
为什么2024年将最终成为苹果的人工智能年
在所有的大型科技巨头中,有一家公司在2023年的人工智能革命中沉睡。
或者我们是这样认为的。
苹果,资本主义历史上最有价值的公司和品牌,终于通过闪存大语言模型(LLM)的展示,详细说明了其在生成式人工智能方面的意图,这一发现可以改变我们部署人工智能的方式,并使其在我们的生活中无处不在。
如果你想了解更多关于人工智能的相关内容,可以阅读以下这些文章:
2024年每个开发人员都需要掌握的生成式人工智能技能
Google的Gemini AI模型:揭开人工智能的未来
世界上最好的人工智能模型:谷歌DeepMind的Gemini已经超过了GPT-4!
我尝试了50种人工智能工具,以下是我的最爱
主要的短期结果是什么?
将iPhone和所有其他苹果硬件转变为全新的数字产品。
效率年
去年,马克·扎克伯格预测“2023年将是效率年”。
当然,他的意思是削减成本。但就我们而言,2024年,苹果正在考虑人工智能的颠覆。
内存问题
如果2023年是人类发现可以训练大型模型的一年,那么2024年将是我们学会高效运行这些大型模型的那一年。
但为什么这一点如此重要,为什么苹果要把重点放在这里呢?
基本上,苹果的整个人工智能价值主张都是消费端硬件,因此实现被认为是Generative AI模型服务圣杯的东西,在智能手机等消费端硬件上运行巨大的LLM,对他们的战略至关重要。
但这不是一件小事。为了理解原因,让我们看一个例子。
LLM由两个文件组成:
- 存储模型参数的权重文件,
- 以及一个可执行的python/javascript/C/etc文件,其中包含模型的架构,并负责在需要时通过查询模型来运行推理。
如果我们以LLaMa 27B为例,以今天的标准来看,这是一个很小的模型,那么仅权重文件就占用了14GB的DRAM内存,因为它具有半精度浮点格式。
什么是半精度?
半精度意味着每个参数占用16位,即2个字节的内存。由于我们有70亿个,这意味着你只需要140亿字节或14GB来承载该模型。
这几乎是iPhone 15 Pro(8GB)RAM容量的两倍,这意味着即使是非常小的LLM模型也无法在智能手机上使用。
而对于更大的模型,则需要一个最先进的GPU集群,需要数十万美元的投资。
然而,如果你想运行GPT-4这样的模型,这只是小钱,因为像OpenAI这样的公司每天都在烧钱,甚至更多。
从表面上看,尽管LLM有可能完全颠覆智能手机市场,除非我们找到办法将智能手机的RAM容量增加数倍,否则这是一项不可能完成的任务,而这在短期内是不可能实现的。
或者你可以利用苹果最近的突破。
Flash LLM
为了理解苹果公司的重大突破有多重要,我们首先需要了解LLM是如何运行的。
访问问题
一般来说,计算机利用两种类型的内存:闪存和RAM。
前者主要用于存储,而后者则作为计算机的“工作空间”,在任何给定时间都可以更快地访问。
除此之外,默认情况下,今天几乎所有(如果不是全部的话)大型语言模型都是Transformers,这是一种构建序列到序列模型的开创性人工智能架构。
但为什么这很重要?
简而言之,Transformers模型在每次预测时(在ChatGPT的每个单词的情况下)都是完全运行的。
因此,尽管Transformers产生了惊人的结果,但它们需要将整个模型存储在快速访问内存(即RAM)中,因为你需要以最小的延迟连续访问它。
但如果我们可以将它们存储在闪存中而不增加延迟呢?
