
如何用Python处理金融数据?
本文用亚马逊的股票数据(Amazon Stock Data)进行简单的操作实践,用python处理金融数据,为初学者提供完整版指南。
在这篇文章中,我将引导你们完成一些很有意义的操作实践,这些演练将帮助了解如何使用 Python 处理金融数据。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
快收藏!2021 Python常用函数都在这里
如何在Pandas里写SQL查询语句?
如何用Pandas 三步清洗数据?
一文上手用Pandas给数据加标签
首先,我将向你们介绍我们的朋友 Python,然后我们将进入一个非常有趣的部分,即编程(Programming)。正如刚刚提到的,我们将使用亚马逊股票数据(Amazon Stock Data)。如果你想免费获取这些股票数据,可在纳斯达克(NASDAQ)官网获取。纳斯达克—美国证券交易商自动报价系统协会(National Association of Securities Dealers Automated Quotations)是一个电子证券交易所,旗下拥有 3,300 多家公司。
你可以在这里下载亚马逊股票数据。在这个网站上,你可以找到不同公司的股票数据,通过数据集练习你的技能。让我们开始吧!
目录:
- Python
- 了解亚马逊股票数据(Amazon Stock Data)
- 数据清理(Data Cleaning)
- 数据可视化(Data Visualization)
Python
