LeMA:对于一个LLM来说,学习数学就是在犯错!
大型语言模型(LLMs)在问题解决方面表现出了非凡的能力。虽然还有改进的空间,但我们可以通过哪些方法来实现呢?我们如何教会这些模型从他们的错误中学习呢?如果你想了解更多关于机器学习的相关内容,可以阅读以下这些文章:
金融中的机器学习:利用随机森林掌握时间序列分类
每个机器学习工程师都应该知道的线性代数!!
2023年面向开发者的十大机器学习(ML)工具
CPU与GPU:哪个更适合机器学习,为什么?
从未犯过错误的人,也从未尝试过任何新事物。——Albert Einstein
如何用数学语言进行交流?

“我们从失败中学习,而不是从成功中学习!” ——Bram Stoker,Dracula
大型语言模型(LLMs)以其解决复杂问题的能力令人惊叹。更大型的模型展现出在数学和问题解决方面的推理能力。此外,通过诸如思维链等提示技术,这些模型取得了显著的成果。
当然,模型并不总是得出正确答案。因此,随着时间的推移,人们提出了更多的策略,这仍然是一个活跃的研究领域。例如,模型可以在CoT数据上进行微调(由问题、答案和解释答案的基础构成的数据对)。另一种方法是在大量的数学数据、编码和STEM(科学、技术、工程和数学)方面进行微调。值得一提的例子有谷歌的Minerva和LLemma。
COT的想法源于我们如何解决数学问题:
考虑解决复杂推理任务的思维过程,比如一个多步骤的数学文字问题。通常是将问题分解成中间步骤,并在给出最终答案之前解决每一步。(COT原文:https://arxiv.org/abs/2201.11903)
还有另一个方面需要考虑,这是数学学习过程中特有的。事实上,人类从自己的错误中学习。学习数学的学生会从数学教科书中学习,然后为了巩固知识去做练习题。当然,他一开始会犯错误,但通过改正他将从自己的错误中学习。这种从错误中学习的过程将完善他的推理能力。
我们可以将学习过程定义为两个部分:
向前学习。学生阅读教科书并学习教科书提供的示例。COT模仿这一过程。
向后学习。学生从自己犯过的错误中学习以及如何改正。
那么模型如何才能从自己犯过的错误中吸取教训?
从错误中汲取教训

从他人的错误中学习。你无法活到自己犯尽所有错误的那一天。 ——Eleanor Roosevelt
最近,微软公司的研究人员受到这一过程的启发,测试了一种让模型从错误中学习的方法。
这种方法可以概括为:收集错误的推理路径(问题的解决方案是错误的),对其进行修正,并利用这些错误修正路径对模型进行微调。
为了生成这些纠错数据,需要使用多个模型(包括LLaMA和GPT系列)来回答问题并收集错误的回答。之后,作者使用GPT-4生成修正数据。这些数据用于微调语言模型。

所以我们有一个包含三个信息部分的提示:
- 错误的步骤。原始步骤至少包含一个错误。
- 解释。解释有什么样的错误以及如何修正它。
- 正确的解决方案。如何纠正错误的推理路径以得到正确的解决方案。

显然,需要进行人工评估,以确保即使模型纠正也不会出错。事实上,有一些例子表明,GPT-4生成了错误的纠正(毕竟,即使是最优秀的专家也会犯错误)。

具体方法
详细来说,作者决定在两种情境下训练模型:
- 在CoT数据上进行微调。为了建立一个强有力的基准,他们仅在问题-理由数据上训练了模型。
- 在CoT数据+纠错数据上进行微调。作者还添加了纠错数据(存在错误和纠正的路径),并将此方法称为LEMA。
为了创建COT数据,他们检索了两个大型数学问题数据集(GSM8K和MATH)。然后,他们用GPT-4对数据集进行了增广。因此,他们为这两个数据集生成了成千上万的推理路径(COT)。然后,他们过滤掉了那些错误或奇怪答案的路径。从GSM8K中得到了总共32421个例子,从MATH中得到了20009个例子。
然后他们创建了纠错数据。作者使用了几种LLMs进行此过程(LLaMA-2–70B、WizardLM-70B、WizardMath-70B、Text-Davinci-003、GPT-3.5-Turbo和GPT-4)生成不准确的推理路径。之后,他们请GPT-4进行了纠正。从GSM8K中得到了总共12523个例子,从MATH中得到了6306个例子。
作者随后在获取的数据集上对不同的模型进行了微调:LLaMA、LLaMA-2、CodeLLaMA、WizardMath和MetaMath家族。
从错误中学习能提高你的整体学习能力

