
LLMs能否取代数据分析师?
分析师日常工作中合作是核心要素。经常,我们会遇到高层要求,如“新功能的影响会是什么?”或者“留存情况如何?”在着手撰写查询和提取数据之前,我们通常需要更清晰地定义任务:与利益相关者交流,充分了解他们的需求,并确定我们如何能够提供最佳帮助。
对于由LLM提供支持的分析师来说,掌握提出和解决后续问题的艺术是必不可少的,因为我无法想象一个分析员在孤立无援的情况下工作。
在本文中,我们将教导我们的LLM分析师提问明确的问题并进行长时间对话。我们将详细讨论LangChain中不同的内存实现。如果你想了解更多关于自然语言处理的相关内容,可以阅读以下这些文章:
长文总结自然语言处理 Interview 新题型
自然语言处理增强大法好!最易上手的 Augmentation Techniques有哪些?
Google的Gemini AI模型:揭开人工智能的未来
NLP不是你想的那样
LLM agents recap
让我们快速回顾一下关于LLM agents(代理)的内容。
我们已经讨论了如何通过外部工具来增强LLM代理。这有助于它们克服一些限制(例如,在数学任务上表现不佳),并获得访问世界的能力(例如,你的数据库或互联网)。
LLM代理的核心思想是利用LLM作为推理引擎来定义需要采取的行动,并利用工具。因此,在这种方法中,你不需要硬编码逻辑,只需要让LLM做出在后续步骤中实现最终目标的决策。
我们已经实现了一个由LLM驱动的代理,它可以与SQL数据库一起工作并回答用户的请求。
自上次迭代以来,LangChain已从0.0.350版本升级到0.1.0版本。LLM代理的文档和最佳实践已经发生了变化。这个领域在快速发展,因此工具的演变也就不足为奇。让我们快速回顾一下。
首先,LangChain已经显著改进了文档(https://python.langchain.com/docs/modules/agents/agent_types/),现在你可以清晰、有条理地查看支持的代理类型以及它们之间的区别。
模型更容易与具有单个输入参数的工具一起工作,因此一些代理存在这样的限制。然而,在大多数实际情况下,工具需要多个参数。因此,让我们关注那些能够处理多个输入的代理。这使我们只剩下了三个可能的选择。
01 OpenAI工具
这是最先进的代理类型,因为它支持聊天记录、多输入工具甚至并行函数调用。
你可以将它与最新的OpenAI模型(1106之后)一起使用,因为这些模型针对工具调用进行了微调。
02 OpenAI函数
OpenAI函数代理接近于OpenAI工具,但在引擎盖下略有不同。
此类代理不支持并行函数调用。
你可以使用最近的OpenAI模型,这些模型经过微调,可以与函数一起工作(完整列表在这里),或者使用兼容的开源LLMs。
03 结构化聊天
这种方法与ReAct类似。它指示代理遵循思考->行动->观察框架。
它不支持并行函数调用,就像OpenAI函数方法一样。
你可以将其用于任何模型。
此外,你可以注意到我们在前一篇文章中尝试过的实验代理类型,如BabyAGI、Plan-and-execute和AutoGPT,仍然不在建议选项中。它们可能会在以后加入(我希望如此),但现在我不建议在生产中使用它们。
阅读新文档后,我终于意识到OpenAI工具和OpenAI功能代理之间的区别。使用OpenAI工具方法,一个代理可以在同一迭代中调用多个工具,而其他代理类型则不支持此类功能。让我们来看看它是如何工作的,以及为何如此重要。
让我们创建两个代理—OpenAI工具和OpenAI功能。我们将赋予它们两个工具:
get_monthly_active_users返回城市和月份的活跃客户数。为了简化调试,我们将使用一个虚拟函数。在实际操作中,我们会进入数据库检索这些数据。
percentage_difference计算两个指标之间的差值。
让我们使用Python函数创建工具,并使用Pydantic指定模式。如果你想回顾一下这个主题,可以在本系列的第一篇文章中找到详细解释。
from pydantic import BaseModel, Field
from typing import Optional
from langchain.agents import tool
# define tools
class Filters(BaseModel):
month: str = Field(description="Month of the customer's activity in the format %Y-%m-%d")
city: Optional[str] = Field(description="The city of residence for customers (by default no filter)",
enum = ["London", "Berlin", "Amsterdam", "Paris"])
@tool(args_schema=Filters)
def get_monthly_active_users(month: str, city: str = None) -> int:
"""Returns the number of active customers for the specified month.
