
手把手教你创建属于自己的大型语言模型!
大型语言模型(LLM)正在改变人工智能,使计算机能够生成和理解类似人类的文本,因而在各个行业中变得必不可少。全球LLM市场正在迅速扩大,预计将从2023年的15.9亿美元增长到2030年的259.8亿美元。这一增长主要源于对自动化内容创作的需求、人工智能的进步,以及对更好的人机交流的渴望。
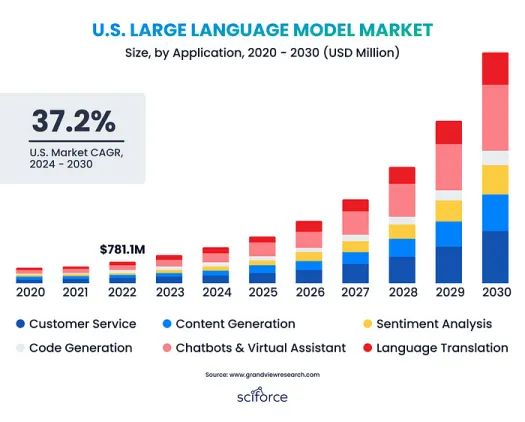
这种增长是由对自动化内容创建、AI和自然语言处理(NLP)进步、改善人机通信和大型数据集的需求推动的。随着企业寻求对数据和定制的控制权,私人LLM越来越受欢迎。它们提供量身定制的解决方案,减少对外部提供商的依赖,并增强数据隐私。本指南将帮助您建立自己的私人LLM,无论您是LLM新手,还是希望扩展专业知识,都会提供有价值的帮助。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
大语言模型:AI如何改变医疗现状
为什么大语言模型不适合编码?
AI驱动的财务分析:多代理LLM系统将数据转化为见解
2024年打造生产级LLM应用的最佳技术栈
什么是大型语言模型?

大型语言模型(LLM)是先进的人工智能系统,通过使用复杂的神经网络(如变压器)处理大量数据,生成类似人类的文本。它们可以创建内容、翻译语言、回答问题和参与对话,使其在包括客户服务和数据分析等各个行业中都非常有价值。
自回归LLM专注于编码和重建文本,擅长情感分析和信息检索等任务。混合LLM结合了这两种方法的优势,为复杂的应用程序提供了通用的解决方案。LLM通过处理来自各种来源的大量文本来学习语言规则,类似于阅读大量书籍帮助人们理解语言。一旦训练完成,它们就可以利用所学知识撰写内容、回答问题并参与对话。
例如,LLM可以根据阅读太空冒险故事的知识创作一个关于太空的故事,或者通过回忆生物课本中的信息来解释光合作用。
建立一个私人LLM
LLM数据管理
最近的LLM,如Llama 3和GPT-4,都是在庞大的数据集上训练的——Llama 3有15万亿个令牌,GPT-4有6.5万亿个令牌。这些数据集来自不同的环境,包括社交媒体(140万亿个令牌)和私人数据,规模从数百TB到数PB。这种广泛的训练确保模型深入理解语言,涵盖各种模式、词汇和上下文。
- Web数据:FineWeb(未完全去重以获得更好的性能,全部英文)、Common Crawl(55%为非英文)
- 代码:来自所有主要代码托管平台的公开可用代码
- 学术文本:Arxiv、Google Scholar、Google Patents
- 书籍:Google Books、Arxiv
- 法庭文件:RECAP档案(美国)、开放法律数据(德国)
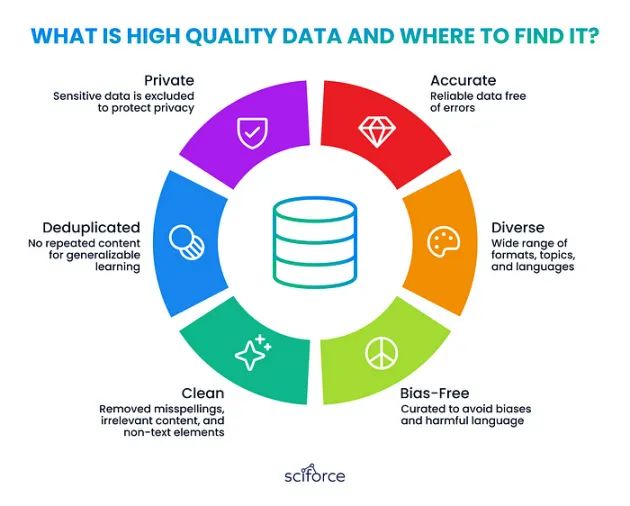
数据预处理
在为LLM整理数据时,关键步骤包括数据清理和结构化,使用标记化、嵌入和注意力机制将数据转换为模型可以学习的格式:
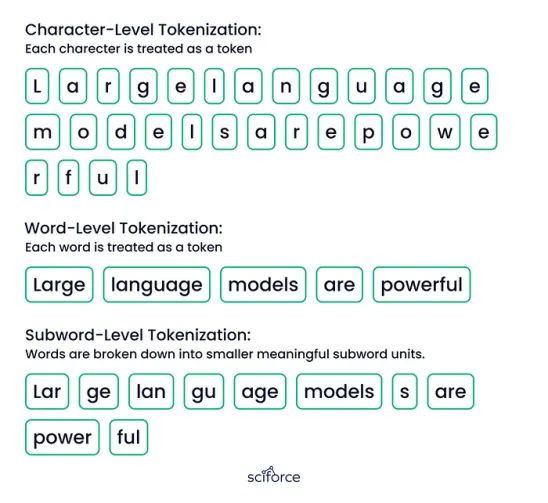
- 标记化:将文本分解成更小的部分,如单词或字符,允许模型有效地处理和理解每个部分。
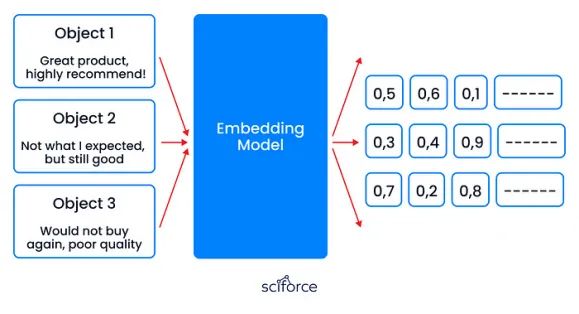
- 嵌入:将客户评论转换为捕捉情感和意义的数字向量,帮助模型分析反馈并改进建议。
- 注意力:集中在句子中最重要的部分,确保模型准确地把握关键情绪,例如区分产品质量和服务问题。

