
苹果终于揭示了Siri的未来
苹果再次发布了两篇人工智能研究论文,其中包含了对他们关于生成式人工智能战略的重要见解。
毫无疑问,在苹果产品中,迫切需要升级的其中之一就是Siri,它糟糕透顶的语音助手。
令人惊讶的是,ChatGPT发布一年多之后,Siri仍然像往常一样迟钝和有限,几乎感觉像是史前时代的产物。
但是,有了苹果的ReALM和Ferret-UI模型,我们现在对Siri的未来有了更清晰的认识,而且非常有希望。
如果你想了解更多关于苹果公司的相关内容,可以阅读以下这些文章:
为什么2024年将最终成为苹果的人工智能年
苹果终于发布了MM1 — 一款可以在 iPhone 上运行的多模态AI模型
苹果封杀FB?保护用户隐私问题上,两巨头差了几条街?
44个苹果公司面试最难问题
一个期待已久的问题有待解决
在人工智能竞赛的这个阶段,许多人可能会想:“为什么苹果没有更新它的语音助手Siri?”
当然,他们有许多原因,因为像谷歌这样的公司已经用大型语言模型(LLM)Gemini替换了他们的助手。
但与谷歌不同,苹果在不确定自己的产品是否优秀的情况下很少会进行大规模发布。
问题在于,实际上,今天大多数LLM,即使是我们最好的LLM,都是糟糕的语音助手,原因有两个:数据和大小。
缺失的数据
在人工智能领域,数据 >>> 架构。
无论你的体系结构设计有多好,如果没有合适的数据来完成任务,模型都会失败。作为语音助手的关键组成部分,参考分辨率数据可能是最差的。
但是什么是参考解析?
引用解析涉及到在考虑各种类型的上下文的情况下,确定语言中模糊引用所指向的特定实体或项目的过程。
例如,在下面的图片中,用户要求语音助手显示附近的药店。一旦代理助手显示列表,用户可能会间接地引用列表中的元素(如下面显示的三个示例),这需要代理能够从非常模糊的框架中识别引用。
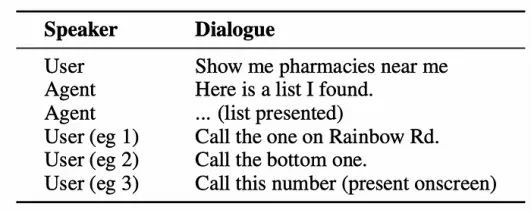
如果你仔细想想,你与Siri或任何其他语音助手的大多数互动都是这样构建的,你希望助手能够检测到这些关系。
但你也可以让Siri的情况变得更加困难,例如“你能把音量调低吗?”这可能是指你的iPhone扬声器…或者房间的扬声器,也碰巧连接到了代理。
而且Siri还必须处理另一个问题:屏幕上的引用,这意味着它不仅必须处理文本引用,还必须处理视觉引用。
总的来说,尽管我们目前最好的模型应该能够完成所有这些,但它们缺乏针对此任务进行优化的数据,表现非常糟糕。
但情况变得更糟。
小硬件需要小模型
如果你要在LLM上运行Siri,你需要它非常非常小。
由于Transformer的权重文件(存储其信息的地方)必须在RAM中,即使是最高级的智能手机也无法运行中等大小的模型,因为目前智能手机提供的最大RAM约为24GB。
这意味着你最多只能运行一个大小为10GB的LLM,这是非常乐观的。
如果你想在电脑上本地尝试一个LLM(我显然是在指称像LLaMa这样的开放权重模型),最简单的方法是进入HuggingFace并搜索你想要的模型的“文件和版本”选项卡,查找一个“.bin”或“.safetensor”文件。这就是权重文件。
因此,你需要运行模型所需的RAM大约将等于该文件的重量加上大约20%的额外RAM,以应对KV缓存,尽管对于极长的序列,后者可能会急剧上升,这在今天的智能手机等消费者端硬件中显然不是一个选择。
那么,苹果是如何克服这些问题的呢?