Pass month in format %Y-%m-01.
"""
coefs = {
'London': 2,
'Berlin': 1,
'Amsterdam': 0.5,
'Paris': 0.25
}
dt = datetime.datetime.strptime(month, '%Y-%m-%d')
total = dt.year + 10*dt.month
if city is None:
return total
else:
return int(round(coefs[city]*total))
class Metrics(BaseModel):
metric1: float = Field(description="Base metric value to calculate the difference")
metric2: float = Field(description="New metric value that we compare with the baseline")
@tool(args_schema=Metrics)
def percentage_difference(metric1: float, metric2: float) -> float:
"""Calculates the percentage difference between metrics"""
return (metric2 - metric1)/metric1*100
# save them into a list for future use
tools = [get_monthly_active_users, percentage_difference]要测试工具,可以使用以下命令执行。
get_monthly_active_users.run({"month": "2023-12-01", "city": "London"})
# 4286
get_monthly_active_users.run({"month": "2023-12-01", "city": "Berlin"})
# 2183让我们为代理创建一个提示模板。它将包括一条系统消息、一个用户请求和一个用于工具观察的占位符。我们的提示有两个变量:input和agent_scratchpad。
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
# defining prompt
system_message = '''
You are working as a product analyst for a e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
'''
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])让我们使用新的LangChain函数来创建代理—create_openai_functions_agent和create_openai_tools_agent。要创建代理,我们需要指定参数—一个LLM模型、一个工具列表和一个提示模板。除了代理,我们还需要创建代理执行器。
from langchain.agents import create_openai_tools_agent, create_openai_functions_agent, AgentExecutor
from langchain_community.chat_models import ChatOpenAI
# OpenAI tools agent
agent_tools = create_openai_tools_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
agent_tools_executor = AgentExecutor(
agent = agent_tools, tools = tools,
verbose = True, max_iterations = 10,
early_stopping_method = 'generate')
# OpenAI functions agent
agent_funcs = create_openai_functions_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
agent_funcs_executor = AgentExecutor(
agent = agent_funcs, tools = tools,
verbose = True, max_iterations = 10,
early_stopping_method = 'generate')我使用了ChatGPT 4 Turbo模型,因为它能够与OpenAI工具配合使用。我们需要一些复杂的推理,因此ChatGPT 3.5可能无法满足我们的使用要求。
我们已经创建了两个代理执行器,现在是时候在实践中试用它们并比较结果了。
user_question = 'What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?'
agent_funcs_executor.invoke(
{'input': user_question,
'agent_scratchpad': []})
agent_tools_executor.invoke(
{'input': user_question,
'agent_scratchpad': []})
# In December 2023, the number of customers in London was 4,286, and in Berlin,
# it was 2,143. The percentage difference between the number of customers
# in London and Berlin is -50.0%, indicating that London had twice
# as many customers as Berlin.有趣的是,代理返回的结果同样正确。这并不奇怪,因为我们使用的是低温。
两个代理都表现出色,但让我们来比较一下它们在引擎盖下是如何工作的。我们可以打开调试模式(执行langchain.debug=True),查看调用LLM的次数和使用的令牌。
下面是两个代理的调用方案。
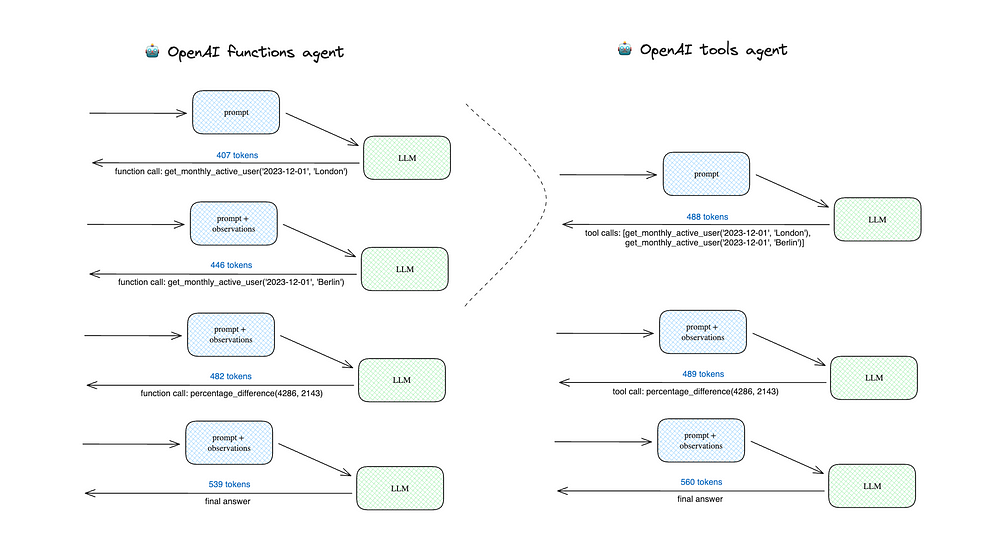
