
多智能体系统 —— Crew.AI
多代理系统是基于LLM的应用程序,正通过智能代理推动自动化的变革。在本文中,我们将探索Crew.AI。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
大型语言模型景观
利用大型语言模型进行因果推理:为什么知识和算法至关重要?
如何为你的业务选择合适的大型语言模型(LLM)
语言模型在虚假信息活动中存在误用——如何降低风险?
多智能体系统
在语言模型和人工智能领域,多代理系统涉及多个独立的参与者,这些参与者由语言模型驱动,以特定的方式协同工作。
在本博客中,我们将深入探讨Crew.AI,这是构建多代理应用的一个新兴框架。Crew.AI提供了一个框架,旨在让代理能够无缝协同工作,处理复杂任务,这种复杂度类似于一个运作良好的团队。Crew.AI的目标是让人工智能代理能够承担角色、共享目标,并作为一个凝聚力强的整体运作。
架构
Crew.AI的架构是模块化的,由几个关键组件组成,这些组件共同实现了一个精心设计的多代理系统。下图展示了该框架中构建多代理LLM应用的关键组件。
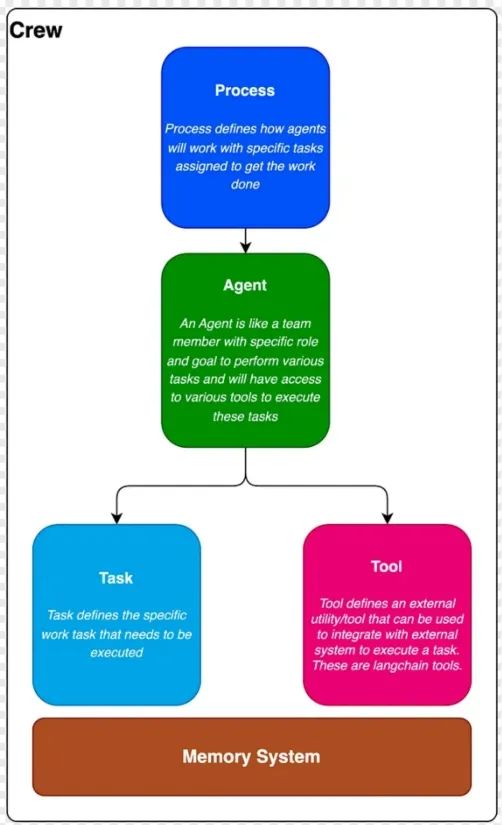
我们将从头到尾解释这张图,帮助你理解它们是如何协同工作的。
- 工具:工具是代理用来有效执行特定任务的实用工具或设备。例如,搜索网页、加载文件并读取它们等。Crew.AI是基于LangChain构建的,因此我们可以使用LangChain现有的工具,也可以编写自定义工具。
- 任务:任务是需要执行的具体操作,由代理来完成。我们为任务执行提供了多种工具。
- 代理人:代理人就像团队中的一员,拥有特定的角色、背景、目标和记忆。代理是框架中分配和执行任务的核心。每个Crew.AI代理都是一个LangChain代理,但通过ReActSingleInputOutputParser增强,该解析器经过专门修改,更好地支持角色扮演,并集成了一个上下文记忆机制,使用ConversationSummaryMemory维护上下文。
- 团队:团队由多个代理组成,共同协作完成特定目标。这些代理有明确的合作方式,来完成任务。
- 流程:流程对象是团队完成任务时遵循的工作流或策略。框架定义了三种策略(截至我写这篇文章时,未来还会增加更多)。
- 顺序:此策略按顺序执行任务,适用于流水线类型的工作,其中每个代理执行特定任务后将其传递给下一个代理。在我们今天的例子中,我们将使用这个策略为给定主题撰写一篇博客。
- 分层:该策略以分层方式组织任务,按层次结构委派任务并执行,类似于管理者将任务分配给各个代理,并在任务完成前验证结果。当我们使用此策略时,需要配置manager_llm以辅助决策。在下一篇博客中,我们将使用这个策略构建解决方案。
- 协作流程(计划):这是基于协作和民主决策的策略,代理通过相互交流来完成任务。虽然此策略尚未正式发布,但未来的博客会对此深入探讨。
更多关于这些对象和API的信息,请参考Crew.AI的文档。
构建第一个多代理系统
现在让我们开始构建第一个多代理系统,该系统将为给定主题生成标记格式的博客。
代码实现
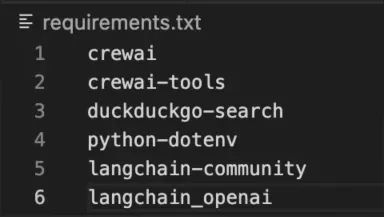
在开始之前,首先安装所有依赖项。你可以在requirements.txt文件中找到所有的Python依赖,运行pip install -r requirements.txt(确保先创建虚拟环境)以安装所有依赖。
为了构建博客多代理应用程序,我们将实现两个代理:
- researcher:负责在网上搜索给定主题并收集所有相关信息。这个代理有LLM背景,能够像研究员一样思考,收集所有关于该主题的资料。
- blogger:负责将研究员收集的内容转化为博客。