Python 是一种通用编程语言,在分析数据方面变得越来越受欢迎。通过Python,你的工作效率会越来越高,能更加有效地集成系统;世界各地的公司都在用 Python 从数据中收集知识。如果你想了解更多信息,可以访问 Python 官方页面。
了解数据
当你第一次加载数据至数据帧中时,在开始操作之前,你需要查看这些数据。这有助于了解数据是否正确,同时对数据提前有一些了解。如前所述,在本操作实践中,我们将使用来自纳斯达克(NASDAQ)的历史数据。我认为亚马逊会是一个不错的选择。与我一起完成此操作实践后,你将学会一些技能,掌握这些技能之后,你就能够使用不同的数据集进行练习。
我们使用的数据帧包含2020 年 6 月 24 日至 7 月 23 日亚马逊股票的收盘价(Closing Prices)。
读取数据
import pandas as pd
amzn = pd.read_csv('amzn_data.csv')Head函数(Head Method)
为了了解数据,我们首先要使用 Head函数。当你在数据帧上使用 Head函数时,会显示出数据帧的前五行信息。运行此方法后,我们还可以看到,数据是按日期索引排序的。
amzn.head()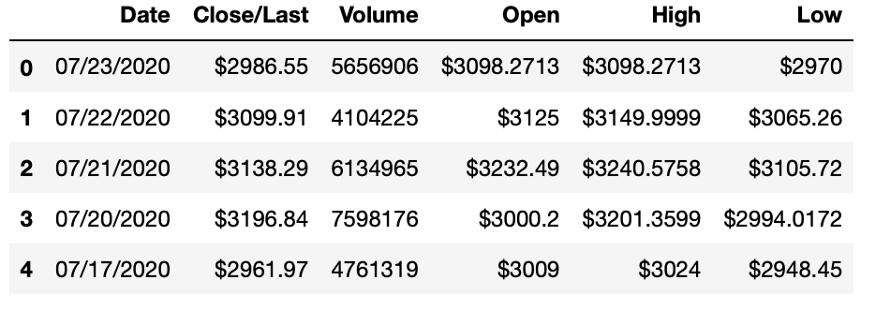
Tail命令(Tail Method)
还有一个方法也非常有用,那就是Tail命令。通过使用Tail命令,可以显示数据帧的最后五行信息。假设你想查看最后三行,你可以在括号之间输入整数值 3 。
amzn.tail()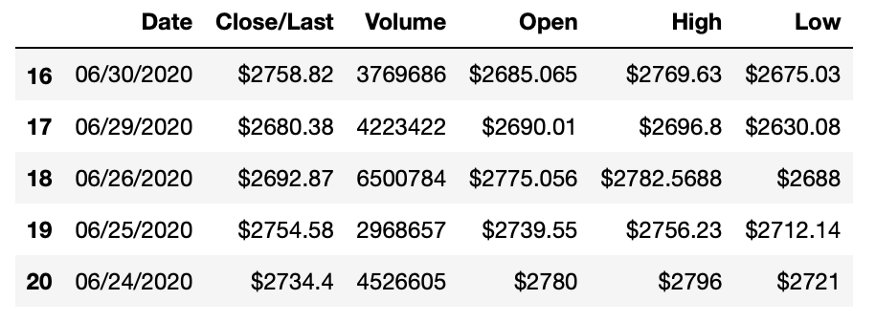
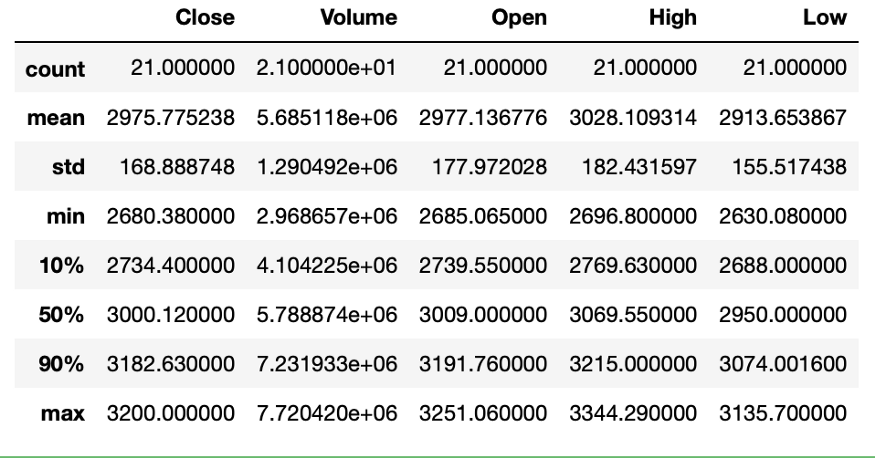
描述函数(Describe Method)