这将改变一切,因为虽然iPhone 15 Pro只有8GB的RAM,但它有128GB的闪存。
在这种情况下,我们可以在智能手机中部署庞大的LLM,在适合我们的模型中发挥当今人工智能的力量。
稀疏性和大块
用外行的话来说,Apple 所做的就是创建了第一个可以在存储在闪存中的同时高效运行的 LLM。
尽管该模型仍然需要像其他程序一样加载到RAM中,但苹果的研究人员利用前馈层的稀疏性仅加载模型的重要部分。
正如多篇论文所证明的那样,比如Falcon LLM的论文以及我最近的一篇Medium文章所涵盖的那样,前馈层是Transformer架构中的一个重要部分,它是出了名的稀疏,这意味着它层中的大多数神经元在大多数时候都不会激发。
因此,苹果研究人员的系统所做的只是将每次推理所需的模型部分加载到RAM中。
这为我们提供了两全其美的结果:一个比RAM限制大得多的模型,同时存储在闪存中,没有延迟影响。
为了预测哪些神经元将被激活,它们包括一个小型预测网络,该网络在推理发生之前估计需要什么神经元,并先发制人地将它们加载到RAM中。
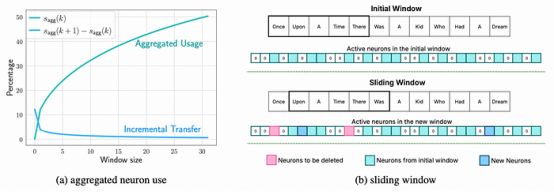
此外,为了提高效率,他们引入了窗口化的概念,只存储一定数量的先前预测的神经元激活。
通常,除了权重之外,神经元激活也倾向于存储,因为它们在文本序列的逐字预测中大多是冗余的,从而节省了计算资源。
利用这样一个事实,即对于大序列,新神经元激活的数量逐渐减少(如下所示),仅保留最近预测的激活不会影响性能,同时大大减少了内存需求。
但他们并没有就此止步。
有趣的是,检索到的数据块越大,闪存吞吐量就越高,因为整个检索过程包括操作系统、驱动程序、中断处理和闪存控制器等系统。
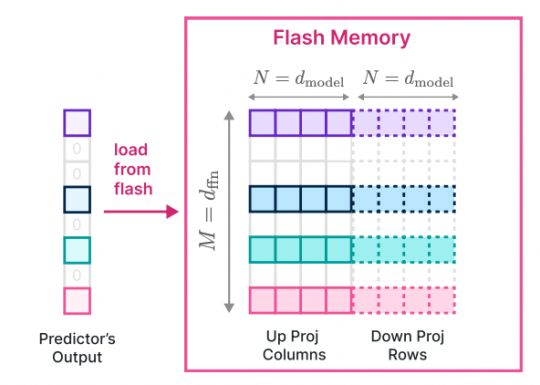
因此,每次检索的数据越多越好。然后,为了利用这一点,他们存储了上投影层和下投影层的串联行和列,以从闪存中读取更大的连续块,通过读取更大块来提高吞吐量。
但是什么是上投影层和下投影层?
前馈层通常由堆叠在一起的不同线性层的组形成。这些层包括不同数量的神经元,研究人员对维度进行上采样或下采样,以增加模型的参数数量,从而发现新的模式(模型越大,结果越好)。
因此,向上投影层和向下投影层分别是对模型的维度进行上采样和下采样的层,尽管我们希望增加维度以增加参数数量,但我们也希望将维度恢复到原始状态,以使FFn层与模型的其余部分兼容。
简单地说,它们不必将所需的数据单独加载到DRAM中,而是将所有层连接在一起加载:
最后,除了加载所有所需的数据和优化闪存检索吞吐量外,苹果的研究人员还进行了最后一次优化。
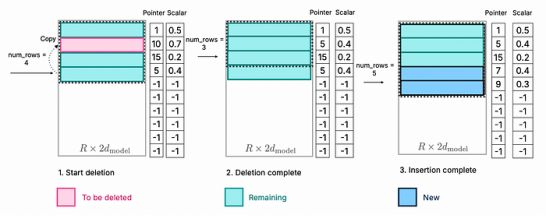
为了有效地管理已经加载的DRAM数据,每次删除模型的一部分(因为这不是推理所必需的)时,都会以预先分配的模式将要保留的神经元复制到该空间中,而新需要的神经元则堆叠在最后,从而避免了多次复制整个数据。
但真正的问题是,这对我们所有人意味着什么?
AI iPhone
众所周知,2024年苹果将在其产品中大规模引入生成式 AI。
通过其秘密的“Ajax”项目,以及最近的创新,如我们今天讨论的创新和他们的Ferret开源模型,我认为iPhone明年将有4种发展方向。
- 高级个人助理:长话短说,Siri增强了。它将可以访问你的所有应用程序、笔记和数据。更重要的是,Siri可以演变成一个真正的人工智能伴侣,利用你的健康应用程序、社交媒体和其他类型的数据为你提供更多价值。
- 实时通用翻译:文本和对话的即时翻译,实现不同语言之间的无缝沟通。
- 改进的快捷方式:无需使用糟糕的快捷方式生成器,只需使用简单的文本指令按需创建iPhone快捷方式。
- 增强型创作工具:用于音乐、艺术和写作的协作工具,有助于和增强创作过程。
还有很多很多,对于第4点,谷歌已经将LLM应用于Google Pixel 8上的照片编辑。
此外,随着时间的推移,我们可以看到人类和机器之间的互动越来越依赖于声音,而不是屏幕,这与Humane的AI Pin类似,尽管我认为这种情况不会很快发生。
与此同时,苹果公司终于明确了他们正在做什么,而且它可能比表面上看到的要大得多,这意味着我的预测可能与苹果公司明年最终交付的产品相比相形见绌。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Ignacio de Gregorio
翻译作者:文杰
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/apple-flash-llms-cb0aadd67ed6