有目的地创建数据和专门的模型
考虑到对于这一高度特定任务而言数据和临时模型的迫切需求,苹果正是这样做的。
他们训练了两个模型:
- ReALM:基于大型语言模型的专家级参考解析模型
- Ferret-UI:一种多模式LLM,专门用于屏幕数据的基础和引用任务
ReALM,征服参考分辨率
苹果通过以下方式训练了ReALM:
- 创建多样化数据集,其中包含对话、合成场景和实际屏幕内容。
- 通过教导大型语言模型(FLAN-T5)理解这些示例。他们将所有不同的实体和情景转换成了模型可以学习的文本格式。
- 创新了一种只用文本描述屏幕上内容的方式,使模型可以“可视化”屏幕布局和实体,就像它真的看到了它们一样,帮助它确定“顶部”或“左侧”等引用的含义。
其结果如何呢?
有趣的是,ReALM的性能与GPT-4相比具有令人印象深刻的竞争力,尽管它是一个更轻的模型,在针对合成、屏幕、对话和零样本数据的多个数据集测量参考分辨率时,参数少了几个数量级。
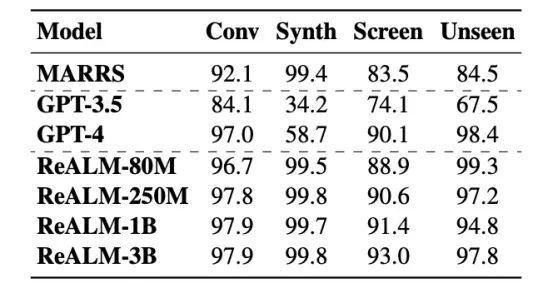
作为参考,假设GPT-4的大小约为传言中的1.7万亿个参数,而ReALM的最大模型大小为30亿个参数,尽管大小相差500倍,但ReALM仍然与GPT-4竞争。
然而,尽管 ReALM 取得了令人鼓舞的结果,但Siri的未来显然是他们最新的多模式LLM——Ferret-UI。
Ferret-UI,或者我们现在应该称它为Siri吗?
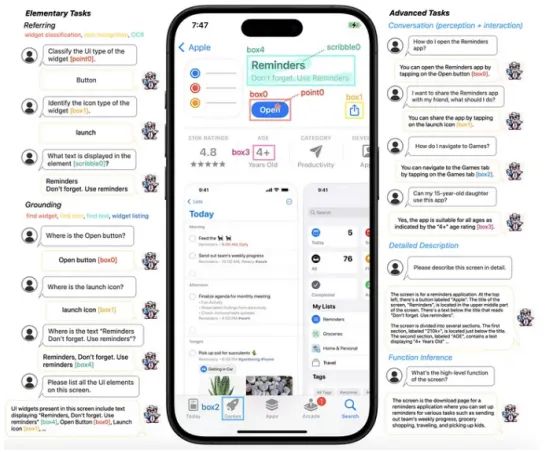
上周,苹果宣布了一个专注于屏幕检测的多模式LLM,名为Ferret-UI。如下所示,该模型可以将iPhone和Android的屏幕理解为任何所需的粒度。
重要的是,与ReALM不同,后者与GPT-4竞争,Ferret-UI完全超越了在屏幕任务中的任何其他MLLM,包括GPT-4V。
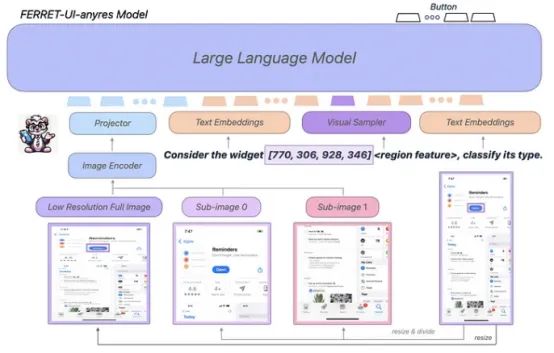
Ferret-UI与我在一月份介绍过的Ferret模型非常相似,只是添加了一些细微差别:
- 图像编码器捕获要处理的屏幕数据
- 文本嵌入器将用户的请求转换为词嵌入,这是LLM处理它们所需的转换。
- 将Ferret与其他MLLM区分开的一个关键组成部分是视觉采样器。如果用户在特定对象周围绘制引用,或者询问特定位置的对象,这个元素会接受用户提供的框、点或自由形式的草图,并处理内部对象,识别它是什么以及它的作用,例如下面来自原始Ferret论文的例子:

- 一个LLM,它接受所有前面组件的输入并生成响应。
然而,正如前面提到的,Ferret-UI添加了一个额外的功能:它能够处理任何分辨率。
因为有些问题需要回答的对象在屏幕上只占很小一部分,而且大小和分辨率也可能差异很大,所以Ferret-UI除了全局屏幕图像外,还处理了屏幕的一部分子图像(如上所示)。
简单来说,该模型不仅能够理解全局屏幕,还能理解其不同的部分。如果我们回想一下之前的例子,Ferret捕捉到了三件事:
