
Llama3来了!
Meta发布了Meta Llama 3,这是他们最新的开源大型语言模型,具有8B和70B参数模型。
- 新的分词器:与Llama 2相比,Llama 3使用了一个具有128K个标记词汇量的分词器,可以更有效地对语言进行编码,并且生成的标记数最多可减少15%。
- 分组查询注意:在所有模型中都实施了这一技术,使得较小的模型相比Llama2更为强大,而在Llama 2中仅在最大模型中使用。
- 使用15T个标记进行预训练,其中95%是英语内容。
- 同时在16K个GPU上进行训练,并开发了用于管理GPU正常运行时间的新工具。希望他们会发布这些工具,因为GPU利用率是我在微调过程中看到的最大挑战。
- Llama2的有趣用法:它被用来清理数据集,以便进行微调,这标志着LLM在数据质量领域的一个有趣用例。
- 新的微调方法:将推理跟踪与指令集中的偏好排序相结合,旨在减少模型幻觉和错误率,类似于OpenAI尝试的分步推理。
- 新库:TorchTune,一个pytorch原生库,用于编写,微调和实验LLM,提供了高效的内存使用和可调试的训练方案。
- 责任:Meta强调负责任的AI开发,提供信任和安全工具,如Llama Guard 2和Code Shield。
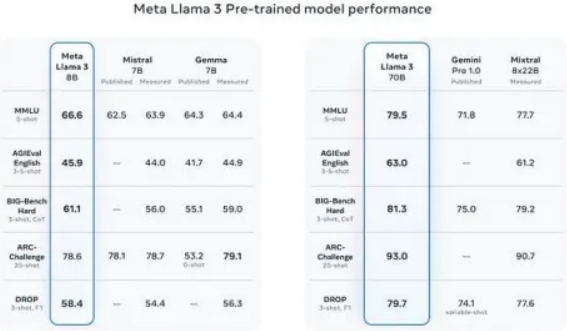
- 性能:Llama 3在性能方面树立了新的标准,拥有改进的推理能力和行业基准的最先进性能。我看到的详细基准测试主要是与Claude对比,而不是与GPT4。
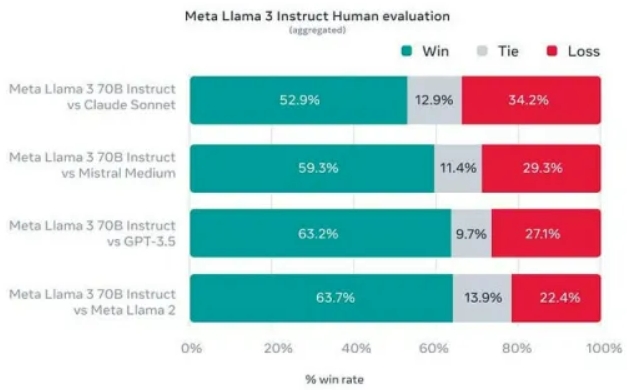
虽然它没有提供与GPT4的详细比较,也没有链接到研究论文,但这暗示了即将推出更多内容,可能是400B参数模型。早期的400B参数模型的检查结果表明,这可能是 GenAI领域的下一次重大突破。
#llama最酷的一点是,它实际上是开放的,可以在#huggingface和#watsonx等开放平台上使用。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Kunal Sawarkar
翻译作者:文玲
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/towards-generative-ai/llama3-is-here-key-takeaways-fb42e589367d