在深入了解数据之前,我们最后用的一个方法是描述函数。描述函数可用于数据统计相关总结。默认情况下,描述函数会返回所有数字列的汇总统计信息,如,在我们的示例中,所有列中的信息都是数字。摘要将包括以下内容:行数、平均值、标准偏差、最小值和最大值,最后是百分位数。
amzn.describe()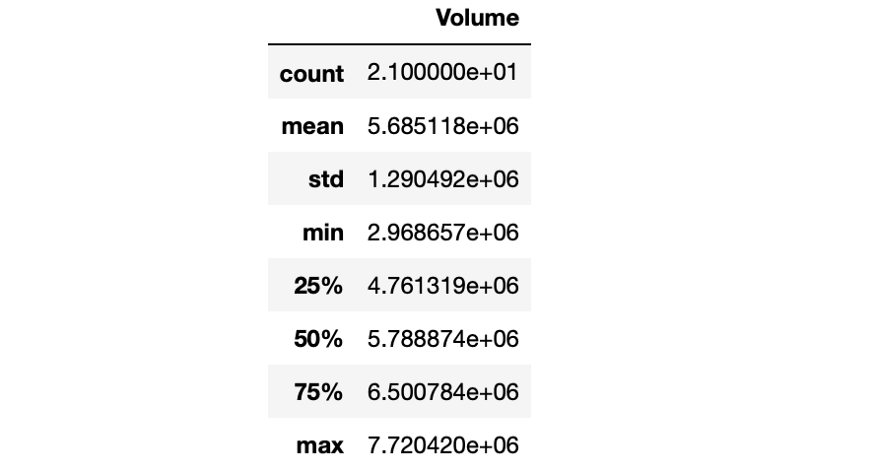
为什么我们只获取了 Volume 列的值而没有其他列?这就是我们所说的数据准备(Data Preparation)。清理数据,准备进行分析,这也是最重要的一步。在进行下一步之前,我们必须了解一些注意事项。
数据清理
我们之前提到过使用描述函数(Describe Method)是专门处理数值的,意味着只有Volume 这列是数值。我们可以查看一下列的数据类型。
amzn.dtypes

如上所示,只有Volume 列是整数类型(Interger Type),其余是对象类型(Object Type)。所以,我们必须注意数据类型。但是在转换数据类型之前,我们需要清除美元符号,否则当程序指令将美元符号转换为数值时,会出现错误。
amzn = amzn.replace({'\$':''}, regex = True) amzn.head()
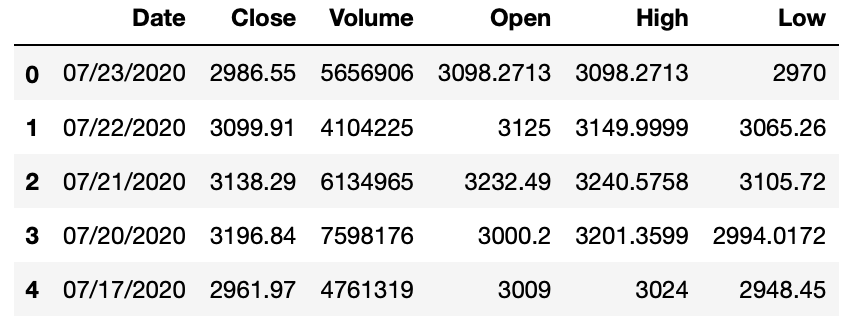
好的,现在我们可以转换数据类型了。我们不需要对 Date 和 Volume 列进行任何更改。我们要将其余列转换为数值,在本练习中,我们可以使用浮点数值类型(Float Numeric Type)。
