我是如何从4万个训练图像中探索亚马逊雨林的?——Kaggle竞赛第一名专访
在最近的《我们的地球:从宇宙中探索亚马逊雨林》Kaggle竞赛中,地球母亲带给我们Kaggle社区来自亚马逊盆地的卫星图像标记的挑战,让我们更好地跟踪以及了解森林砍伐的原因。
本次比赛包含超过40,000个训练图像,每个训练图像又可涵盖多个标签,通常分为以下几组:
· 大气条件:晴朗,部分多云,多云和阴霾
· 常见的土地覆盖以及土地利用类型:雨林,农田,河流,城镇/城市,道路,耕种和裸地
· 罕见土地覆盖物以及土地利用类型:砍伐和焚烧,选择性伐木,开花,常规采矿,手工采矿和排土

最近,我们与比赛的获胜者“bestfitting”进行了深入的交谈,详细了解了他是如何使用11个精心调教的卷积神经网络,标签相关结构模型以及如何避免过度拟合来获得第一名的。

参加这项挑战之前,你的背景是什么呢?
我主修计算机科学,在Java编程方面拥有10多年的经验,并从事大规模数据处理,机器学习和深度学习。
你是否拥有任何之前参加比赛的经验或专业领域知识,帮助你在比赛中取得如此优异的成绩?
我今年参加过Kaggle的一些深度学习竞赛。 获取到经验以及直觉都对这次的胜利有很大的帮助。
请问你是如何开始在Kaggle上竞争的?
从2010年以来,我一直有阅读许多关于机器学习和深度学习的书籍和论文,但我总是发现很难将我学到的算法应用在各种小型数据集上。 因此,当我了解到Kaggle的时候,我认为这是一个绝佳的平台,其中包含了很多有趣的数据集,内核和精彩的讨论。 于是我便迫不及待地想要在Kaggle上尝试做一些项目,并在去年参加了“预测红帽业务价值”的竞赛。
是什么让你决定参加这场比赛?
参加这项比赛有两个原因。
首先,我对大自然的保护有着浓厚的兴趣。 我认为使用我的技能来改善我们的星球和生活变得很酷。 因此,我参加了Kaggle今年举办的所有此类比赛。 而且我对亚马逊雨林特别地感兴趣,因为它经常出现在以前看过的电影以及故事中。
其次,我已经使用诸如分割和检测之类的算法参加了Kaggle上的各种深度学习竞赛,因此我希望通过分类挑战来尝试不同的方法。

可否简单介绍一下你的解决方案?
这是一个多标签分类挑战,并且标签不平衡。
这是一个艰苦的竞争,因为近年来图像分类算法已被广泛使用和建立,并且有许多经验丰富的计算机视觉竞争者。
我尝试了许多我认为可能有用的流行分类算法,并且在对标签关系和模型功能进行仔细分析的基础上,我得以构建出一种集成算法,该方法获得了第一名。
这是我模型的架构:
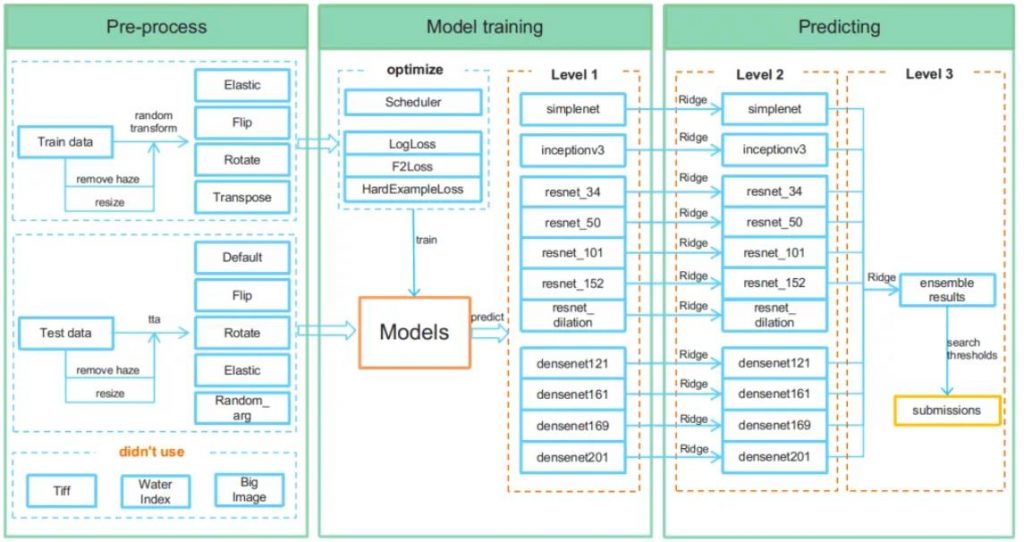
简单来讲:
首先,我对数据集进行了预处理 (通过调整图像大小并消除雾度),并应用了几种标准的深度学习中数据增强的技术。
接下来,关于我的模型,我微调了11个卷积神经网络 (我使用了各种流行的,高性能的CNN,例如ResNets,DenseNets,Inception和SimpleNet)来为每个CNN获得一组类标签概率。
然后,我通过其各自的岭回归模型传递了每个CNN的类别标签概率,以便调整概率以利用标签相关性 。
最后,通过使用另一个岭回归模型,我将所有11个CNN 集成在一起。
还要注意的是,我没有使用标准的对数损失作为损失函数,而是使用了特殊的F2损失 ,以便在F2评估指标上获得更好的分数。
你都做了哪些预处理和特征工程处理呢?
