
使用功效分析Power Analysis确定A/B测试的样本量
A/B测试如今无处不在,已经成为很多人用来检验产品和方法的工具。它们常常被看做是一种更客观的方法来回答这历史悠久的问题——“哪个更好?”在我看来,进行A/B测试的过程一直是数据科学的”科学”部分的缩影。它与随机对照试验(Randomized Controlled Trials)共享许多元素,RCT不仅是临床试验的黄金标准,也是心理学实验室实验的一部分,它通过创建一个旨在隔离和测量改变一组人与另一组人的视线所见的效果的装置。
但是,由于测试需时间,而时间就是金钱,因此经常会问到样本大小的相关问题(即”我需要测试多少人?”)。理想情况下,只要你对问题有一个自信的答案,你可以选择更好的选项,并停止使用劣质版本。通过使用功效分析来确定样本大小,你可以更好地提前了解测试需要运行多长时间,然后才能自信地确认或反驳你的假设。
什么是功率分析?
为了确定运行统计稳健性测试所需的最小样本量,可以进行先验功率分析。先验是指在收集结果之前进行分析的事实。功率分析考虑4个参数之间的关系:
- 效果大小Effect Size(例如Cohen的d或h):计算实验中观察到的效果大小的标准化方法;确切的统计数据取决于正在比较的内容和所使用的假设检验:对于两种均值之间的差异,经常使用Cohen的 d,而Cohen的 h 是专门为两种比例之间的差异。
- 样本大小Sample Size(n):研究或实验中使用的观察值或人数。
- 显著性水平Significance Level(α,通常计算为 p 值):通常被视为是必须达到的阈值,才能认为结果合法;这个数字实际上意味着,如果测试重复无限次,且没有实际效果,那么观察到的结果仍将发生偶然α%的时间(也称为 I 型错误,或误报)。
- 功率Power(1-β):当你确定结果存在显著差异时正确的概率;β是指获得假阴性(或类型 II 错误)的机会,其中你当实际上有一个错误时,没有效果,所以功效表示为1-β
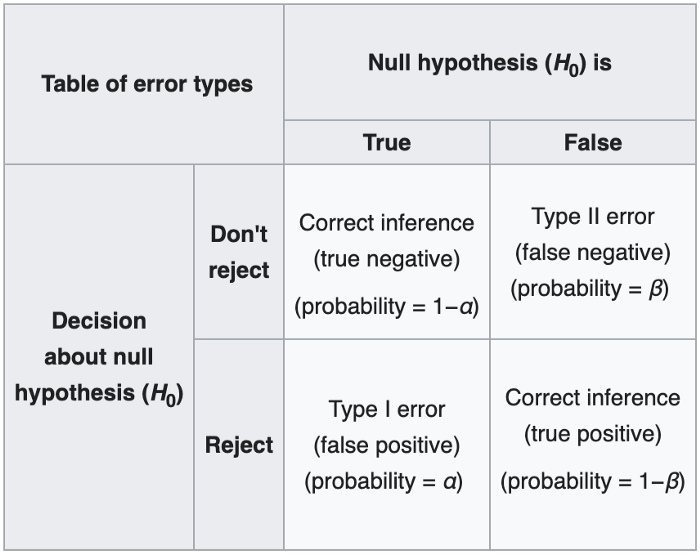
如果给定其他3个参数,那么可以解决这些参数中的任何一个;从术语上讲,先验意味着在运行实验之前完成这个分析,以便计算其他3个样本的所需样本大小。
有许多库和免费软件支持电源分析功能,我在本文末尾链接到这些库和免费软件;在这篇文章,我将使用Stephanie Champely的R软件包pwr。
估算样本量的实用分步方法
在进入下一部分中的示例之前,这里是一个常规过程概述,你可以应用于各种A/B测试用例:
- 将干预/治疗情况与背景情况建立相关,并提出初步假设;确定实验是单面还是双面
- 为功率和显著性级别设置明确的所需基准(分别视为默认值 0.80 和 0.05)
- 根据先前的数据、结果、研究等估算效果大小• 对于比例,可以参考Cohen的h;否则,Cohen的d• 在大多数情况下,可以以当前/历史基线转化率/平均值作为参考点;否则, 试点测试就足够了
- 使用先验功率分析计算样本大小(非必须的)根据利益相关者的不同,预测达到样本量所需的时间可能很有用(例如,是否对访问网页的用户进行了测试)
- 在达到样本量并进行评估之前,以 50—50 拆分运行测试• 通过运行适当的假设检验来评估结果• 如果效果大小不显著,那么效果大小可能小于最初预期,因此需要更大的样本大小来验证它• 如果样本大小未达到,但需要评估,则只有在效果大小大于最初效果的情况时,才可能找到显著性
- 如果需要更多数据,请继续运行测试,以更不平衡的拆分情况测试,并根据业务指标监控结果,直到有足够的信心为止• 除非对结果的方向性非常有信心,请使用双面测试;否则,则存在估计样本大小小于实际需要量的风险。
常见测试:
- Proportions:Z检验(例如转换率、打开率)
- Means:t检验(例如,操作次数,花费的金额)
当然,在这里完成测试并确定与正在测试的任何干预没有显著区别可能是合理的。通常,在这个计划的停止点重新评估,以确定是否值得进一步测试(额外的技术资源、时间等),并尝试了解为什么结果没有像最初预期的那样产生如此大的影响,这是一个良好做法。
注意:如果从同一总体随机拆分不是A/B 测试的选项(例如比较两个”相似”国家/地区),那么可能需要考虑应保持恒定的分布或相关指标。
示例:A/B测试应用在线上购物网站上测试不同的主页横幅
假设,我们为一家服装品牌工作,计划推出一个新的季节性系列产品。作为新品发布计划的一部分,我们计划在主页顶部横幅上展示这个集合,目标是最大限度地提高点击率(CTR)。
有人建议在我们的横幅中宣传销售,以吸引更多的访问者,因此我们的产品团队建议对测试受众进行 A/B 测试,以决定使用哪个横幅用于公开发布,并确定我们确定我们需要多少人。
首先,我们需要找到我们细分受众群中预期单击这个横幅广告的用户比例。通过查看以前发布的系列,我们可以获得一个横幅广告通常的效果基线,了解我们的横幅通常执行得如何:假设此CTR点击率为5%。从这里出发,我们需要估计一下,我们预计销售将带来多少提升。
假设我们也知道,产品的和销售吸引一些有相同特点的人。由于促销是我们客户的主要驱动力,因此我们的这些横幅的CTR通常位于10%—20%范围内,这最终可能导致我们保守估计,同时发布销售和发布的横幅广告将具有15%的CTR。
我们可以从中计算效果大小(Cohen的h),并将其插入我们的功率分析函数中,以获得所需的最小样本大小,即132(每组),如果我们使用默认基准的显著性和功效。