# Renaming column names and converting the data types
df = amzn
df.columns = ['Date', 'Close', 'Volume', 'Open', 'High', 'Low']
# Converting data types
df = df.astype({"Close": float, "Volume": int, "Open": float, "High": float, "Low": float})
df.dtypes
太好了,我们成功解决了数据类型的问题。现在,我们可以尝试运行描述函数(Describe Method),看看这种方法是如何运作的。
df.describe()
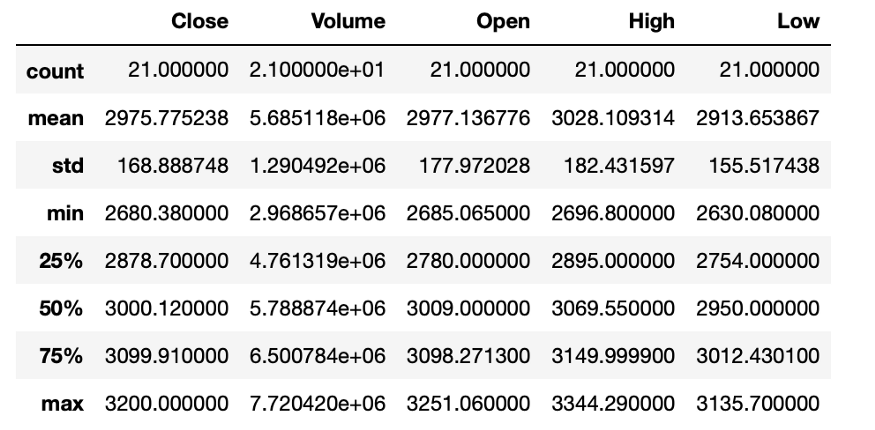
非常棒!现在,正如上图所示,描述函数(Describe Method)与我们所有的数字列配合地非常完美。我们还可以通过使用不同的参数来自定义描述法的结果。我们在此练习中将用到describe的三个参数:include、percentiles 以及 exclude。
df.describe(include = "float")
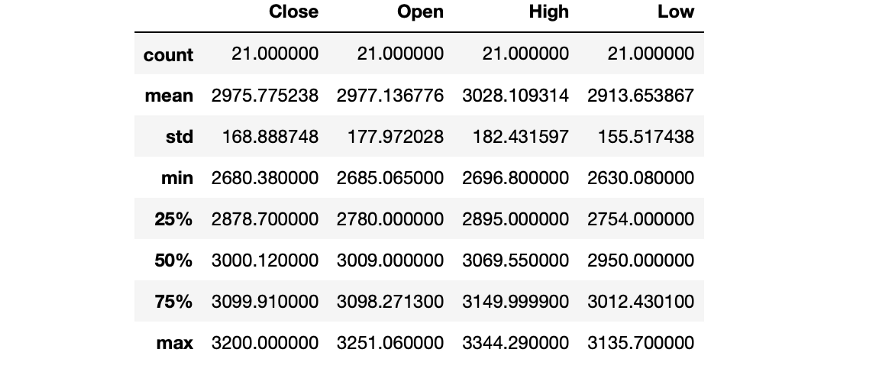
df.describe(include = "object")
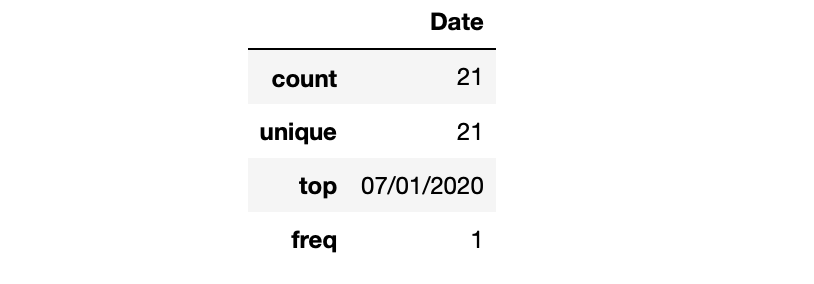
df.describe(exclude = "int")
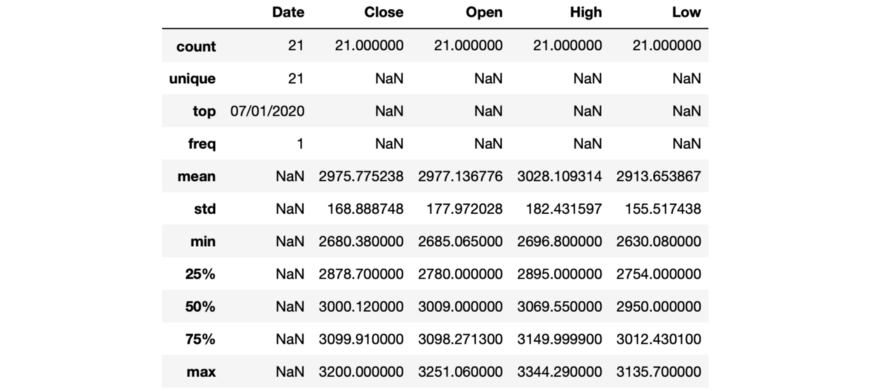
过滤数据
运算符
- <
- >
- <=
- >=
- ==
