
运行大型语言模型,需要多少GPU内存?
在几乎所有的LLM面试中,都会有一个问题:“为大型语言模型(LLM)提供服务需要多少GPU内存?”
这个问题不仅仅是随意提出的——它是一个关键指标,反映了你对这些强大模型在生产环境中的部署和可扩展性的理解。
在使用GPT、LLaMA或任何其他LLM时,了解如何估计所需的GPU内存是至关重要的。无论你是在处理70亿参数的模型还是更大的模型,合理配置硬件以支持这些模型都是关键。接下来,我们将深入探讨数学原理,帮助你估算有效部署这些模型所需的GPU内存。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
大语言模型:AI如何改变医疗现状
为什么大语言模型不适合编码?
AI驱动的财务分析:多代理LLM系统将数据转化为见解
2024年打造生产级LLM应用的最佳技术栈
GPU内存估算公式
要估算为大型语言模型提供服务所需的GPU内存,你可以使用以下公式:
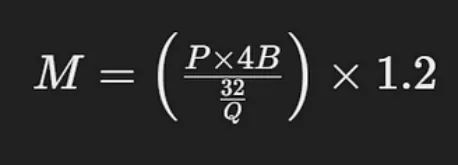
GPU内存估算公式
- M为GPU内存,单位为gb
- P是模型中参数的个数
- 4B表示每个参数使用的4个字节
- Q是用于加载模型的位数(例如,16位或32位)
- 1.2 是额外的20%内存开销
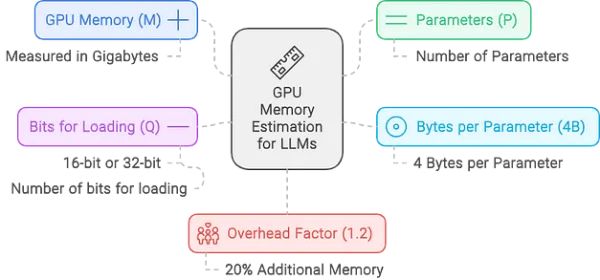
打破公式
- 参数数量 (P):表示模型的大小。例如,如果你使用的是具有70亿个参数(70B)的LLaMA模型,则该值为700亿。
- 每个参数的字节数 (4B):每个参数通常需要4字节的内存,因为浮点数精度通常占用4字节(32位)。如果你使用的是半精度(16位),则计算会相应调整。
- 每参数的位数 (Q):根据你以16位还是32位精度加载模型,该值会有所不同。16位精度在许多LLM部署中较为常见,因为它在保持足够精度的同时减少了内存占用。
- 内存开销 (1.2):1.2倍的内存增量用于增加20%的开销,以解释推理过程中使用的额外内存。这不仅是一个安全缓冲;还对在模型执行期间覆盖激活和其他中间结果所需的内存至关重要。
计算示例
让我们考虑一下,你想要估算服务于具有70亿个参数的LLaMA模型所需的内存,以16位精度加载:
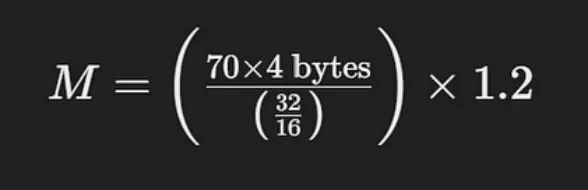
这个计算简化为:
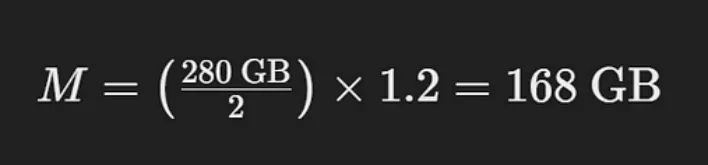
该计算表明,在16位模式下,你将需要大约168 GB的GPU内存来支持具有70亿个参数的LLaMA模型。
实际意义
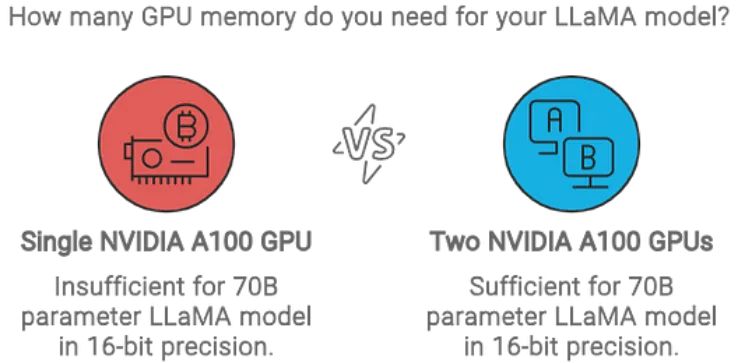
理解和应用这个公式不仅是理论上的;它在实践中同样重要。例如,一个具有80GB内存的NVIDIA A100 GPU不足以满足此模型的需求。你至少需要两个80GB的A100 GPU才能有效处理内存负载。
通过掌握这种计算方法,你将能够在面试中回答这个基本问题,更重要的是,能够在实际部署中避免代价高昂的硬件瓶颈。下次在评估部署时,你将准确知道如何估算有效为LLM提供服务所需的GPU内存。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Mastering LLM (Large Language Model)
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/@masteringllm/how-much-gpu-memory-is-needed-to-serve-a-large-languagemodel-llm-b1899bb2ab5d




