")
大厂资深面试官:我最喜欢问应聘者的编程问题(以及原因)
有很多博客和在线视频向你展示LeetCode问题的答案,但这些观点大多数是作为应聘者而不是面试官的角度。
在我在大型科技公司的25年中,我进行了一千多次面试(在亚马逊作为Bar Raiser进行了八百次,微软进行了几百次,谷歌进行了不到一百次)。
Big Tech对软件工程师有三种面试类型:
- 编码
- 系统设计
- 领导力,软技能,文化等
面试往往会结合这些方面,例如,一个SDE-I可能会有3轮编码面试,1轮设计面试,1轮领导能力面试,而一位高级工程师可能会有1轮编码面试,2轮设计面试,3轮领导能力面试。我个人更喜欢开放式的领导力面试,因为我觉得这样可以更多地了解候选人。但是编程面试是一种必要的“evil”。
现在,免责声明:所有的编程面试问题都很糟糕,包括我的问题。你只有45分钟时间来做出可能改变某人一生的雇佣建议,人们从来不是真实的自己:他们感到有压力,筋疲力尽,还有一个人为的时间限制。这些问题被设计得很牵强,以适应时间框架并获取特定的信号。我倾向于问一些简单的问题,这些问题可以带来高质量的对话,我可以了解别人的思维方式。对我来说,谈话比我的候选人在白板上写的代码行要重要得多。存在什么权衡?你如何在两者之间取得平衡?作为一名面试官,我需要知道如何帮助我的候选人获得良好的面试体验,何时引导,何时探究,并如何对人为环境进行期望值的校准。如果你想了解更多关于面试的相关内容,可以阅读以下这些文章:
50多次ML面试(作为面试官)教会了我什么?
深度学习面试的35个经典问题和答案,建议收藏!
数据科学面试中的机器学习问题类型以及如何准备这些问题?
数据/商业分析师求职,如何准备统计相关面试题
对于编程面试,我经常会问以下问题的变体,它们基于我在现实生活中不得不处理的事情。由于我决定淘汰这个问题,今天我将对其进行剖析。我在寻找什么?候选人都做了什么?
假设我们有一个网站,我们追踪客户正在查看的页面,以获取业务指标等信息。
每当有人访问网站时,我们会将一个由时间戳、页面ID和客户ID组成的记录写入日志文件。一天结束时,我们会得到一个包含许多这种格式条目的大型日志文件,这样每天都会有一个新的文件。
现在,给定两个日志文件(第1天的日志文件和第2天的日志文件),我们想要生成一个符合以下标准的“忠实客户”列表:
- (a)他们在两天都访问了网站
- (b)他们访问了至少两个独立的页面。
这个问题并不是特别难,但它确实需要一些关于代码复杂性和数据结构的思考和知识。你可以很容易地获得两天都来过的客户,你可以很容易地获得访问过至少两个独立页面的客户,但要有效地获得这两个页面的交集需要更多的工作。
我可能已经问过500遍了,这让我能够很好地校准它。我发现,根据这个问题做出的雇佣决策与最终的面试环节对候选人的雇佣决策大约有95%的一致性。我还可以根据更高级别的候选人进行升级,这使得它相当灵活,并且我可以给予在解题过程中遇到困难的候选人许多提示。
提出澄清问题
优秀的应聘者在开始写代码之前一定要问清楚问题。我希望从我的候选人那里看到一些直觉,因为我实际上用一种模棱两可的方式表达了这个问题。
我指的是每天2个独立页面还是总共2个?
这对解决方案有很大的影响。我说的是“总共2个独立页面”,因为这是一个更有趣的问题。大约一半的候选人没有澄清这一点就直接开始编码,其中一半人错误地认为我的意思是“每天2个唯一页面”。如果是资历较浅的候选人,我会在他们开始编码之前给予大量提示。如果是一个更高级的候选人,我会等一会儿,看看他们是否会更深入地思考这个算法。
在现实生活中,工程师总是要处理模棱两可的问题,并且大多数软件问题的根源可以追溯到定义不清晰的需求。因此,我希望能够获得有关发现和处理模糊性的信号。
还有一个澄清问题,90%的人在一开始就忽略了,但这也很重要:重复访问怎么处理?同一天内对同一个页面的访问算重复吗?不同天对同一个页面的访问算重复吗?对于这个问题,这些都被视为重复。
另一个需要澄清的问题是我们在这里讨论的规模是多少?数据是否适合存储在内存中?我可以将其中一个文件的内容载入内存吗?我可以同时加载两者的内容吗?
