")
如何在本地运行大语言模型,保护数据隐私(下)
(接上一篇)
硬件和软件设置
我们使用了一个具有以下功能的相当不错的服务器:
- CPU:AMD Ryzen Threadripper PRO 7965WX 24核@ 48x 5.362GHz
- GPU:2倍NVIDIA GeForce RTX 4090。
- 内存:515276 mib –
- 操作系统:Pop 22.04 jammy。
- 内核:x86_64 Linux 6.9.3-76060903-generic。
这个装置的零售成本大约是15000美元。我们之所以选择这样的设置,是因为它是一个不错的服务器,虽然远不如拥有8个或更多gpu的专用高端AI服务器强大,但仍然具有相当的功能和代表性,我们的许多客户可能会选择它。我们发现许多客户对投资高端服务器犹豫不决,这种设置是成本和性能之间的一个很好的折衷。
速度
让我们首先关注速度。下面,我们给出了几个盒须图,描绘了几个量化的速度数据。每个模型的名称以其量化级别开头;例如,“Q4”表示4位量化。同样,较低的量化水平轮询更多,减小了尺寸和质量,但提高了速度。
►技术问题1(关于盒须图的提示):盒须图显示中位数、第一和第三四分位数以及最小和最大数据点。须延伸到不被归类为异常点的最极端点,而异常点是单独绘制的。异常值被定义为落在Q1−1.5 × IQR和Q3 + 1.5 × IQR范围之外的数据点,其中Q1和Q3分别代表第一和第三个四分位数。四分位间距(IQR)计算公式为:IQR = Q3−Q1。
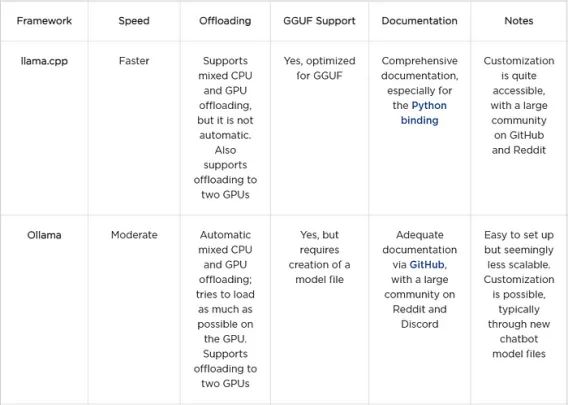
llama.cpp
下面是llama.cpp的图表。图3显示了QuantFactory中可用的70B参数的所有Llama 3.1模型的结果,图4显示了此处可用的8B参数的部分模型。70B型号最多可以卸载81层到GPU上,而8B型号最多可以卸载33层。对于70B,卸载所有层对于Q5量化和更精细是不可行的。每个量化类型包括在括号中卸载到GPU上的层数。正如预期的那样,更粗的量化产生最佳的速度性能。由于行分割模式的执行类似,我们在这里主要讨论层分割模式。
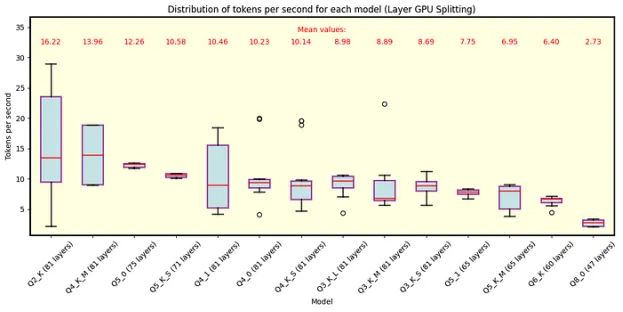
图3具有70B参数的Llama 3.1模型在分模层的Llama.cpp下运行。正如预期的那样,更粗的量化提供了最好的速度。卸载到GPU上的层数在每个量化类型旁边的括号中显示。具有Q5和更精细量化的模型不完全适合VRAM。