- !=
我们将使用这些运算符,用来比较特定的值与列中的值。结果将出现一串布尔值(Booleans):也就是True 和 Falses。如果比较是正确的,则为True,如果比较是不正确的,则为False。
通过收盘价过滤
如果我们使用 loc[] 运算符将一串布尔值(Booleans)传递给数据帧时,将返回仅为 True 值的新数据帧。
# Closing price more than 3000
mask_closeprice = df.Close > 3000
high_price = df.loc[mask_closeprice]
high_price.head()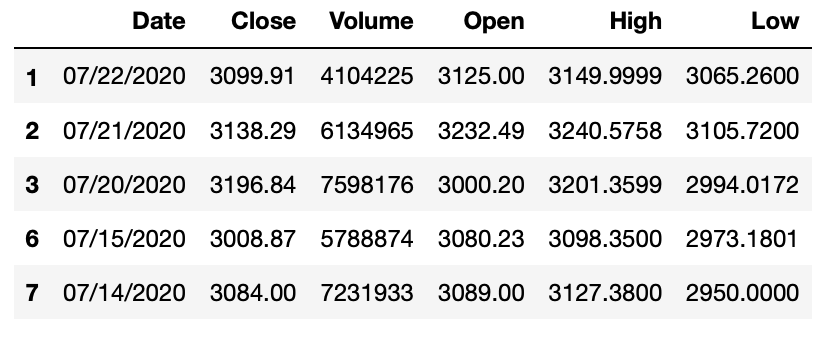
Pandas 通过运算符将布尔值(Booleans)的不同比较结果组合在一起。这些运算符是:And、Or、Not。我们可以使用这些运算符来创建更复杂的条件。例如,假设我们想看到AMZN股票数据收盘价(Closing Price)超过3000,同时成交量超过500万。我们可以通过以下擦做实现:
# Closing price more than 3000 and traded volume more than 5
mask_closeprice = df.Close > 3000
mask_volume = df.Volume > 5000000
millionhigh_price_volume = df.loc[mask_closeprice & mask_volume]
high_price_volume.head()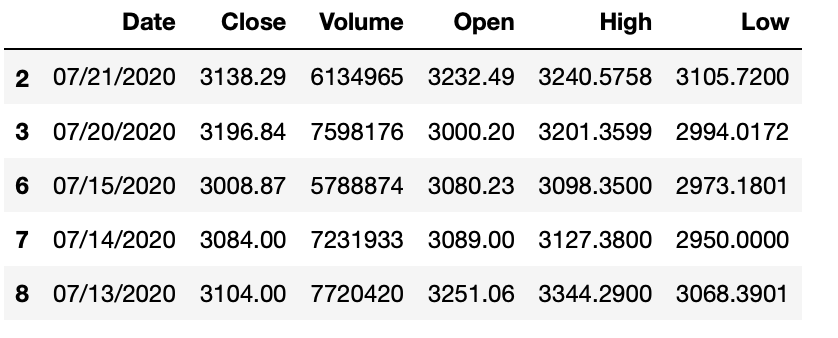