# Simple power analysis example in R
> library(pwr)
# Calculate Cohen's h
> ES.h(.15, .05)
[1] 0.344372
# Leave n blank here to produce sample size; two-sided indicates that we are test for a difference in either direction
> pwr.2p.test(h = 0.3444, n = , sig.level = 0.05, power = 0.80, alternative = "two.sided")
Difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.3444
n = 132.3458
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: same sample sizes现在,这里的因素应该受到良好的控制。如果我们在假期期间推出产品,我们的销售信息可能会与客户产生不同的共鸣,而只是一个随机的周末。如果这个网站最近进行了重新设计,那么过去的数据可能无效,无法用作比较的基础。同样,对于新品发布本身,需要考虑许多可能影响客户预期和期望水平的因素。
例如,如果我们的收藏集与知名艺术家合作,我们可能期望由于新的非常规因素的影响,产生更好的效果和预期的点击率,这将影响我们的效果大小,从而影响我们的样本大小:
# Suppose we added a flat 5% to everything
> ES.h(.2, .1)
[1] 0.2837941
> pwr.2p.test(h = 0.2838, n = , sig.level = 0.05, power = 0.80, alternative = "two.sided")
Difference of proportion power calculation for binomial distribution (arcsine transformation)
h = 0.2838
n = 194.9
sig.level = 0.0
power = 0.8
alternative = two.sided
NOTE: same sample sizes无论测试如何,考虑所有因素都至关重要,这些因素不仅会影响你的实验,而且会影响你的总体目标。例如,在我们的示例中,最大化点击率可能实际上不会提高销售额。如果我们想要优化花费的预算,我们可以执行不同的功效分析,因为我们最终会使用假设检验来比较手段(如t检验),而不是比例。幸运的是,我们的方法仍然将保持非常相似 – 我们可能只是看历史转化率,我们可能只是看看之前的销售的成功,以确定新的效果规模。
估计效果大小可能很难,特别是首次执行A/B测试而且缺少以前的数据时。如果指标确实未知(0.2=小;0.5 =中等;0.8=大),那么可以替代效果大小的公认的基准,但只有随着时间的推移,经验才能帮助你直观地了解效果如何转化为业务应用程序。对较大样本进行测试通常总是会提高结果的准确性和可信度,但这显然是以资源成本发生为代价的,无论是时间、开发人员资源还是实验本身的成本。
A/B测试是一个功能强大的工具,可以帮助你快速重申和改进你的设计。通过采取科学的方法,你可以减少试验,而发现最好的候选人。通常,A/B测试结果可以带你获得新的、令人惊讶的见解,这将有助于加深你对消费者的理解,有时还会迫使你重新思考以前的假设。
开发支持和衡量A/B测试的基础架构和方法可能是解开所有这些测试的第一步,但当然,始终必须牢记大局是非常重要的。对特定成功指标进行建立可能会忽略更改如何影响你的基础的不同细分市场部门为代价,这不仅会产生道德影响,还可能会影响业务的长期发展轨迹。因此,在解释结果时,批判性地思考如何和是什么时候使用 A/B 测试等工具以及考虑所有相关上下文,始终很重要。
有用的库和工具
Pwr包(R):专为用于电源分析而使用的热门R软件包
https://cran.r-project.org/web/packages/pwr/pwr.pdf
统计模型:包含Z测试t测试电源分析功能的Python 统计库:
• Z 测试:https://www.statsmodels.org/stable/generated/statsmodels.stats.power.zt_ind_solve_power.html
• t 测试:https://www.statsmodels.org/stable/generated/statsmodels.stats.power.tt_ind_solve_power.html
pingouin:Python 库,它已经移植了R的pwr包中的一些power功能
https://pingouin-stats.org/api.html#power-analysis
G*Power:用于运行电源分析的 Windows/Mac的免费工具,用于整个学术界
原文作者:The Data Standard
翻译作者:陈奕霖Eilleen
美工编辑:过儿
校对审稿:Dongdong
原文链接:https://medium.com/swlh/determining-sample-sizes-for-a-b-testing-using-power-analysis-34719ce9e0e9