我使用了几个预处理和数据增强的步骤。
首先,我调整了图像大小。
我通过在训练和测试集中翻转,旋转,转置和弹性变换图像来实现添加数据增强。
我还使用了一种除雾技术 ,该技术在“使用暗通道优先级的单图像除雾”中进行了介绍,以帮助我的网络更清晰地“看到”图像。
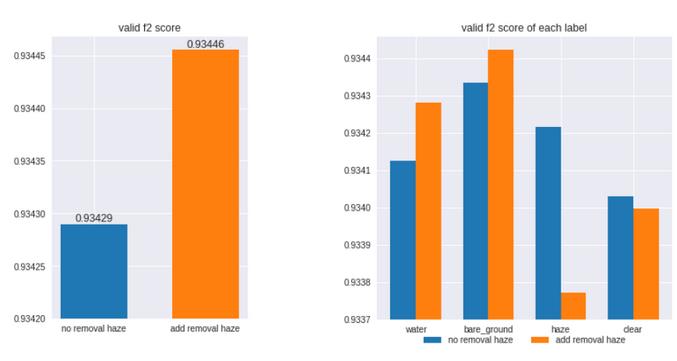
以下是数据集上除雾的一些示例:

如下图所示, 除雾改善了某些标签的F2得分(例water和裸地 ),但降低了其他标签的F2得分(例如haze和clear )。 但是这其实就很好,因为集成算法可以为每个标签挑选出最强的模型,并且除雾技巧对整体效果有所帮助。
你使用了哪些监督学习方法?
我的集成模型的基础是由11个流行的卷积网络组成:具有不同参数和层数的ResNet和DenseNet的混合,以及Inception和SimpleNet模型。 在替换最终输出层以满足比赛的输出之后,我对这些经过预训练的CNN的所有层进行了微调,并且我没有冻结任何一层。
训练集包含40,000多个图像,因此足够大,甚至可以从头开始训练其中的某些CNN架构(例如resnet_34和resnet_50),但是我发现微调预训练网络的权重会提升模型的性能。
你是否使用任何特殊技术为评估指标建模?
提交的内容根据F2评分来评估的,这是一种将精确度和召回率结合为一体的单一评分方法-类似于F1评分,但召回权重比精确度高。 因此,我们不仅需要训练模型来确保预测标签概率,还必须选择最佳阈值来确定是否在给定标签概率的情况下选择标签。
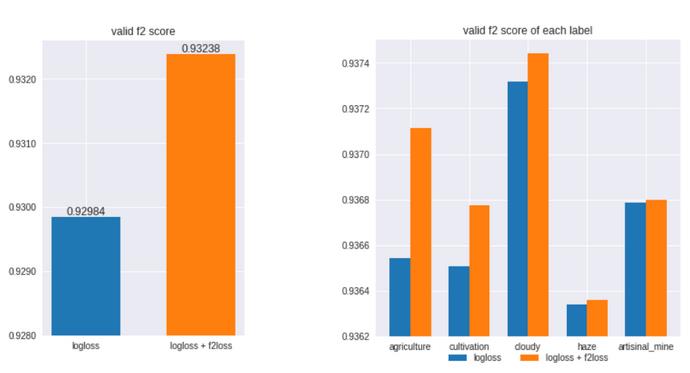
首先,像其他许多竞争对手一样,我使用对数丢失作为损失函数。 但是,如下图所示,较低的对数损失并不一定会导致较高的F2分数。
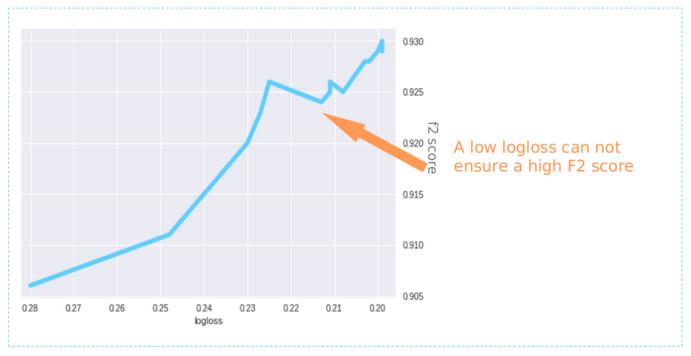
这意味着我们应该找到另一种损失函数,该函数可使我们的模型更加关注优化每个标签的召回率。 因此,在论坛代码的帮助下,我编写了自己的Soft F2-Loss函数。
确实提高了整体F2分数,尤其是提高了农业 , 多云和耕作等标签的F2分数。
你对这组数据和模型最重要的见解是什么?
