
Llama3已经发布,它能在你的电脑上运行了

这是一个充满惊喜的一周。全球AI社区发布了许多令人惊叹的新模型:
- StableLM-2–12B
- WizardLM-2–7B
- Meta-Llama-3–8B 和 70B
由于某种原因,我还不清楚(也许是因为StableLM的架构更复杂),尚未发布量化版本…… 但对于WizardLM-2和Llama-3,我们已经获得了装满GGUF模型二进制文件的Hugging Face。
如果你想知道如何在你的笔记本电脑上运行Llama-3–8B,那么请做好准备,因为你来对地方了。
我不会深入讨论这个模型的细节:很多人会做,而且肯定比我做得更好。我会给你一个在线资源,你可以免费测试70B参数模型。如果你想了解更多关于Llama的相关内容,可以阅读以下这些文章:
Llama3来了!
如何使用Code Llama构建自己的LLM编码助手
为什么每个数据科学家都需要了解Llama 2
Meta的新LLaMa AI模型是给世界的礼物!
你需要什么
我们将使用llama.cpp库和 python 在我们的本地计算机上快速运行模型。这将是初始测试的设置,只有文本界面……但可以 100% 工作。
依赖项
我们只需要安装2个库。
仅使用CPU
创建一个新目录(对我来说是TestLlama3),进入其中,并打开终端。
python -m venv venv
venv\Scripts\activate #to activate the virtual environment现在你已经有了一个干净的 Python 环境,我们将安装 llama-cpp-python 和 OpenAI 库。
pip install llama-cpp-python[server]==0.2.62
pip install openai注意:需要 OpenAI 库只是因为我们将使用 llama-cpp 附带的内置兼容 OpenAPI 服务器。这将使你为未来的 Streamlit 或 Gradio 应用程序做好准备。
配备 Nvidia GPU
如果你有 NVidia GPU,则必须在调用 pip 命令之前设置编译器的标志:
$env:CMAKE_ARGS="-DLLAMA_CUBLAS=on"
pip install llama-cpp-python[server]==0.2.62
pip install openai完毕!
从 Hugging Face 下载 Llama-3–8B GGUF
这是你需要的真实模型:模型的量化(压缩)权重,采用 GGUF 格式。
我尝试了其中的一些,但目前唯一具有固定标记器和聊天模板的一个来自此存储库:
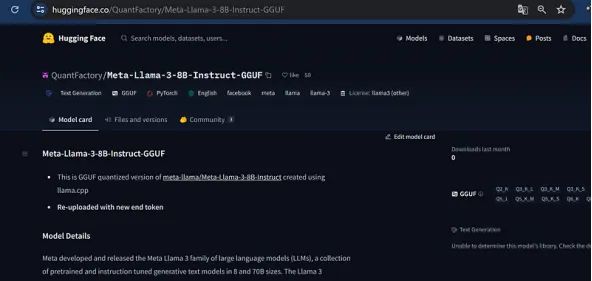
单击“文件和版本”并选择 Q2_K(仅 3 Gb)或 Q4_K_M(4.9 Gb)。第一个准确度较低但速度更快,第二个在速度/准确度之间取得了良好的平衡。
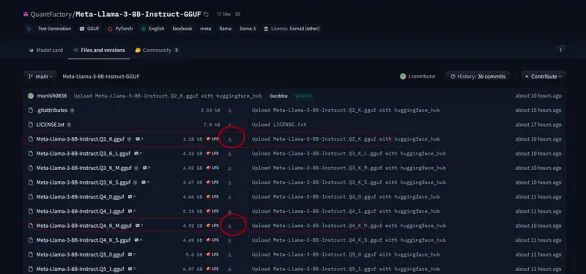
在主项目目录中创建一个名为model的文件夹。下载该文件夹内的 GGUF 文件。
准备就绪
双终端策略
最简单的方法是在一个终端窗口中运行llama-cpp-server(并激活虚拟环境…),在另一个终端窗口中运行与API交互的Python文件(同样激活虚拟环境…)
所以在主目录中打开另一个终端窗口并激活虚拟环境。
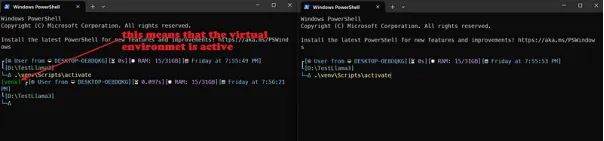
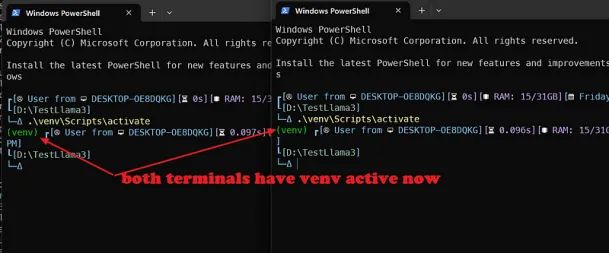
Python文件
我们的Python文件(我称之为LLama3-ChatAPI)是一个文本界面程序。我接受提示输入并向 API 服务器发送/接收指令并获取响应。
