如何利用ML构建推荐系统?

我可以为你进行一些推荐吗?”——图片来自作者
在这篇文章里,我们将分析2023年1月底结束的“OTTO-多目标推荐系统(https://www.kaggle.com/competitions/otto-recommender-system/)”竞赛的技术和方法,从中吸取教训,并将最佳方案应用到我们自己的数据科学项目中。如果你想了解更多关于推荐系统的相关内容,可以阅读以下这些文章:
用Python构建Amazon产品推荐系统
详解Netflix推荐系统:他们是如何做到这么受欢迎的?
推荐系统,比你更懂你
TikTok如何利用推荐系统,比你更懂你?
问题:多目标推荐系统
“OTTO-多目标推荐系统”竞赛,要求参赛者建立一个隐式用户数据的大型数据集的多目标推荐系统(RecSys)。
现如今,在电子商务行业,你的“竞争对手”们正在处理以下内容:
- 多目标:点击量、添加购物车数量、订单量
- 大型数据集:超过2亿个事件,涉及约180万件商品
- 隐式用户数据:用户会话中以前发生的事件
如何处理大型项目数据库的RecSys
这场比赛有一个很大的挑战,即参赛者有着大量的商品可供选择,而将所有可用信息输入到复杂模型中需要大量的计算资源。
因此,参赛者们通常会两步走:精准推荐/重新排序技术:
阶段1:精准推荐
这一步骤将每个用户的潜在推荐数量从数百万减少到大约50到200。为了处理数据,这一步通常会使用一个相对简单的模型。
阶段2:重新排序
你可以在这一步使用更复杂的模型,例如ML模型。在你对减少后的推荐进行了排序后,你就可以选择排序最高的商品作为推荐。
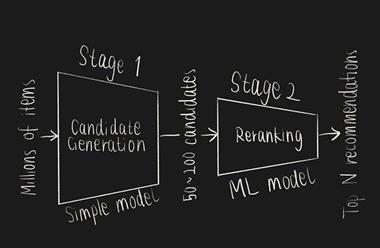
阶段1:使用Co-Visitation矩阵生成精准推荐
两步走的第一步是将潜在推荐的数量从数百万减少到大约50到200。为了处理大量的商品,第一个模型应该很简单。
你可以选择(并组合)不同的策略来减少商品数量:
- 根据用户历史记录
- 根据受欢迎程度(这种策略非常有用)
- 根据基于co-visitation矩阵的共现
其中最简单的方法是根据用户历史记录:如果用户查看过某个商品,他们很可能也会购买。
然而,如果用户查看的商品(例如,五件商品)少于我们希望为每个用户生成的推荐数量(例如,50到200个),我们可以通过商品受欢迎程度或共现来填充推荐列表。由于根据受欢迎程度这个方法很简单,因此我们将在本节中重点介绍通过共现产生的推荐列表。
通过两个商品的共现产生的推荐可以用co-visitation矩阵来处理:如果user_1在购买item_a之后不久又购买了item_b,我们就可以存储该信息。
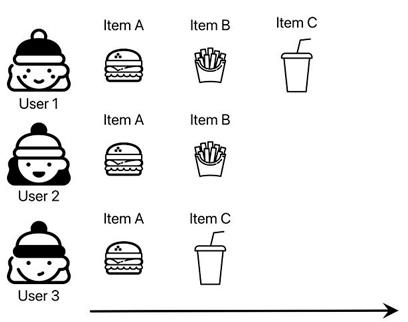
- 对于每个商品,计算指定时间范围内其他商品的出现次数。
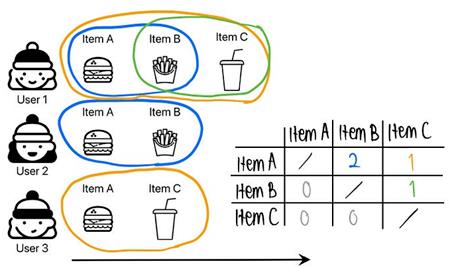
- 对于每个商品,找出该商品之后访问次数最多的50到200个商品。
正如你从上面的图片中看到的,co-visitation矩阵不一定是对称的。例如,买了汉堡的人可能会买饮料,但也很有可能不会。
你也可以根据接近度为co-visitation矩阵指定权重。例如,在同一会话中一起购买的商品可能比用户在不同购物会话中购买的商品具有更高的“重量”。
co-visitation矩阵类似于通过计数进行矩阵分解。矩阵分解是推荐系统中一种很流行的技术,具体来说,是一种协作过滤方法,用于查找商品和用户之间的关系。
阶段2:使用GBDT模型重新排序
第二步是重新排序。虽然你可以亲自动手制定规则以获得良好性能,但理论上来说,ML模型会更出色。
你可以使用不同的梯度下降树(GBDT)ranker,如XGBRanker和LGBMRanker。
准备训练数据和特征工程
GBDT ranker模型的训练数据应包含以下列类别:
- 精准推荐中的用户和商品对-数据帧的基础应是第一阶段生成的推荐列表。对于每个用户,你应该以N_CANDIDATES结束,因此,开始应该是(N_USERS * N_CANDIDATES, 2)数据帧。
- 用户特征-计数、聚合特征、比率特征等。
- 商品特征-计数、聚合特征、比率特征等。
