
谷歌的新WebAgent对其自身的生存构成威胁?
这说不通啊,谷歌为什么要这么做?如果你想了解更多关于谷歌的相关内容,可以阅读以下这些文章:
ChatGPT竞争对手来了?谷歌开放Bard访问权——第一印象如何?
谷歌官宣大数据平台-BigQuery
谷歌数据科学家面试真题
为什么谷歌把SQL当代码对待?你也应该这样做!
这是许多人在谷歌DeepMind发布了一篇关于其最新网络自主代理(名为“WebAgent”)的研究论文后可能会问的问题,这是人工智能领域又一次艰苦的命名工作。
但奇怪的是,制造代替人类上网的机器人,违背了谷歌商业模式的核心——互联网广告,并可能在这个过程中抹杀谷歌的存在。
与此同时,WebAgent在自主网络搜索方面树立了新的技术标杆,通过引入模块化、局部-全局注意力等几个概念,让我们看到了人工智能架构的未来,这些概念让我们更接近这样一个未来:你只需简单地提出需求,互联网将轻松满足你。
对于某些任务,普通的LLM无法胜任
在人们幻想使用大型语言模型(LLM)的许多用例中,自主网络搜索无疑占据了最重要的位置。
网络搜索商品化
这个想法太吸引人了,让人无法不憧憬:
任何旅游预订,任何产品,任何博客文章…都只需通过一条文本指令即可实现。
也就是说,自主的、以文本为条件的网络搜索描述了一组机器人代理,通过简单地给它们一个纯文本指令来为你在网络上搜索:
- “给我订一张去Dallas的头等舱机票”,或者
- “给我找本月最畅销的科幻小说”
其吸引力是显而易见的,但实现自主网络代理绝非易事……
永远存在的泛化问题
正如Michael Jordan(来自加州大学,而不是篮球运动员)最近所说,尽管LLM将泛化问题最小化,但它仍然是人工智能中最大的问题之一。
但他这句话的真正含义是什么呢?
对于构建的每个人工智能模型,目标始终是相同的,使用一些已知的数据分布——训练数据——使模型能够在未见数据上进行良好的预测。
然而,即使是最先进的模型,当分布变化足够大时,模型也很可能会失败。
例如,如果你训练你的模型识别照片中的房子,并且只给它提供了红色的两层楼的训练数据,模型也许能够识别紫色的两层楼的房子——这是一个小的分布变化——但如果你给他看一座白色的纽约摩天大楼,模型肯定会迷失方向。
换句话说,无论GPT-4等生成式人工智能的基础模型如何推动人工智能向前发展,当巨大的分布变化出现时,即使是最通用的模型也会受到影响。
这就引出了网络代理面临的最大问题。从本质上讲,网络搜索是开放式的,这意味着代理搜索的下一个网站可能与前一个网站截然不同。
因此,尽管LLM确实有很好的能力来理解搜索意图的语义,但由于HTML代码的极端波动性,它们在处理HTML代码时会受到影响。
但这并不是人工智能网络代理面临的唯一问题,还涉及到大小的问题。
HTML绝非易事
上下文窗口。
这两个词对你来说可能不太熟悉,但对像ChatGPT这样的LLM来说非常重要。在特定的互动过程中,模型可以使用一定量的工作记忆来记住之前的互动。
例如,当你以来回的方式与ChatGPT交谈时,你希望它记住你之前的提示以及对这些提示的回答,以确保对话继续进行。
原因我们今天就不讲了,这个“记忆”越长,模型创建新预测(ChatGPT中的单词)的成本就越高,因为这种预测的计算成本与上下文窗口的长度呈二次关系。
通俗地说,如果你将文本序列大小增加一倍,则计算成本将增加四倍。
因此,今天所有的模型都对这种工作记忆有一定的限制。就ChatGPT而言,最多有32,000个标记,或26,000个单词。
但在开源模型的情况下,大多数模型很难达到2000个标记,或1500个单词。
为什么这一点很重要呢?
很简单,根据谷歌的数据,HTML页面的平均标记数在7,000到14,000之间,这对于今天的大多数LLM来说是不可能完成的任务。
因此,谷歌必须跳出思维定势。
他们确实做到了。
引入HTML-T5
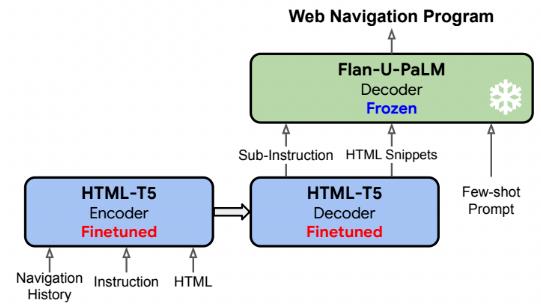
为了实现这一令人难以置信的壮举,WebAgent由一个新的、领域特定的LLM——HTML-T5组成。
考虑到大多数LLM对HTML的归纳偏差较大(这是一种不必要的花哨说法,他们不擅长对新的HTML代码进行泛化),他们决定训练一个新的LLM模型来做两件事。
在收到HTML代码和用户指令后:
- 该模型准备了一个计划,将用户指令分解为标准的基于Web的操作,如填写表单字段或单击按钮。
- 然后,对于每个子指令,它分析完整的HTML代码,并提取与该子指令最相关的代码片段。
再然后,这些输出被发送到一个Flan-U-PaLM模型,一个专门生成代码的Google LLM。
为什么?