它很方便,因为它完全依赖于你正在使用的模型。让我们来看一下:
# Chat with an intelligent assistant in your terminal
from openai import OpenAI
# Point to the local server
client = OpenAI(base_url="http://localhost:8000/v1", api_key="not-needed")
在这里,我们调用了OpenAI库,它具有用于标准API调用的内置类,并实例化了client
然后我们用第一对格式化消息历史记录:Python 字典的第一个条目是系统消息,第二个条目是用户提示,要求模型自我介绍。
history = [
{"role": "system", "content": "You are an intelligent assistant. You always provide well-reasoned answers that are both correct and helpful."},
{"role": "user", "content": "Hello, introduce yourself to someone opening this program for the first time. Be concise."},
]
print("\033[92;1m")奇怪的 print 语句是一个 ANSI 转义码,用于更改终端颜色(如果你想了解更多信息,可以阅读此处)。
现在我们开始一个 while 循环:基本上,我们要求用户提示并从 Meta-Llama-3–7B-instruct 模型生成回复,直到我们说quit或exit。
while True:
completion = client.chat.completions.create(
model="local-model", # this field is currently unused
messages=history,
temperature=0.7,
stream=True,
)
new_message = {"role": "assistant", "content": ""}
for chunk in completion:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
new_message["content"] += chunk.choices[0].delta.content
history.append(new_message)
print("\033[91;1m")
userinput = input("> ")
if userinput.lower() in ["quit", "exit"]:
print("\033[0mBYE BYE!")
break
history.append({"role": "user", "content": userinput})
print("\033[92;1m")第一次调用是为了完成聊天:事实上,我们已经对模型有疑问了,对吧?
你好,请向第一次打开此程序的人介绍一下自己。简洁一点。”
我们使用的是 Stream 方法,因此只要从 API 调用发送响应令牌,Python 就会开始逐个键入响应令牌。
注意:如果你没有 GPU,可能需要几秒钟的时间,具体取决于提示的长度(考虑到之前的所有对话始终是新提示的一部分……否则 Llama3 甚至会忘记你自己的名字!)
最后,我们要求用户输入准备好重新开始:我们将新的提示附加到现有的聊天历史记录 ( history) 中,以便 Llama3 可以开始处理它。
保存Python文件,然后我们就准备好了!