OpenAI功能代理进行了4次LLM调用,而OpenAI工具代理只进行了3次,因为它可以在一次迭代中获得London和Berlin的MAUs。总体而言,这导致使用的代币数量减少,因此价格降低:
- OpenAI工具代理——1537个代币
- OpenAI功能代理——1874个代币(+21.9%)。
因此,我建议你考虑使用OpenAI工具代理。你可以在ChatGPT 4 Turbo和ChatGPT3.5 Turbo中使用它。
我们已经修改了之前实施的LLM驱动的分析师。因此,现在是时候继续教我们的代理提出后续问题了。
提出明确的问题
我们希望教我们的代理向用户提出澄清性问题。教LLM代理学习新知识的最合理方法就是给他们提供一个工具。因此,LangChain提供了一个便捷的工具—Human。
它并不复杂。你可以在这里看到实现过程。我们可以自己轻松实现它,但使用框架提供的工具是一种很好的做法。
让我们启动这样一个工具。我们不需要指定任何参数,除非我们想自定义某些内容,例如工具说明或输入函数。更多详情,请参阅文档(https://api.python.langchain.com/en/latest/tools/langchain_community.tools.human.tool.HumanInputRun.html)。
from langchain.tools import HumanInputRun
human_tool = HumanInputRun()我们可以查看默认工具的说明和参数。
print(human_tool.description)
# You can ask a human for guidance when you think you got stuck or
# you are not sure what to do next. The input should be a question
# for the human.
print(human_tool.args)
# {'query': {'title': 'Query', 'type': 'string'}}让我们把这个新工具添加到代理的工具包中,并重新初始化代理。我还调整了系统信息,以鼓励模型在没有足够细节时提出后续问题。
# tweaking the system message
system_message = '''
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions based on the data you provide. So, you are extremely accurate with the numbers you provided.
If you're not sure about the details of the request, you don't provide the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
If you don't have enough context to answer question, you should ask user the follow-up question to get needed info.
You don't make any assumptions about data requests. For example, if dates are not specified, you ask follow up questions.
Always use tool if you have follow-up questions to the request.
'''
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# updated list of tools
tools = [get_monthly_active_users, percentage_difference, human_tool]
# reinitialising the agent
human_input_agent = create_openai_tools_agent(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
tools = tools,
prompt = prompt
)
human_input_agent_executor = AgentExecutor(
agent = human_input_agent, tools = tools,
verbose = True, max_iterations = 10, # early stopping criteria
early_stopping_method = 'generate')现在,是时候试一试了。代理刚刚返回了输出结果,要求输入一个特定的时间段。它并没有像我们预期的那样工作。
human_input_agent_executor.invoke(
{'input': 'What are the number of customers in London?',
'agent_scratchpad': []})
# {'input': 'What are the number of customers in London?',
# 'agent_scratchpad': [],
# 'output': 'To provide you with the number of customers in London,
# I need to know the specific time period you are interested in.
# Are you looking for the number of monthly active users in London
# for a particular month, or do you need a different metric?
# Please provide the time frame or specify the metric you need.'}代理不明白它需要使用这个工具。让我们试着解决这个问题,修改此工具的描述,让代理更清楚地知道什么时候应该使用这个工具。
human_tool_desc = '''
You can use this tool to ask the user for the details related to the request.