经验只不过是我们赋予错误的名字。 ——Oscar Wilde
作者比较了在两项任务中仅使用CoT或使用校正训练的不同模型。结果表明,加入校正后,模型的性能有所提高。
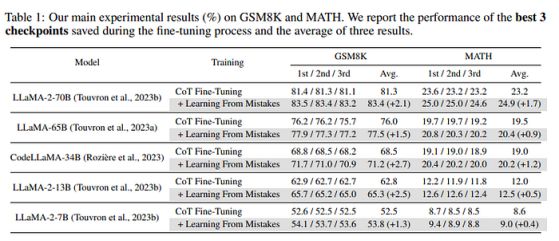
在训练过程中可直接观察到这种改进
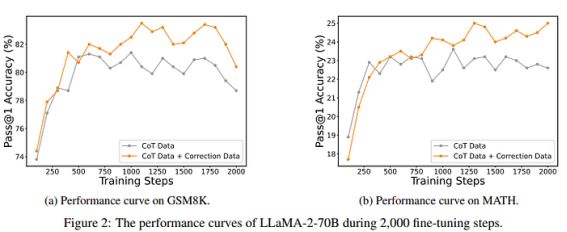
很明显,第一个反对意见是,这些模型没有在相同数量的数据基础上进行微调。事实上,仅COT中的示例较少,而如果加上修正,则会更多。以往的研究表明,影响性能的最重要因素之一是所使用的数据量。因此,作者删除了随机示例,以使两种训练(受控数据)具有可比性。可以看出,尽管微调数据集现在更加均匀,但LEMA仍然带来了相当大的改进。这表明,大型LLM比小型模型更善于从错误中学习。
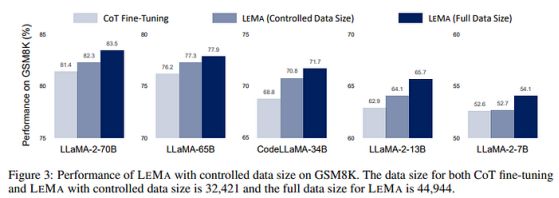
一个有趣的结果是,LEMA方法不仅提高了通用模型的性能,也提高了专用模型的性能
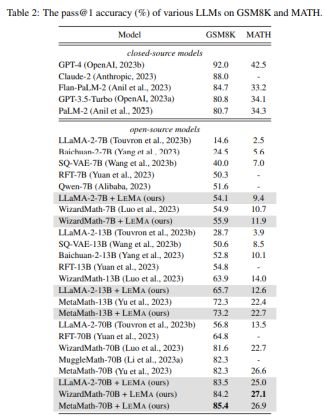
作者对校正器进行了一些研究,获得了三个有趣的结果:
- 功能较弱的模型不适合生成校正。作者测试了GPT3.5Turbo,发现约有一半的响应质量不高。
- 因此,尽管GPT-4更清晰,但它比更小的模型更好。GPT-4可以纠正自己的错误,但成功率较低。在2696个不准确的推理路径中,GPT-4仅能纠正217个自身错误(成功率为8%)。因此,GPT-4可以纠正较小模型的错误,但无法纠正自身的错误。
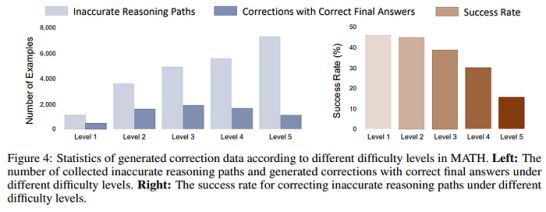
- 对于具有挑战性的问题,GPT-4仍难以纠正不准确的推理路径。MATH问题分为5个等级;随着难度的增加,模型产生的错误数量也在增加。与此同时,GPT-4在纠正错误方面也更加困难。
代码很快将在这个代码库中发布(连同数据和模型):https://github.com/microsoft/codet。
临别感言
人不可能不犯错误,但聪明和善良的人却能从他们的错误和失误中学到未来的智慧。 ——Plutarch
LLM在解决数学问题方面展现出了一定的能力,但仍有改进的空间。从数学研究中汲取经验并从错误中学习有助于学生提高,作者提出了一个有趣的框架。
当然,尽管模型表现出的结果,这并不意味着这些模型真正具备推理能力:
然而,这种多步骤生成过程并不从根本上意味着LLM具有较强的推理能力,因为它们可能仅仅模拟人类推理的表面行为,而没有真正理解精确推理所必需的基本逻辑和规则。这种不理解会导致推理过程中的错误,并需要“世界模型”的帮助,这个模型具有意识先验于掌握真实世界的逻辑和规则。(来源:https://arxiv.org/abs/2310.20689v1)
在这种情况下,真实世界将由GPT-4来代表,使不那么强大的模型也能达到更高的解析度。显然,学生可以差生的错误,但难以认识自己的错误。这正是当GPT-4需要纠正自己的错误时所发生的情况。
尽管这种方法成功地提高了不同模型的能力,但仍有改进的空间,特别是在更困难的问题上。感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Salvatore Raieli
翻译作者:Qing
美工编辑:过儿
校对审稿:Jason
原文链接:https://levelup.gitconnected.com/lema-for-an-llm-learning-math-is-making-mistakes-f758f63eaafe