是时候运行了
在第一个终端窗口中,激活 venv 后运行以下命令:
#with CPU only
python -m llama_cpp.server --host 0.0.0.0 --model .\model\Meta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048
#If you have a NVidia GPU
python -m llama_cpp.server --host 0.0.0.0 --model .\model\Meta-Llama-3-8B-Instruct.Q2_K.gguf --n_ctx 2048 --n_gpu_layers 28这将启动与OpenAI标准兼容的FastAPI服务器。你应该会得到类似这样的内容:
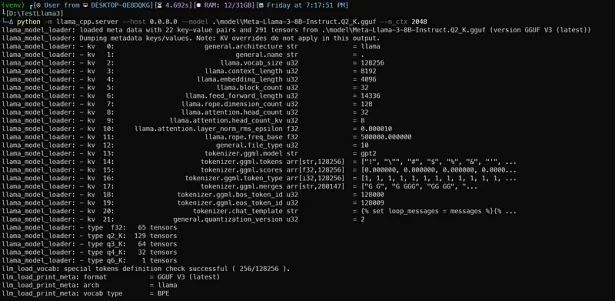
当服务器准备就绪时,Uvicorn将用漂亮的绿色灯光消息通知你:
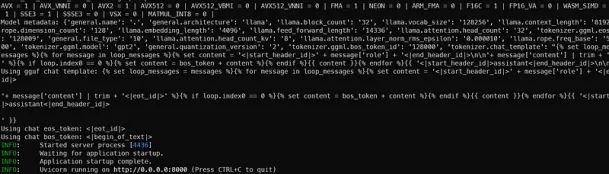
注意:这里只设置了2048个标记作为上下文:实际上,Llama3确实有8192个标记可用于上下文,但这也会消耗RAM或VRAM,因此我们暂时将其保持较低(以防止GPU崩溃)。
- 注意2:这个8B参数模型确实有33个层,但我只将其中的28个层加载到了GPU上。你可以尝试自己加载多少层而不会使其崩溃。
- 注意3:在这个示例中,我使用了Q2版本的Meta-Llama-3-8B-Instruct.Q2_K.gguf。将其替换为Q4_K_M文件名以运行4位量化版本。
另一个终端窗口用于显示我们的极其简短(但有用)的 Python 代码。在激活了venv 的情况下运行:
python .\ Llama3 - ChatAPI。py
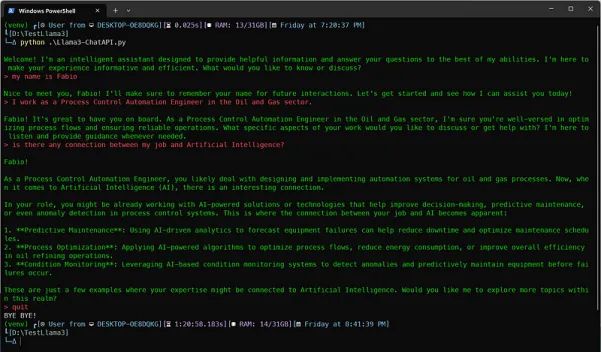
你已经准备好了。随便提出你想问的问题,然后尽情享受吧。
以下是我的问题…
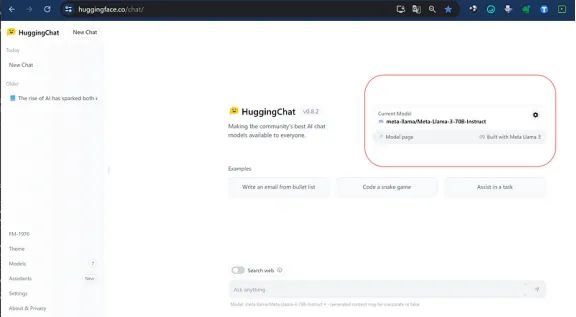
Bonus Track — 你可以在 Hugging Face Chat 上免费运行它。
如果你很懒或者想尝试一下 70B 型号版本,你可以直接在 HuggingFace Hub Chat 上进行(https://huggingface.co/chat/?source=post_page—–a563c6a47f49——————————–)
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Fabio Matricardi
翻译作者:诗彤
美工编辑:过儿
校对审稿:Jason
原文链接:https://generativeai.pub/llama3-is-out-and-you-can-run-it-on-your-computer-a563c6a47f49