LLM培训循环
数据输入和准备
- 数据摄取:从各种来源收集和加载数据。
- 数据清理:去除噪声,处理缺失数据,编辑敏感信息。
- 规范化:对文本进行标准化,分类处理数据,确保数据一致性。
- 分块:在保留上下文的情况下,将大文本分成可管理的块。
- 标记化:将文本块转换为用于模型处理的标记。
- 数据加载:有效加载和洗牌数据,以优化训练,必要时使用并行加载。
损失计算
- 计算损失:使用损失函数将预测值与真实标签进行比较,将差异转换为“损失”或“误差”值。
- 性能指标:损失越大,精度越差;较低的损失表明与实际目标更一致。
超参数调优
- 学习率:控制训练过程中的权重更新大小,过高可能导致不稳定,过低则会减慢训练速度。
- 批大小:每次迭代的样本数量,较大批次可稳定训练,但需更多内存;小批次则引入可变性,但资源消耗较低。
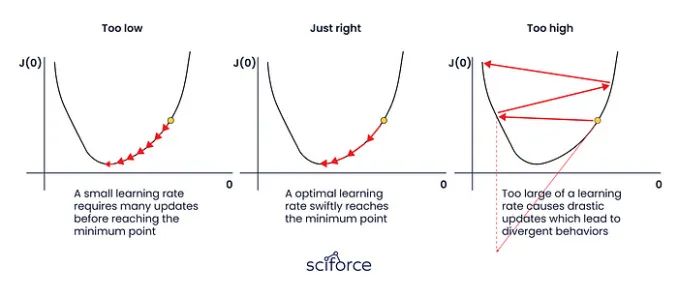
并行化和资源管理
- 数据并行化:跨多个GPU拆分数据集以实现更快处理。
- 模型并行化:将模型划分到多个GPU以处理大型模型。
- 梯度检查点:通过选择性地存储中间结果来减少训练期间的内存使用。
迭代和历元
- 迭代:处理数据批次,每次更新权重。
- 历元:完全遍历数据集,每次遍历都精炼模型的参数。
- 监控:跟踪每个历元后的损失和准确性等指标,以指导调整并防止过拟合。
评估你的LLM
在培训后评估LLM的表现对于确保其达到要求的标准至关重要。常用的行业标准基准包括:
- MMLU(大规模多任务语言理解):评估跨广泛主题的自然语言理解和推理。
- GPQA(通用问答):测试模型处理不同领域复杂问题的能力。
- 数学:通过解决多步问题来衡量模型的数学推理能力。
- HumanEval:通过评估模型生成准确、功能性代码的能力来评估编码能力。
对于那些从头开始构建LLM的人来说,Arena等平台提供动态的、用户驱动的评估,允许用户比较模型。OpenAI和Anthropic等公司定期发布GPT和Claude等模型的基准测试结果,展示LLM能力的进步。
在为特定任务微调LLM时,度量标准应与应用程序的目标保持一致。例如,在医疗环境中,可以优先考虑将疾病描述与代码匹配的准确性。

结论
构建私人LLM是一个具有挑战性但有益的过程,提供无与伦比的定制、数据安全性和性能。通过管理数据、选择正确的体系结构和对模型进行微调,您可以创建适合您需求的强大工具。
本指南概述了LLM开发的关键步骤,帮助您构建一个优秀的模型,并适应不断变化的需求。如需专家指导或开始您的LLM之旅,欢迎联系我们进行免费咨询。阅读文章的完整版本,请访问我们的网站。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Sciforce
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/sciforce/step-by-step-guide-to-your-own-large-language-model-2b3fed6422d0