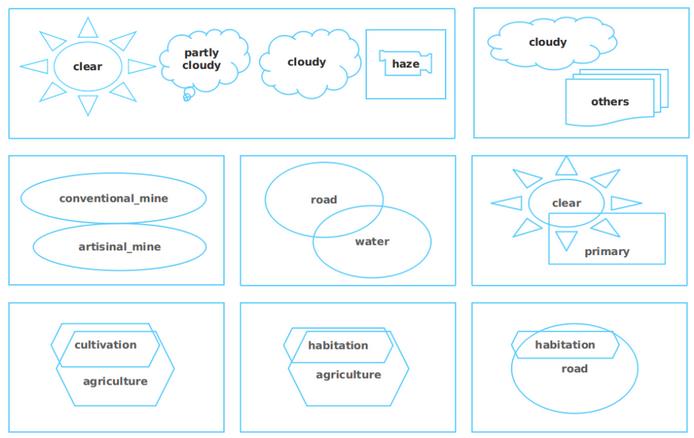
我分析了标签之间的相关性,发现某些标签并存的频率很高,而其他标签则不存在。 例如, 清晰的 , 部分多云的 , 多云的和阴霾的标签是不相交的,但是栖息地和农业标签却经常出现。 这意味着利用此相关结构可能会改善我的模型。
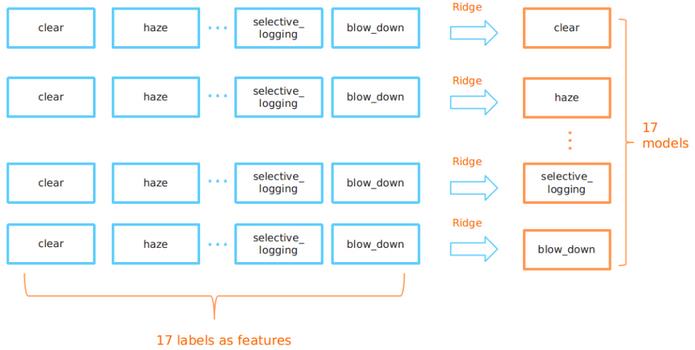
例如,让我们以resnet-101模型为例。 这可以预测17个标签中每个标签的概率。 但是,为了利用标签的相关性,我添加了另一个岭调整层,以在给定所有其他标签概率的情况下重新校准每个标签概率。
换句话说,为了预测最终的清除概率(仅从resnet-101模型开始),我有一个特定的清除岭回归模型,该模型吸收了resnet-101模型对所有17个标签的预测。
你如何整合模型?
从所有N个模型获得预测后,我们从N个不同模型中获得了N个清晰标签的概率。 通过使用另一种岭回归,我们可以使用它们来预测最终的清晰标签概率。
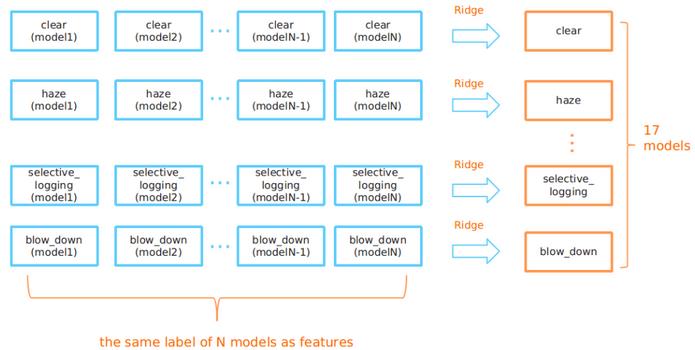
这种两级岭回归可以做两件事:
1. 首先,这样做允许我们使用不同标签之间的相关联信息。
2. 它使我们能够选择最强大的模型来预测每个标签。
是否对你的一系列发现感到惊讶?
