
信用卡欺诈实例:处理不平衡的数据集最常用的三种方法
在2018年,仅有不到500万人成为英国借记卡或信用卡欺诈的受害者,但总共盗窃超过20亿英镑,平均每人833英镑。 到2025年,全球信用卡欺诈损失预计将达到近500亿美元。
虽然万事达和VISA的芯片卡已经有效打击实体信用卡犯罪,但网络世界仍然受到影响。 现在,公司正在寻找能够更好地检测和防止欺诈性交易的解决方案 – 许多公司已将注意力转向利用机器学习技术的解决方案。
非平衡问题中的少数类别
检测大型数据集中的欺诈性交易会产生问题,因为它们是少数类别。 例如,每百万次交易中可能只有1,000起欺诈案件,占整个数据集的一小部分(0.1%)。
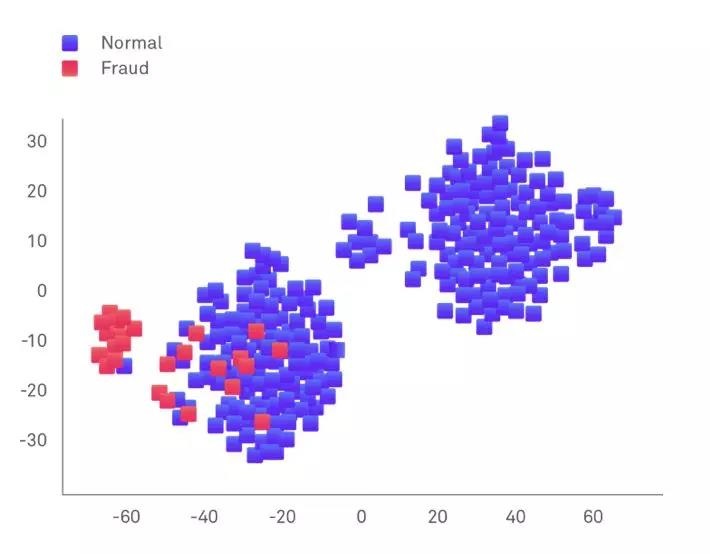
在Data Science中,这些Imbalanced Datasets可能很难分析,因为机器学习算法倾向于显示大多数类的偏差,导致误导性的结论。
例如,假设你是健身房的经理,健身房老板要求你预测每位客户在年底更新健身房会员资格的可能性。 为此,您需要检查每个成员的现有数据 – 例如访问频率,加入日期,设备偏好等 – 确定它们是否属于以下两类之一:续订还是不续订。
由于健身房的保留率异常高,因此难以分析这些数据:99%的客户已更新其会员资格。 简而言之,非续约者是少数群体。在这种情况下,一种快速简便的方法是预测100%的健身会员将在明年续约,仍然有99%的准确率。 听起来不错,对吗?
但是这种模型并不会成功,因为健身房经理 – 或算法 – 未能了解哪些健身房成员最不可能更新会员资格。 因此,尽管预测具有“良好的准确率”,但它最终没有带来任何价值。
三种处理非平衡数据集的方法:Over, under and GAN
传统上,有两种常用的处理Imbalanced datasets的方法:Oversampling和Undersampling。
Oversampling是通过在代表性不足的类别中(例如欺诈性交易)人为地产生新的样本。Data Scientists使用了许多技术进行过采样,包括SMOTE(Synthetic Minority Over-sampling Technique),它可以创建少数类的综合观测。
Undersampling以相反的方式工作:它删除过多代表类(例如非欺诈性交易)的样本数以“平衡”数据集。欠采样的最简单方法是从大多数类中随机删除观测值 – 但是使用这种技术,数据集需要足够大以减轻删除数据点所造成的影响。
基于Generative Adversarial Networks(GAN)的增强是另一种越来越受欢迎的技术。虽然Oversampling创建的合成观测与少数类中的原始观测几乎相同,但GAN希望更进一步,并生成新的独特的观测,其外观和行为更像真实数据。
这项技术最近被用于通过网站“This person does not exist”制作人造面孔的照片。 底层代码 – StyleGAN – 由Nvidia编写,使用名人面孔的数据集来生成具有随机调整的视觉特征(例如形状,大小,姿势和头发颜色)的独特图像。 结果是令人惊讶但也有些令人不安的逼真 – 但实际上完全是假的 – 人物头像。
在Hazy,我们有一系列专有的合成数据生成算法,可以扩展GAN和其他相关算法的功能。 这些模型与我们的合成数据和模型优化工具集成,使我们能够为每个特定用例选择最佳的生成算法。 因此,生成的Hazy数据针对每个客户端的数据结构以及他们希望解决的问题进行了优化。
这对信用卡欺诈意味着什么
银行和金融机构需要一种能够重新平衡其数据集并正确识别欺诈性和非欺诈性交易的解决方案。但与此同时,算法能够检测False Negatives和False Positives是至关重要的。
False Negatives描述错误标记为否定的预测。在信用卡欺诈中,这可能意味着欺诈性交易未被发现且欺诈者成功从客户的账户中窃取资金。
False Positives是当算法实际为负时,算法错误地识别出正预测。这可能导致银行在实际上没有欺诈行为时阻止客户的帐户。
最终,如果数据不平衡,即使是准确率达到99%的模型,也会出现大量False Negatives和False Positives – 只有平衡的数据集才能为金融界的欺诈行为提供快速有效的解决方案。
金融以外的应用
重新平衡不平衡数据集的应用程序范围广泛。 事实上,任何可以从罕见事件中收集有价值见解的行业都会在统计模型中遇到不平衡的数据问题。
例如,保险业建立在风险建模的基础之上。 极端天气或火车出轨等罕见事件在当前模型中难以预测,但最终它们可能对定价产生重大影响。
医疗专业人员也很难找到罕见的遗传性疾病,因为不平衡将他们指定为少数群体。 在这个行业中,即使是一个False Negative也可能意味着患者未被诊断,对患者数据应用有效的Rebalancing算法实际上可能是生与死之间的差异。
未来是平衡的
多年来,欺诈检测技术的投资一直在增加和发展。 我们现在在data science中拥有复杂的技术,试图解决数据不平衡的问题,例如Oversampling和Undersampling,甚至更复杂的技术似乎即将出现。
无论数据科学家倾向于哪种方法,期望的结果是自然地起作用和行为的数据 – 即与现实世界中收集的数据集相当的数据集。 如果不这样做,大量的欺诈性信用卡交易将仍然不能被发现。
原文作者:Hazy
翻译作者:Yishuo Dong
美工编辑:过儿
校对审稿:冬冬
原文链接:https://medium.com/@hazy_ai/imbalanced-data-and-credit-card-fraud-ad1c1ed011ea