数据可视化(Data Visualization)
数据可视化是理解数据的重要步骤。它不仅可以帮助我们看到多行值,还可以让我们更好地了解数据。我们还可以通过数据可视化比较不同的数据值。
数据可视化还非常适合了解和查看不同列之间的关系。
Matplotlib
最常用的二维(2D)绘图库就是 Matplotlib。这个库非常强大,有它的学习曲线。通过Matplotlib的学习曲线,其他库也构建在这基础之上。
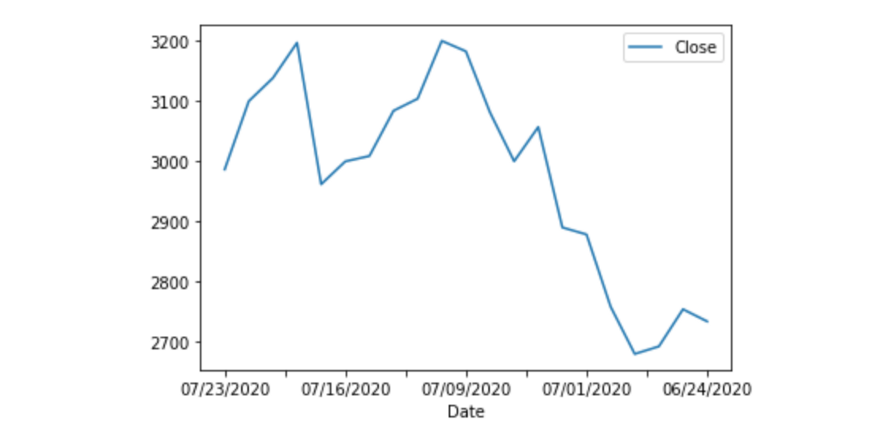
下面,我们来绘制这个月的股票价格。x 轴是日期,y 轴将是每天的收盘价。绘制出的线图将显示股票价格在一个月内的变化情况。从业务角度来说,这条线图叫做价格波动图,可以用于检测股票价格的季节性模式。
df.plot(x='Date', y='Close')
旋转(Rotate)
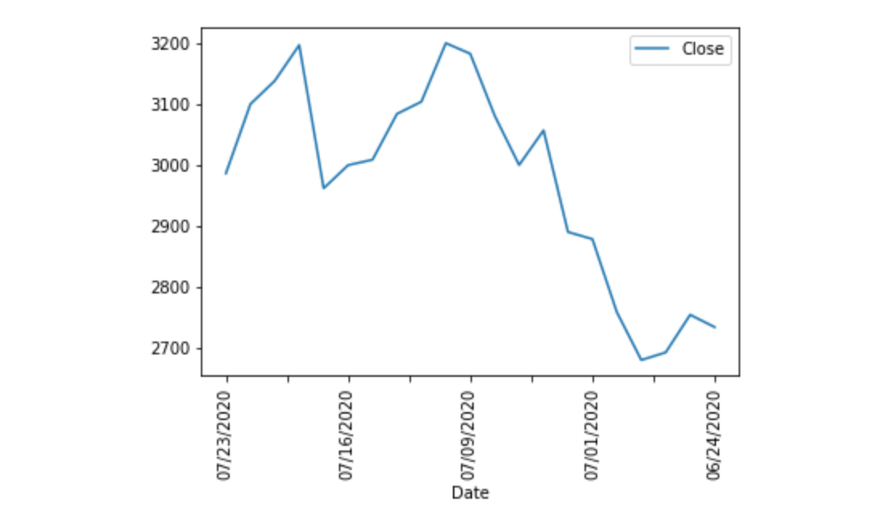
Matplotib提供了许多有趣的参数,你可以自己尝试一下。其中之一就是旋转,可用于旋转图表的标签。下面这个例子中我们将日期标签旋转 90 度,以便于阅读。
df.plot(x='Date', y='Close', rot=90)
标题(Title)
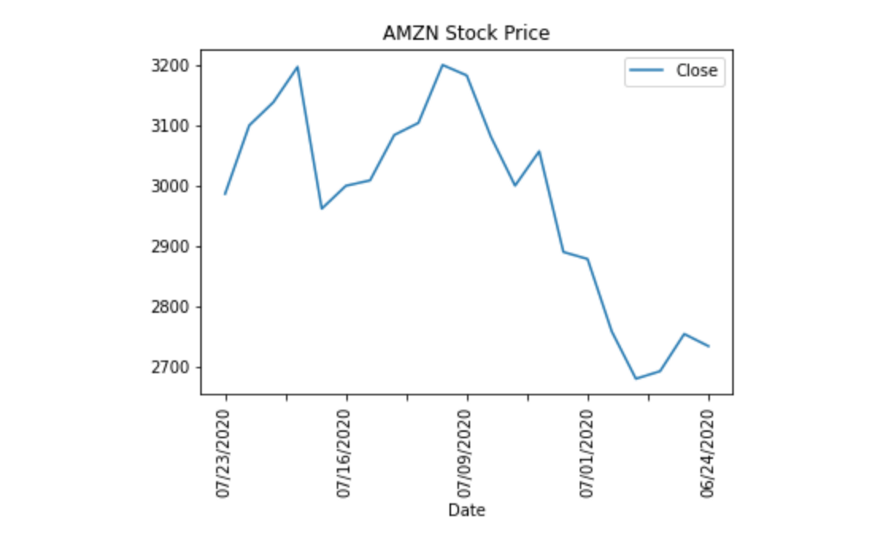
如果你想给你的图表一个标题,可以使用下列这种方法,将字符串传递给title 参数。
df.plot(x='Date', y='Close', rot=90, title="AMZN Stock Price")
更多的图表类型
