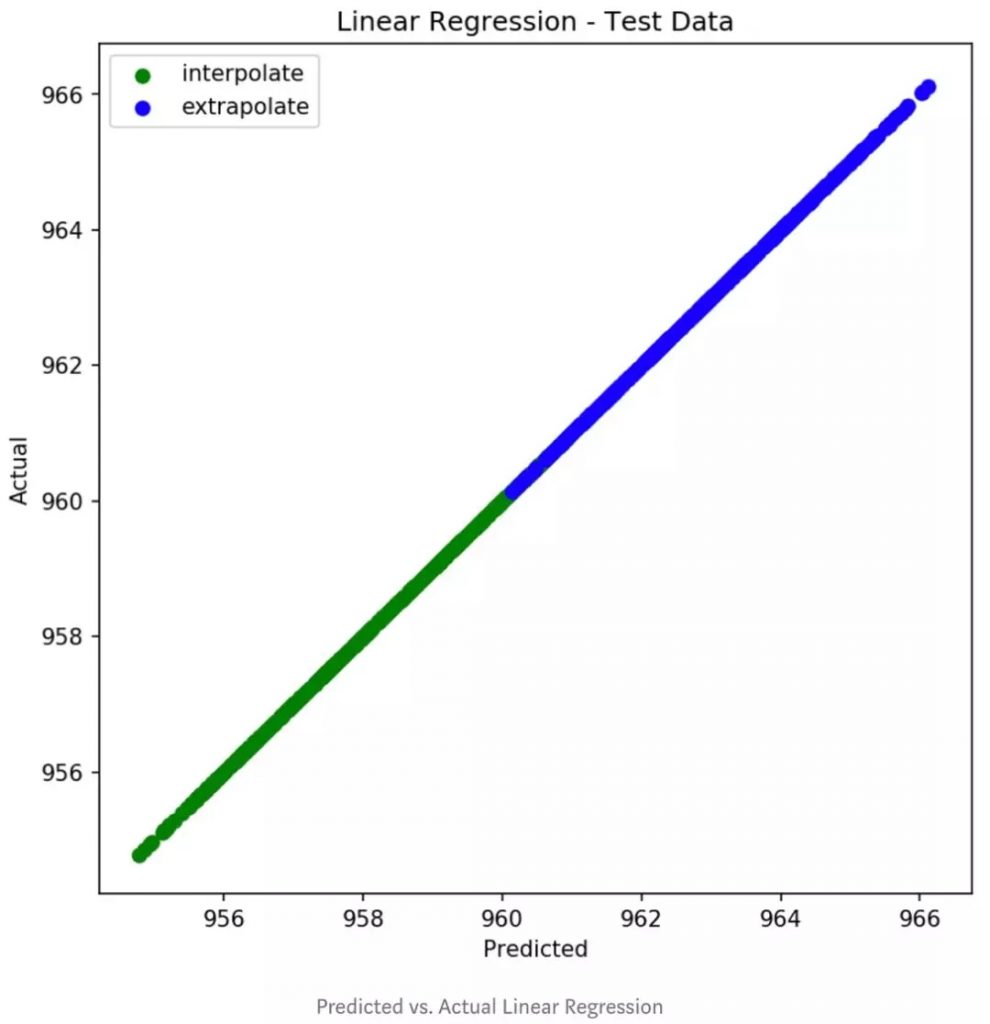
尽管“随机森林”通常是模型的理想选择,但了解其工作方式以及是否对您的数据可能有任何限制仍然很重要。在这种情况下,因为它是基于邻域的模型,所以它使我们无法对训练数据之外的时间范围做出准确的预测。如果您发现自己处于这种情况,则最好测试其他模型,例如线性回归或立体派,和/或考虑在模型集成中使用随机森林。预测愉快!
作者:Ben Thompson
翻译:Xin Zhang