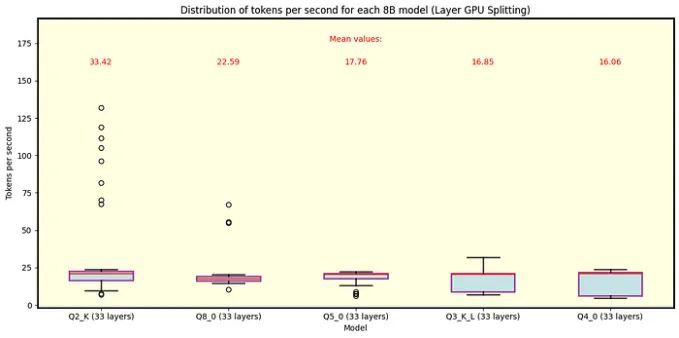
图4 8B参数的Llama 3.1模型在Llama .cpp下使用分模层运行。在这种情况下,该模型适用于所有量化类型的GPU内存,较粗的量化导致最快的速度。请注意,高速是异常值,而Q2_K的总体趋势徘徊在每秒20个令牌左右。
主要观察
在推理过程中,我们观察到一些高速事件(特别是在8B Q2_K中),这是收集数据并理解其分布至关重要的地方,因为事实证明这些事件非常罕见。
正如预期的那样,较粗的量化类型产生最佳的速度性能。这是因为模型大小减小了,允许更快的执行。
有关70B模型不能完全适合VRAM的结果必须谨慎对待,因为使用CPU也可能导致瓶颈。因此,在这些情况下,报告的速度可能不是模型性能的最佳表示。
Ollama
我们对Ollama做了同样的分析。图5显示了Ollama自动下载的默认Llama 3.1和3.2模型的结果。除了405B型号外,它们都适合GPU内存。
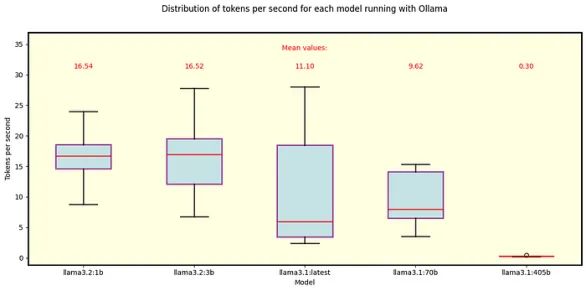
图5 在Ollama下运行的Llama 3.1和3.2模型。这些是使用Ollama时的默认模型。所有3.1模型-特别是405B, 70B和8B(标记为“最新”)-使用Q4_0量化,而3.2模型使用Q8_0 (1B)和Q4_K_M (3B)。
主要观察
我们可以将70B Q4_0模型与Ollama和llama.cpp进行比较,其中Ollama的速度略慢。
同样,8B Q4_0模型在Ollama下比其对应的llama.cpp要慢,而且有一个更明显的区别——llama.cpp平均每秒多处理5个令牌。
分析框架总结
在讨论功耗和可租用性之前,让我们总结一下到目前为止我们分析的框架。
电力消耗和可租赁性
这个分析特别适用于将所有层都放入GPU内存的模型,因为我们只测量了两个RTX 4090卡的功耗。尽管如此,值得注意的是,这些测试中使用的CPU的TDP为350 W,这提供了最大负载下的功耗估计。如果将整个模型加载到GPU上,CPU可能会保持接近空闲水平的功耗。
为了估计每个令牌的能耗,我们使用以下参数:每秒令牌数(NT)和两个gpu消耗的功率(P),以瓦为单位。通过计算P/NT,我们得到每个令牌的能耗,单位是瓦秒。将其除以3600得到每个令牌的能源使用量,单位是Wh,这是更常用的参考。