这些代理将执行以下任务:
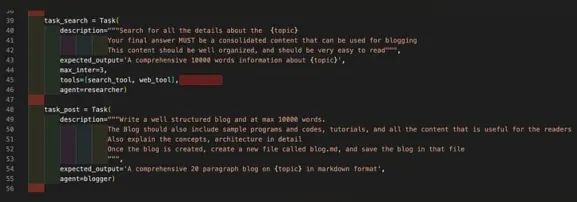
- task_search:此任务负责在网络上搜索给定主题的所有相关内容。我们将提供两个工具(DuckDuckGo搜索工具和Serper的网页搜索工具),以支持task_search代理进行全面研究。
- task_post:此任务负责撰写博客,并以Markdown格式输出。
我们的模型将在Ollama上本地运行。
代码展示
在开始编写代码之前,让我们先导入所有依赖项。
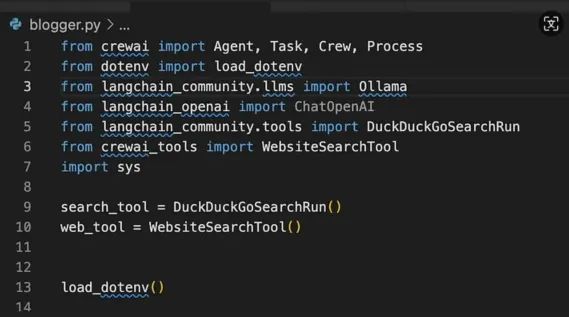
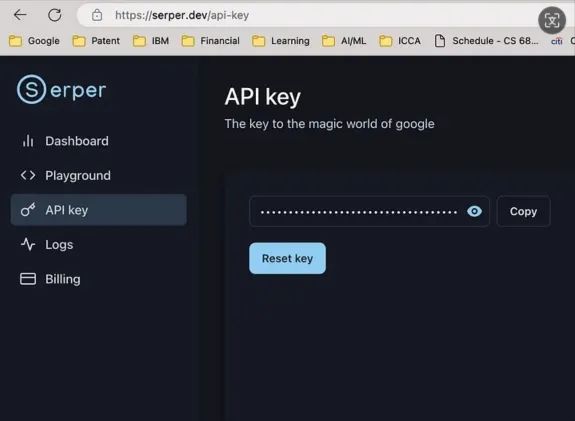
在第9和第10行中,我们定义了将要使用的各种工具。要与Serper的webtool一起使用,你需要在Serper注册,并生成API密钥,然后在环境中进行配置。下图展示了如何获取API密钥。
以下是我的.env文件,我们将使用dotenv库加载它。
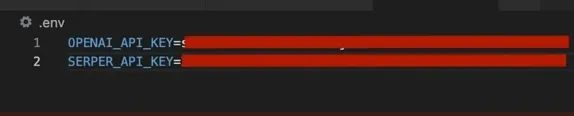
请注意,我没有使用OpenAI,但在下面的代码中展示了如何使用OpenAI(如果你不想在Ollama上运行模型)。在我的例子中,我使用Ollama本地安装了一个模型并运行它。如果你愿意,可以使用OpenAI/GPT或其他LLM。

在下面的代码中,我们定义了kickoffcrew(topic)方法。这个方法将在主博客中调用,并将主题参数传递给它,以便执行研究并生成博客。
在这个方法中,我们实例化了前文定义的两个代理Researcher和Blogger。正如你所见,我们为每个代理定义了特定的角色、目标,并设置了背景故事。所有这些都是带有上下文的提示,提供正确的提示非常重要。我必须微调过几次,才获得最佳结果,我相信对这三个参数进行进一步微调可以获得更好的效果。我们还传递了要使用的LLM,注意在这个示例中我们使用的是同一个LLM,但如果需要,也可以为不同的代理使用多个LLM,取决于代理的目标。实际上,针对代理所执行的任务选择最佳的LLM是一种好习惯,以获得最佳结果。
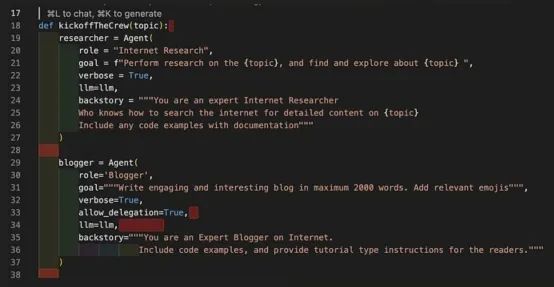
在下面的代码中,我们定义了博客中提到的两个任务——搜索和撰写博客。请注意,在task_search任务中,我们提供了执行网页搜索的工具,并指定了哪个代理将执行该任务。
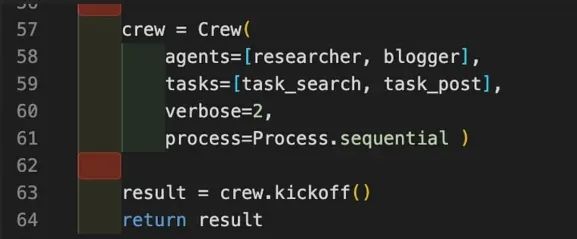
为了将任务和代理组合在一起,我们实例化了crew对象,传递了将要在其中工作的代理和任务,同时将流程策略设置为顺序。我们调用了crew的kickoff方法,让代理在提供的任务上进行工作。
在代码的主块中,我们通过命令行参数接收主题,并将该主题传递给上面定义的kickoffcrew方法,从而执行系统。
结果
现在我们运行代码。我录制了一段完整的操作视频,展示了整个代理执行过程。https://youtu.be/bEBmLw2gFIY
以下是最终生成的Markdown博客的截图。

是不是很神奇?我们可以用多智能体系统做这么多事情。我对此感到非常兴奋,并且一直在探索各种框架。我非常期待你的反馈,希望这篇博客对你有帮助。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:A B Vijay Kumar
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://abvijaykumar.medium.com/multi-agent-system-crew-ai-3773356b8c3e