Always use this tool if you have follow-up questions.
The input should be a question for the user.
Be concise, polite and professional when asking the questions.
'''
human_tool = HumanInputRun(
description = human_tool_desc
)更改后,代理使用了人工工具,并询问了一个特定的时间段。我提供了一个答案,我们得到了正确的结果—伦敦在2023年12月有4286名活跃客户。
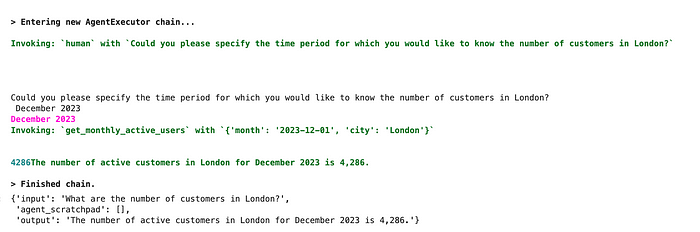
因此,像往常一样,调整提示符会有所帮助。现在,效果相当不错。请记住,创建一个好的提示是一个反复的过程,值得尝试多个选项并评估结果。
我们已经教会我们的LLM代理在处理数据请求时询问细节并将其考虑在内。
然而,这只是合作的一部分。在现实生活中,分析师在提供任何研究后经常会收到后续问题。现在,我们的代理无法跟上对话并解决用户提出的新问题,因为它没有任何内存。是时候进一步了解我们在LangChain中实现内存的工具了。
实际上,在当前的代理实现中,我们已经有了内存的概念。我们的代理将其与工具的交互故事存储在agent_scratchpad变量中。我们不仅需要记住与工具的交互,还需要记住与用户的对话。
内存链
默认情况下,LLM是无状态的,不会记住以前的对话。如果我们希望代理能够进行长时间的讨论,我们需要以某种方式存储聊天记录。LangChain提供了一系列不同的内存实现方式,让我们来了解更多。
ConversationBufferMemory是最直接的方法。它只是保存你推送给它的所有上下文。让我们尝试一下:初始化一个记忆对象并添加几个对话交流。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory()
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
# Human: Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.这种方法效果很好。然而,在许多情况下,将之前的整个对话传递给每次迭代的LLM是不可行的,因为:
- 我们可能会达到上下文长度限制
- LLM不太擅长处理长文本
- 我们正在为代币付费,这种方法可能会变得相当昂贵。
所以还有另一种实现方式ConversationBufferWindowMemory,它可以存储有限数量的对话交流。因此,它只会存储最后的k个迭代。
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k = 1)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# Human: Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.我们用k = 1来说明它是如何工作的。在实际用例中,你可能会使用更高的阈值。
这种方法可以帮助你控制聊天记录的大小。但是,它有一个缺点:你仍然可以达到上下文大小限制,因为你不能在令牌中控制聊天历史记录的大小。
为了解决这个问题,我们可以使用ConversationTokenBufferMemory。它不会拆分语句,所以不用担心上下文中的句子不完整。
from langchain.memory import ConversationTokenBufferMemory
memory = ConversationTokenBufferMemory(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
max_token_limit=100)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.
#: the whole info since it fits the memory size
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.buffer)
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.
#: only the last response from the LLM fit the memory size在这种情况下,我们需要传递一个LLM模型来初始化内存对象,因为LangChain需要知道模型来计算令牌的数量。
在我们上面讨论的所有方法中,我们都存储了确切的对话或至少部分对话。然而,我们不需要这样做。例如,人们通常不会准确地记住他们的对话。我不能逐字逐句地复制昨天会议的内容,但我记得主要的思想和行动项目——一个总结。由于人类是GI(通用智能),因此将此策略用于LLM也是合理的。LangChain在ConversationSummaryBufferMemory中实现了它。
让我们在实践中尝试一下:启动记忆并保存第一次对话交流。我们得到了整个对话,因为我们当前的上下文还没有达到阈值。
from langchain.memory import ConversationSummaryBufferMemory
memory = ConversationSummaryBufferMemory(
llm = ChatOpenAI(temperature=0.1, model = 'gpt-4-1106-preview'),
max_token_limit=100)
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.load_memory_variables({})['history'])