简单来说,为了弥补开放式网络搜索的差距,其中不同的操作选项很多,与浏览器交互的最佳方式是通过代码,使用Selenium API(一个允许通过代码控制Web浏览器的API库)。
我知道这很难理解,所以请看看下面的图片:
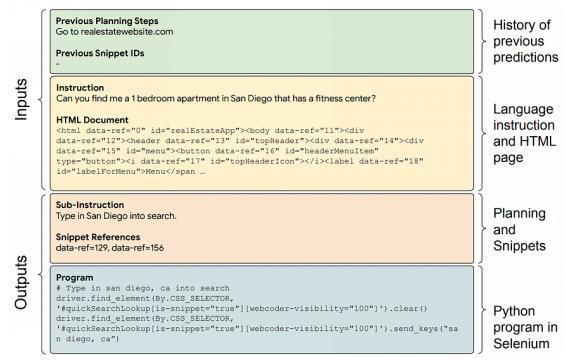
在用户要求WebAgent导航到一个房地产网站并找到一个位于圣地亚哥的带健身中心的一居室公寓任务后,WebAgent将该指令分解成几个子指令,例如:
- 访问realestatewebsite.com
- 在搜索框中输入圣地亚哥
- 用“包括健身中心”过滤搜索
然后,对于每个子任务,HTML-T5模型会提取最相关的代码片段引用,并将该代码片段和子指令发送给FLAN-U-PaLM模型,然后该模型继续生成Selenium Python代码,该代码将在浏览器上执行操作,过程如下所示:
但是,HTML-T5如何处理超长序列(如real网站的HTML代码)呢?
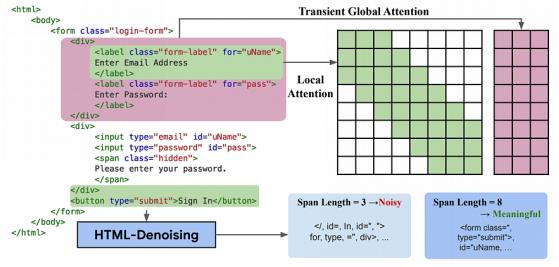
HTML-T5使用局部和全局注意力的组合。
注意力是Transformer LLMs的关键要素。简而言之,它是机器理解自然语言的方式,通过让序列中的单词相互“交谈”,生成注意力分数,向模型传达单词之间的关联性,从而获得序列的实际含义。
在标准的Transformer中,这种注意力机制是“密集”和“局部”的,这意味着单词与所有(密集)附近的单词(局部)进行交谈。
在这里,谷歌采取了不同的方法。
虽然局部注意力仍然需要理解细粒度HTML标记,如‘<span>’或‘<image>’的语义,但HTML这样的树状结构代码包含了如‘<div>’或‘<body>’这样的父标记,这需要注意力机制远远超出附近的标记。
HTML-T5将全局注意力与局部注意力相结合,能够更好地捕获长HTML文档的语义。通过查看下面的图片,可以清晰的看到这种组合的效果:
此外,WebAgent取得了哪些成果?它击败了一些模型。
WebAgent为自主网络代理设立了一个新的技术标杆。
让开,新的王者在这里。
与以往的大多数网络代理相比,在real网站上使用时的成功率在10%到20%之间,而WebAgent的成功率则飙升至65%,高出3到6倍。
但最令人印象深刻的是,当他们将HTML-T5(只是WebAgent的一部分)与一个流行的网络搜索基准进行比较时。
它不仅表现得非常出色,得分高达76%,而且还击败了其他更大的模型,如Flan-T5-XXL(110亿个参数,而HTML-T5只有30亿个参数)。
但对我来说,WebAgent的意义远不止表面上看到的那么简单。
这证明了人工智能的发展方向。虽然像ChatGPT这样的通用模型肯定仍然很重要,但像HTML-T5这样的领域特定的LLM将发挥关键作用,尽管规模要小得多,但它们能够在其特定领域中发挥同样作用,甚至更好。
因此,就像几乎任何技术领域一样,像WebAgent这样结合了通用(FLAN)和领域特定(HTML-T5)两者优点的模块化模型将成为常态。
谷歌,现在怎么办?
撇开技术讨论不谈,这次发布也向搜索引擎公司发出了一个强有力的信息。
不可否认,它们的商业模式即将改变,这意味着那些无法适应的企业将面临死亡。
我的意思是,如果没有人在网上搜索,那么在网上做广告宣传又有什么意义呢?
谷歌也知道这一点,那么你认为谷歌将如何在WebAgent等模型不断变化的新环境中生存?
这不是“是否”的问题,而是“何时”的问题。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Ignacio de Gregorio
翻译作者:文玲
美工编辑:过儿
校对审稿:Chuang
原文链接:https://medium.com/@ignacio.de.gregorio.noblejas/google-webagent-f1a971577b92