这个问题的灵感来自于我在亚马逊工作的一个真实世界的系统,叫做Clickstream,它负责跟踪亚马逊网站上的用户行为。我们在一个由10,000个主机组成的巨大MapReduce集群上处理来自数百万并发客户的PB级事件,并有一个完整的工程团队来维护和操作它。但是在一个45分钟的面试中,只需想象数据适合存储在内存中,并且范围要小得多。
最后,另一个重要的澄清问题是,性能、内存和可维护性到底有多大关系?有一个朴素的解决方案,运行时间为O(n²),但只使用O(1)内存。有一个更好的解决方案,它的运行时间为O(n),但使用的内存为O(n)。还有一个中间的解决方案用O(n log n)和O(k)的内存做一些预处理,然后主要的算法是O(n)和O(1)的内存。每一种方法都有优点和缺点。你可能用于提高性能或内存使用的一些启发式方法可能会使代码更难阅读,并在以后进行改进。对于更资深的候选人,我希望能就这些问题进行一番热烈的讨论。
首先,让我们看一下朴素的解决方案。
理论上,你可以编写一个非常简单的SQL查询,当然,大型科技公司拥有庞大的数据仓库,你可以轻松地完成这类事情。但对于编程面试的范围,你不会选择这样做。既然这不是一个分布式系统问题,并且数据适合存储在内存中,为什么要引入数据库的额外复杂性和依赖性,而这个问题可以用简单的20行代码解决呢?
起点:
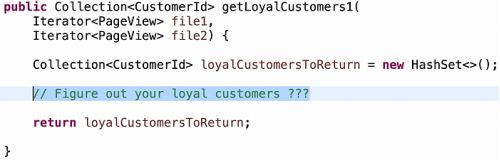
大约80%的候选人首先选择了朴素的解决方案。这是某种形式的“对于文件1中的每个元素,循环查找文件2的所有内容,查找具有相同客户ID的元素,并跟踪它们查看的页面”。
朴素解的问题在于它的运行时间是O(n²)。
我不介意先得到朴素解,但我真的希望看到我的候选人能够意识到O(n²)在任何问题中都可能不是一个好的选择。我希望那个顿悟的时刻快点到来,而且不需要提示。没有一个伟大的工程师会满足于O(n²)算法,除非受到内存或其他不可移动的约束
应聘者提出O(n²)后,我会礼貌地微笑,然后等待。我真希望他们说的下一句话是“……但是这个的复杂度是O(n²),所以我能做得更好吗?”如果不是,我将探究“这个解决方案的运行时间是多少”?大多数情况下,应聘者在得到暗示后会顿悟,然后继续寻找更好的解决方案
将O(n²)调整为O(n)
此时,你需要考虑将要使用什么数据结构,以及如何存储数据。
不太理想的选择是链表或数组。它们需要O(n)次搜索,因此无论你多么努力,最终都会回到O(n²)算法。你可以使用树,但因为搜索是O(log n),所以总的最佳结果是O(n log n)。
更好的候选对象有这样的直觉,即Map将提供O(1)查找,他们需要将O(n²)算法转换为O(n)算法。优秀的候选人会主动指出缺点是你将使用O(n)内存。如果你想更深入地了解它,你甚至可以指出映射有一个隐藏的成本,那就是一遍又一遍地运行哈希函数。总的来说,以牺牲更多内存为代价换取更快的运行时间是值得强调的一个很好的权衡。
如果你使用Map,你的Key是什么,你的Value是什么?我在这里看到了各种各样的答案。有些候选人使用PageId作为Key,并使用CustomerId作为Value,但这不会有帮助。然后候选人将其转换为将CustomerId作为键,将PageId作为映射的值。但这也不是特别好,因为它忽略了一个事实,即每个客户可以有多个页面,而不仅仅是一个。有些候选人有一种直觉,他们需要一个页面集合作为地图的值,但他们会选择一个列表,这让我很难过,因为它忽略了可以有副本的事实。这是一个很好的机会来探索关于列表和集合的数据结构知识,因为候选人会考虑处理重复项。
Map<customerid, set>就可以了。但是你会将这两个文件的内容加载到一个Map中吗?或者有两个映射,每个文件一个?或者你是否可以将文件1的内容加载到映射中,然后处理文件2而不存储它?
优秀的候选人意识到他们可以自己马上选择第三种方法。这样内存更少,算法也更简单。优秀的候选人可以做到这一点,但需要一点提示。
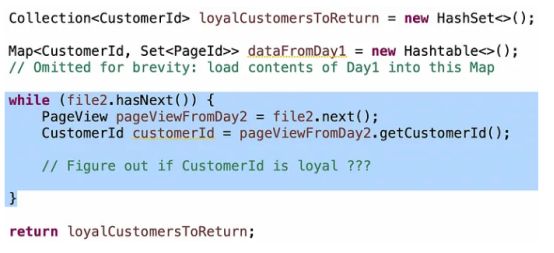
“两天都来的顾客”这个条件非常简单:当你读取来自第2天的顾客条目时,如果顾客出现在第1天的地图中,那么你就知道他们两天都来过:
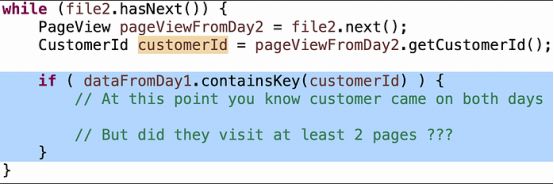
“访问过至少2个独立页面的客户”这个条件对于应聘者来说很难回答对,所以如果他们被卡住了,我就给他们一点提示:你有一组来自第1天的页面,还有一个来自第2天的页面,你怎么能确定这至少是两个独立页面呢?