默认图表类型为线图(Line Plot),但在我们的例子中,还有许多其他图表类型可供使用,包括:
- 线图(Line Plot)
- 柱状图(Bar Plot)
- 饼状图(Pie Plot)
- 散点图(Scatter Plot)
- 直方图(Histogram)
现在,我们以散点图(Scatter Plot)为例。我们可以在名为 kind 的方法中添加一个新参数。对的,就是这么简单。
df.plot(x='Date', y='Close', kind='scatter', rot=90, title="AMZN Stock Price")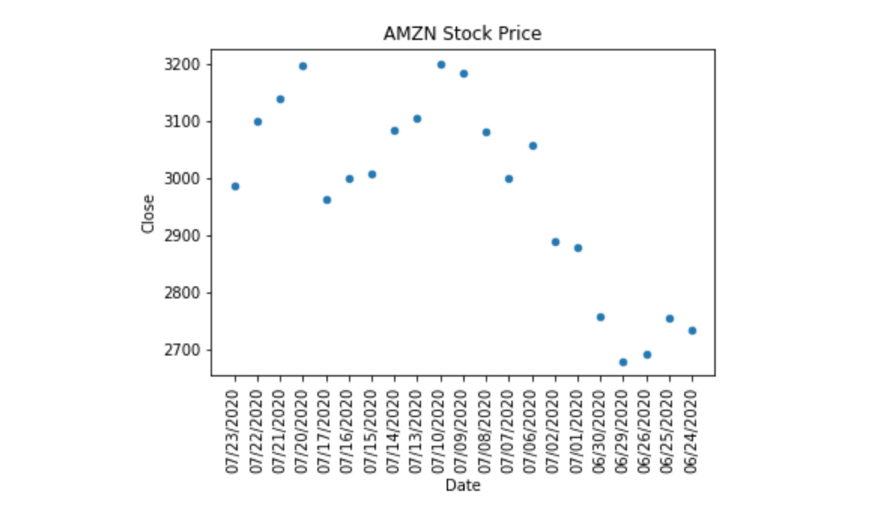
现在,我们再以直方图(Histogram)为例。直方图非常适合用来查看值分布。
df.plot(x='Date', y='Volume', kind='hist', rot=90, title="AMZN Stock Price")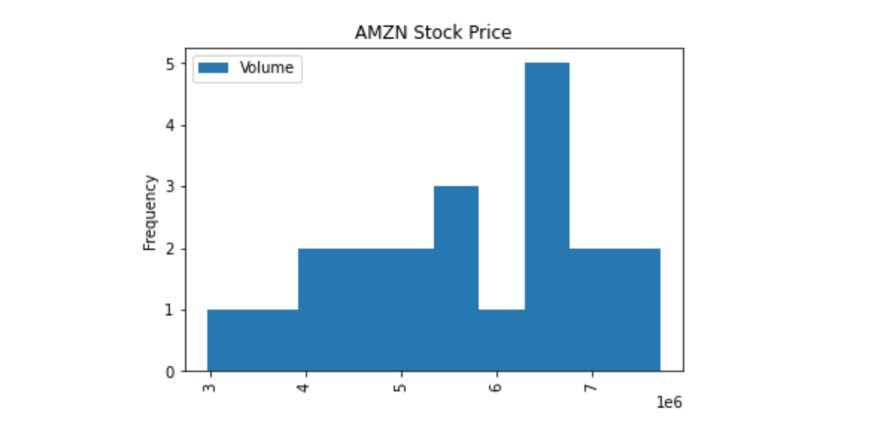
以上就是本文的全部内容。感谢你阅读这篇文章,希望你喜欢这篇文章并学到一些新的东西。如果你在运行代码时有任何问题,欢迎在评论区讨论留言。感谢阅读!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Behic Guven
翻译作者:Lia
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/python-for-finance-the-complete-beginners-guide-764276d74cef