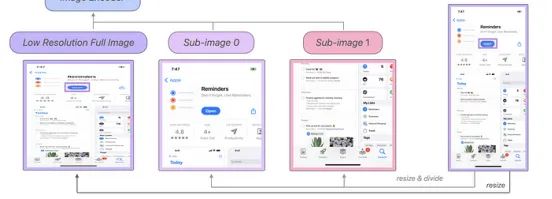
- 全局屏幕指的是提醒应用
- 屏幕的顶部部分允许你打开应用程序,显示它的评论,如何分享它等等
- 屏幕的底部显示应用程序的屏幕截图等内容
这种子图像处理效果很好,以至于苹果的研究人员声称,即使只占全屏幕的0.1%的对象和引用也能被该模型检测到。
因此,即使问题涉及小对象,各种子图像中的一个也应该能够充分捕捉到它们。
总的来说,Ferret-UI是一种最先进的MLLM,可以识别并回答屏幕上任何单个对象的问题,这是Siri必须完成的任务。
但是这两个版本,ReALM和Ferret-UI,纯属巧合吗?当然不是。因此,它们是如何协同作用的,Siri又能在其中发挥什么作用呢?
Siri的未来有目共睹
毫无疑问,Siri的升级将是两者的结合。
最有可能的情况是以Ferret-UI为基础,他们将利用他们收集和验证的参考数据,通过ReALM进行微调,创建一个能够完美理解模糊或微妙引用的模型,同时能够解释屏幕上呈现的每个对象和命令。
话虽如此,我预计在升级之前会有此架构的更新版本,原因有两个:
- 他们使用了GPT-4生成数据,这意味着他们不能商业化使用Ferret-UI,因为那样会违反OpenAI的条款和条件。
- Ferret-UI的大小仍然至少为70亿个参数,所以除非他们考虑将LLMs存储在闪存中,否则他们将需要它变得更小。
在通常的混合精度或每个参数2字节的情况下,一个70亿参数的模型占据14GB的RAM,而这还没有考虑KV缓存。
然而,就在本周,苹果已经确认iOS的改进将“在设备上”进行。换句话说,如果他们真的在考虑使用MLLM来增强iPhone,我可以向你保证他们确实在考虑,他们几个月前发布的一项关于苹果对Flash LLM的研究将一如既往地突出。
与大多数当前需要存储在智能手机RAM中的LLMs不同,Flash LLMs存储在闪存中(闪存大一个数量级,但访问速度慢得多),而专门的预测器会将预测所需的内存部分加载到RAM中。在前述研究中,他们通过这种技巧成功地将模型的大小增加了两倍。
苹果开始获得关注
总的来说,随着每一次新的发布,苹果的GenAI战略都变得日益清晰:
他们正在构建的一切都集中在iPhone的下一次重大更新iOS 18上。
与其他大型科技公司试图创建下一个大的AI飞跃不同,苹果似乎致力于选择由竞争对手留下的唾手可得的果实,并试图朝相反的方向创新:
与其让人工智能变得更大更好,不如让它更小但更高效,这对消费者端用例至关重要,而消费者端用例是苹果商业模式的精髓。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Ignacio de Gregorio
翻译作者:文杰
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/apple-finally-unveils-siris-ai-future-800bc144dd8a