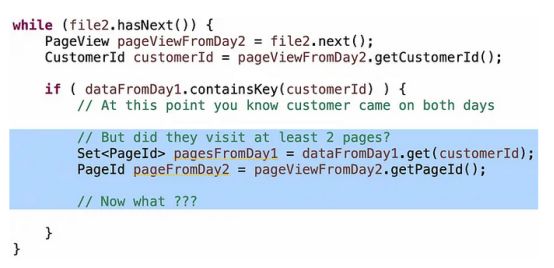
较差的候选人会循环遍历Set中的元素,检查Day2的页面是否在其中。这将使你的O(n)算法再次变为O(n²)。让人惊讶的是,有很多候选人都这样做了。较好的候选人会在Set上执行.contains()操作,这在哈希集合上是一个O(1)的操作。但是,逻辑上仍然存在一个问题。
正确的 intution 如下:如果你在那个 if 循环中,并且客户在 Day1 中访问了至少两个页面,并且在 Day2 中访问了任何一个页面,那么无论他们在 Day2 中访问了哪个页面,他们都是忠诚的。否则,他们在 Day1 中只访问了一个页面,所以问题是:这是一个不同的页面吗?如果是,他们是忠诚的,否则是重复的,你不知道,应该继续进行。
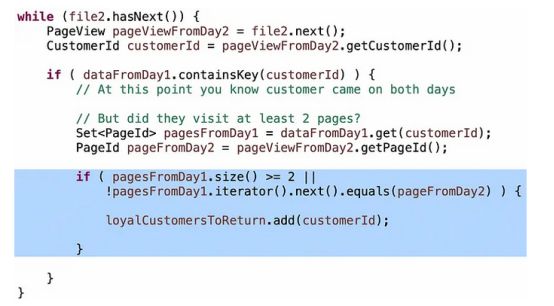
你需要注意细节,比如用“>”代替“>=”,或者少用“!”的句子。我经常看到这些错误。但我不担心。优秀的候选人在完成后会仔细检查算法,很快就能发现这些错误。好的候选人在稍微提示后也能发现这些错误,这对于调试技巧给了我一个好的信号。
优化你的解决方案
如果候选程序达到这一点,并且我们有一些额外的时间,那么探索如何优化速度或内存使用是一种不错的选择,关于这些与未来可维护性之间权衡的一些讨论的加分点。
例如,如果内存是一种约束,你实际上不需要在Map中保留第1天的每个页面,只需保留两个,因为问题是“至少两个页面”,因此大小为2的Set甚至大小为2的数组将比无界Set使用更少的内存。
或者,如果你已经确定了一个客户是忠诚的,那么你就不需要在第二天遇到该客户时再次浪费CPU周期来执行逻辑。
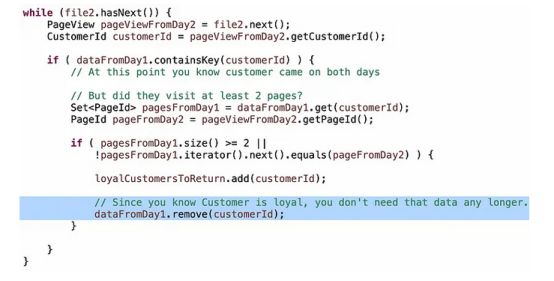
关于优化:你可能会争辩说,如果将来需求发生变化,这些优化会使更改算法变得更加困难,这是一个合理的立场。只要你能很好地讨论利弊,我很乐意就如何平衡这些决定进行高质量的讨论。同时,能够在需要的时候优化算法是一名优秀工程师的特质,在你的职业生涯中,你需要这样做一两次。
另一种解决方案
绝大多数候选人都采用Map方法,但有时也会有候选人采用另一种方法。可能最多5%的时间。
如果对这些文件进行预处理,并先按CustomerId排序,然后按PageId排序,结果会怎样?
预处理是软件工程库中的一个强大工具,特别是当你要多次执行某个操作时。你可以对第一个进行预处理,也可以事先进行预处理,这样可以随着时间的推移分摊成本。在内存不变的情况下,对文件进行排序可能是一个O(n log n)的操作。
如果文件已经排序,那么问题就变得更加简单,只需要使用两个指针的算法即可,在 O(n) 的时间复杂度和 O(1) 的内存复杂度下执行。移动文件1和文件2的指针,直到它们位于相同的CustomerId上,这意味着它们在两天都出现过。由于第二个排序键是按PageId排序的,因此可以使用另一个双指针算法来确定至少有两个不同的页面。因此,这是一个两个指针算法嵌套在另一个两个指针算法中的问题。这是一个有趣的问题!我将把实际实现留给观众作为练习。
总结
我希望这篇从面试官的角度对编程问题的小见解,以及我所看到的优秀、良好和较差的候选人解决问题的方法,会对你有所帮助,祝你在下一次面试中好运!
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Carlos Arguelles
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://carloarg02.medium.com/my-favorite-coding-question-to-give-candidates-17ea4758880c