即使我曾预测过排行榜的最终改组(公共排行榜和私人排行榜的得分相差很大),但我仍然感到惊讶。
本质上,在比赛的最后阶段(结束前10天),我发现公开得分非常接近,我再也无法提高本地交叉验证或公开得分了。 因此,我警告自己要小心,以免过度拟合可能只是标签噪音的问题。
为了更好地理解这一陷阱,我使用不同的随机种子将训练集图像的一半选作新的训练集,从而模拟了划分为公共排行榜和私人排行榜的过程。 我发现随着种子的变化,我的模拟公共分数和私人分数之间的差异可能会增加到0.0025。 但是公共排行榜上前1名和前10名之间的差距小于此值。
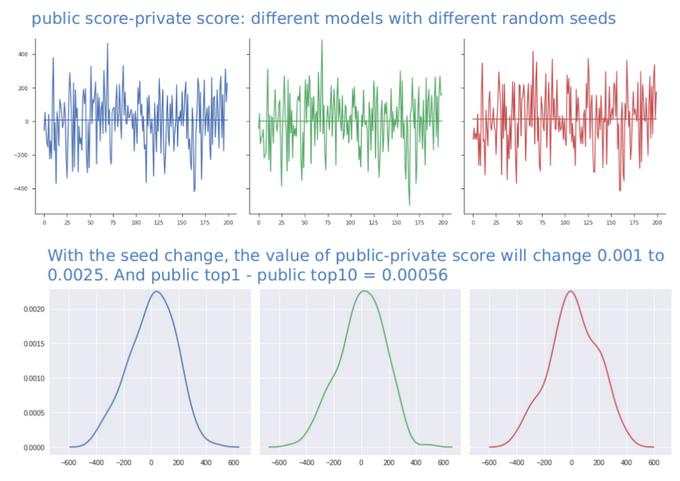
这意味着在真正的比赛中也很有可能发生重大变化。
经过仔细的分析,我发现这种变化是由于图像难以识别而引起的,其中标签也容易被人类混淆,例如图像应被标记为雾霾,阴天,道路还是水,还是应开花还是选择性伐木。
因此,我说服自己,公共排行榜分数并不是衡量模型能力的完美指标。 这是出乎意料的:由于公开测试集包含40,000张以上的图片,因此排行榜似乎应该非常稳定。
因此,我调整了目标,仅使自己保持在前十名,并决定不在乎上周我在公共排行榜上的确切位置。 相反,我试图找到最稳定的模型集成方法,抛弃了可能导致过度拟合的所有模型,最后我使用了投票和岭回归。
为什么会使用那么多模型?
答案很简单:多样性。
我认为模型的数量并不是一个大问题,这有几个原因:
首先,如果我们想要一个简单的模型,我们只需选择其中的1-2个,就可以在公共排行榜和私人排行榜上都获得不错的成绩(前20名)。
其次,我们有17个标签,不同的型号在每个标签上具有不同的功能。
第三,我们的解决方案将用于替代或简化人类标签工作。 由于计算资源比人类便宜,因此我们可以使用强大的模型来预测未标记的图像,修改任何错误地预测的图像,然后使用扩展的数据集来迭代地训练更强大或更简单的模型。
你使用了哪些工具?
Python 3.6,PyTorch,PyCharm社区版本。
你的硬件设置是什么样的?
带有四个NVIDIA GTX TITAN X Maxwell GPU的服务器。

你从这场比赛中收获了什么?
如上所述,我发现使用软F2损失函数,添加雾度消除算法以及应用两级岭回归对于获得良好的分数很重要。
同样,由于标签噪音,我们必须信任我们的本地交叉验证。
你对刚接触数据科学的人有什么建议吗?
学习斯坦福大学的CS229和CS231n等优秀课程。
从Kaggle竞赛,内核和入门脚本中学习。
参加Kaggle竞赛并从中学习来获取反馈。
每天阅读论文并实施其中的一些论文。
原文作者:Edwin Chen
翻译作者:Tony Sun
美工编辑:过儿
校对审稿:Dongdong