# Human: Hey, how are you? How was your weekend?
# AI: Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.让我们再添加一个对话交换。现在,我们已经达到了极限:整个聊天记录超过了100个令牌,这是指定的阈值。因此,只存储最后一个AI响应(它在100个令牌限制内)。对于早期的消息,已经生成了摘要。
摘要以System:前缀存储。
memory.save_context(
{"input": "Could you please help me with the urgent request from our CEO. What are the absolute numbers and the percentage difference between the number of customers in London and Berlin in December 2023?"},
{"output": "In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin."}
)
print(memory.load_memory_variables({})['history'])
# System: The AI had a good weekend learning about LLM agents and describes it as magical. The human requests assistance with an urgent task from the CEO, asking for the absolute numbers and percentage difference of customers in London and Berlin in December 2023.
# AI: In December 2023, the number of customers in London was 4,286, and in Berlin, it was 2,143. The percentage difference between the number of customers in London and Berlin is -50.0%, indicating that London had twice as many customers as Berlin.像往常一样,看看它是如何在引擎盖下工作是很有趣的,我们可以在调试模式下理解它。当会话超过内存大小的限制时,LLM调用将发出以下提示:
Human: Progressively summarize the lines of conversation provided,
adding onto the previous summary returning a new summary.
EXAMPLE
Current summary:
The human asks what the AI thinks of artificial intelligence. The AI
thinks artificial intelligence is a force for good.
New lines of conversation:
Human: Why do you think artificial intelligence is a force for good?
AI: Because artificial intelligence will help humans reach their full
potential.
New summary:
The human asks what the AI thinks of artificial intelligence. The AI thinks
artificial intelligence is a force for good because it will help humans reach
their full potential.
END OF EXAMPLE
Current summary:
New lines of conversation:
Human: Hey, how are you? How was your weekend?
AI: Good morning, I had a wonder time off and spent the whole day learning
about LLM agents. It works like magic.
Human: Could you please help me with the urgent request from our CEO.
What are the absolute numbers and the percentage difference between
the number of customers in London and Berlin in December 2023?
New summary:实现了摘要的渐进式更新。因此,它使用更少的令牌,而不是每次传递整个聊天历史记录以获得更新的摘要。这是合理的。
此外,LangChain还有更高级的内存类型:
- 向量数据存储器——将文本嵌入存储在向量存储器中(类似于我们在RAG中所做的——检索增强生成),然后我们可以检索最相关的信息位并将它们包含到对话中。这种记忆类型对于长时间的对话是最有用的。
- 实体记忆用来记住特定实体(如人)的细节。
你甚至可以组合不同的内存类型。例如,你可以使用会话内存+实体内存来保存数据库中表的详细信息。要了解有关组合内存的更多信息,请参阅文档:https://python.langchain.com/docs/modules/memory/multiple_memory。
我们不会在本文中讨论这些更高级的方法。
我们已经了解了如何在LangChain中实现内存。现在,是时候将这些知识用于我们的代理了。
向代理添加内存
让我们试着看看当前的代理实现如何处理用户的后续问题。
human_input_agent_executor.invoke(
{'input': 'What are the number of customers in London in December 2023?',
'agent_scratchpad': []})对于这个呼叫,座席执行了一个工具并返回了正确的答案:
The number of active customers in London in December 2023 was 4,286.我们知道伦敦的用户数量,了解柏林也会很有趣,问问我们的代理吧。
human_input_agent_executor.invoke(
{'input': 'And what about Berlin?',
'agent_scratchpad': []})令人惊讶的是,代理能够正确地处理这个问题。然而,它必须使用Human工具澄清问题,并且用户必须提供相同的信息(不是最佳的客户体验)。
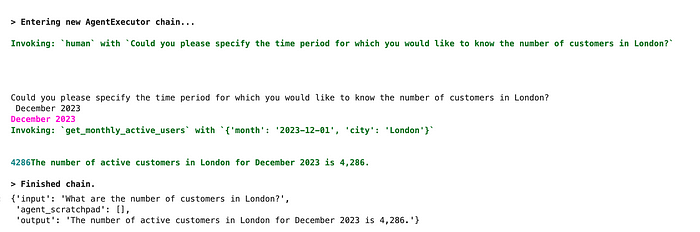
现在,让我们开始为代理保留图表历史记录。我将使用一个简单的缓冲区来存储之前的完整对话,但是你可以使用更复杂的策略。
首先,我们需要将聊天历史记录的占位符添加到提示模板中。我把它标记为可选的。
prompt = ChatPromptTemplate.from_messages([
("system", system_message),
MessagesPlaceholder(variable_name="chat_history", optional=True),