- 用户-商品特征(可选)-你可以创建用户-商品交互功能,例如“单击商品”
- 标签-对于每个用户-商品对,合并标签(例如,“已购买”或“未购买”)。
生成的训练数据帧应该如下所示:
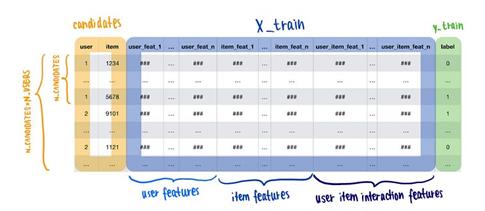
GBDT ranker模型
这一步的目的是训练GBDT rancker模型以选择top_N推荐。
GBDT ranker接收以下三个输入:
- X_train,X_val:包含特征的训练和验证数据帧
- y_train,y_val:包含标签的训练和验证数据帧
- group(请注意,特征不包含用户、商品列。因此,模型需要关于在哪个组中对商品进行排序的信息):[N_CANDIDATES] * (len(train_df) // N_CANDIDATES)
下面是XGBRanker的示例代码:
import xgboost as xgb
dtrain = xgb.DMatrix(X_train,
y_train,
group = group)
# Define model
xgb_params = {'objective' : 'rank:pairwise'}
# Train
model = xgb.train(xgb_params,
dtrain = dtrain,
num_boost_round = 1000)下面是LGBMRanker的示例代码:
from lightgbm.sklearn import LGBMRanker
# Define model
ranker = LGBMRanker(
objective="lambdarank",
metric="ndcg",
n_estimators=1000)
# Train
model = ranker.fit(X_train,
y_train,
group = group)GBDT排序模型将对指定组中的商品进行排序。要检索top_N推荐,你只需要按用户对输出进行分组,并按商品排序进行罗列。
总结
回看Kagglers在“OTTO-多目标推荐系统”竞赛过程中创建的学习资源,我们可以学到更多的教训。对于这种类型的问题,也有着许多不同的解决方案。
在这篇文章中,我们重点介绍了市场主流的通用方法:通过co-visitation matrix矩阵生成精准推荐,以减少要推荐的商品数量,然后再进行GBDT重新排序。
参考文献
- [1] Chris Deotte (2022). “Candidate ReRank Model — [LB 0.575]” in Kaggle Notebooks. (accessed 26. February 2023)
- [2] Chris Deotte (2022). “How To Build a GBT Ranker Model” in Kaggle Discussions. (accessed 21. February 2023)
- [3] Ravi Shah (2022). “Recommendation Systems for Large Datasets” in Kaggle Discussions. (accessed 21. February 2023)
- [4] Radek Osmulski (2022). “[polars] Proof of concept: LGBM Ranker” in Kaggle Notebooks. (accessed 26. February 2023)
- [5] Radek Osmulski (2022). “ Introduction to the OTTO competition on Kaggle (RecSys)” on YouTube. (accessed 21. February 2023)
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Leonie Monigatti
翻译作者:高佑兮
美工编辑:过儿
校对审稿:Chuang
原文链接:https://towardsdatascience.com/building-a-recommender-system-using-machine-learning-2eefba9a692e