("user", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])接下来,让我们初始化内存并保存一个简短的对话(你知道,没有简短的对话是不可能进行聊天的)。注意,我们已经指定了与提示模板中相同的memory_key = ‘chat_history ‘。
memory = ConversationBufferMemory(
return_messages=True, memory_key="chat_history")
memory.save_context(
{"input": "Hey, how are you? How was your weekend?"},
{"output": "Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic."}
)
print(memory.buffer)让我们再次尝试前面的用例,并向LLM分析师询问伦敦的用户数量。
human_input_agent_executor.invoke(
{'input': 'What is the number of customers in London?'})
# {'input': 'What is the number of customers in London?',
# 'chat_history': [
# HumanMessage(content='Hey, how are you? How was your weekend?'),
# AIMessage(content='Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.'),
# HumanMessage(content='What is the number of customers in London?'),
# AIMessage(content='The number of active customers in London for December 2023 is 4,286.')],
# 'output': 'The number of active customers in London for December 2023 is 4,286.'}在回答了“Could you please specify the time period for you want to know the number of customers in London”这个问题后,我们得到了正确的答案,以及agent和用户之间的对话历史,包括之前的所有陈述,包括闲聊。
如果我们现在询问关于Berlin的后续问题,代理只会返回2023年12月的数字,而不会询问细节,因为它已经在上下文中有了。
human_input_agent_executor.invoke(
{'input': 'What is the number for Berlin?'})
# {'input': 'What is the number for Berlin?',
# 'chat_history': [HumanMessage(content='Hey, how are you? How was your weekend?'),
# AIMessage(content='Good morning, I had a wonderful time off and spent the whole day learning about LLM agents. It works like magic.'),
# HumanMessage(content='What is the number of customers in London?'),
# AIMessage(content='The number of active customers in London for December 2023 is 4,286.'),
# HumanMessage(content='What is the number for Berlin?'),
# AIMessage(content='The number of active customers in Berlin for December 2023 is 2,143.')],
# 'output': 'The number of active customers in Berlin for December 2023 is 2,143.'}让我们看一下第一个LLM调用的提示符,我们可以看到,所有的聊天记录实际上都传递给了模型。
System:
You are working as a product analyst for the e-commerce company.
Your work is very important, since your product team makes decisions
based on the data you provide. So, you are extremely accurate
with the numbers you provided.
If you're not sure about the details of the request, you don't provide
the answer and ask follow-up questions to have a clear understanding.
You are very helpful and try your best to answer the questions.
If you don't have enough context to answer question, you should ask user
the follow-up question to get needed info.
You don't make any assumptions about data requests. For example,
if dates are not specified, you ask follow up questions.
Always use tool if you have follow-up questions to the request.
Human: Hey, how are you? How was your weekend?
AI: Good morning, I had a wonderful time off and spent the whole day
learning about LLM agents. It works like magic.
Human: What is the number of customers in London?
AI: The number of active customers in London for December 2023 is 4,286.
Human: What is the number for Berlin?因此,我们将聊天记录添加到我们的LLM驱动的分析师中,现在它可以处理一些较长的对话并回答后续问题,这是一项重大成就。
你可以在GitHub上找到完整的代码:
总结
在本文中,我们教会了我们的LLM分析师如何与用户协作。现在,如果最初的请求中没有足够的信息,它可以提出澄清性的问题,甚至可以回答用户的后续问题。
我们取得了如此显著的进步:
- 通过添加一个工具——人工输入,允许用户询问,
- 通过向代理添加可以存储聊天记录的内存。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Mariya Mansurova
翻译作者:Qing
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/can-llms-replace-data-analysts-learning-to-collaborate-9d42488dc327