llama.cpp
以下是llama.cpp的结果。图6为70B型号的能耗图,图7为8B型号的能耗图。这些图显示了每种量化类型的能耗数据,其平均值显示在图例中。
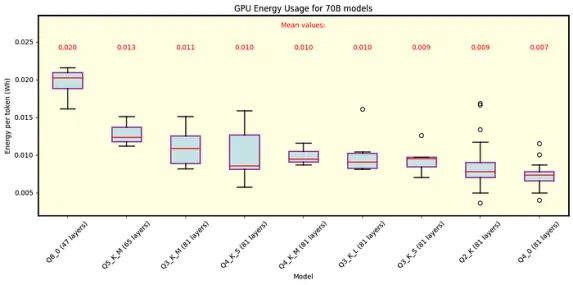
图6 Llama.cpp下,70B参数的Llama 3.1模型各量化的每令牌能量。显示了行分割模式和层分割模式。结果仅适用于适合GPU内存中所有81层的模型。
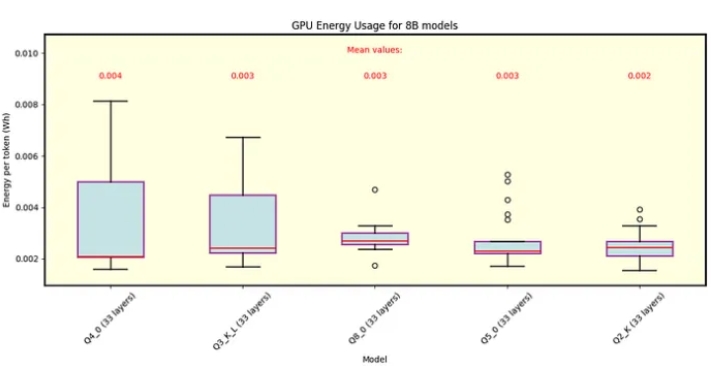
图7 Llama .cpp下,8B参数下Llama 3.1模型各量化的每令牌能量。显示了行分割模式和层分割模式。所有型号的平均消耗量都差不多。
Ollama
我们还分析了Ollama的能源消耗。图8为Llama 3.1 8B (Q4_0量化)和Llama 3.2 1B和3B(分别为Q8_0和Q4_K_M量化)的结果。图9显示了70B和405B型号的单独能耗,均采用Q4_0量化。
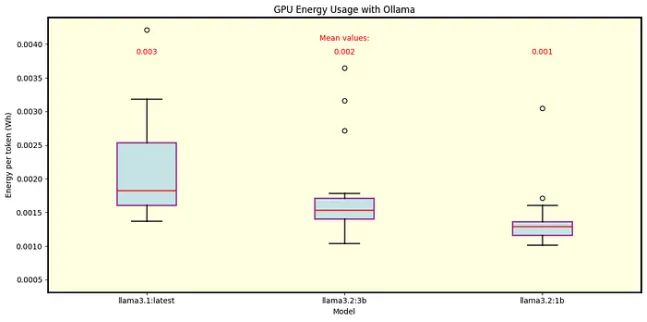
图8 Ollama下Llama 3.1 8B (Q4_0量化)和Llama 3.2 1B和3B模型(Q8_0和Q4_K_M量化)的每令牌能量。
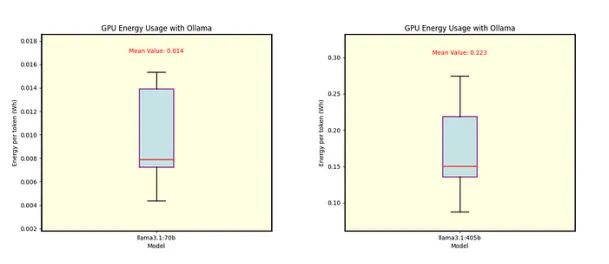
图9 Llama 3.1 70B(左)和Llama 3.1 405B(右)的每个令牌能量,均在Ollama下使用Q4_0量化。
成本
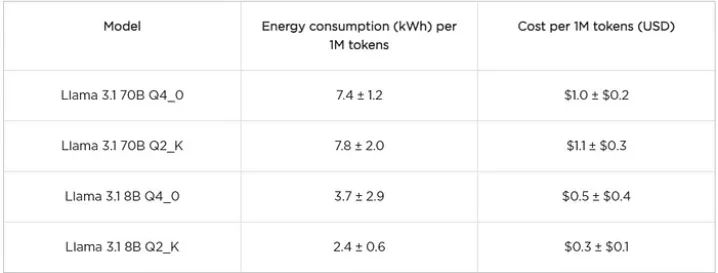
我们不会单独讨论每个模型,而是将重点放在跨llama.cpp和Ollama的可比较模型上,以及在llama.cpp下使用Q2_K量化的模型上,因为它是这里探讨的最粗糙的量化。为了更好地了解成本,我们在下表中显示了每100万个生成的令牌(1M)的能源消耗和以美元计算的成本的估计。该成本是根据德克萨斯州的平均电价计算的,根据该消息来源,每千瓦时0.14美元。作为参考,目前gpt – 40的定价至少为每百万代币5美元,而GPT-o mini的定价为每百万代币0.3美元。
llama.cpp
Ollama

主要观察
使用Q4_0的Llama 3.1 70B模型,Llama .cpp和Ollama的能耗没有太大差异。
对于8B型骆驼来说,cpp比Ollama消耗更多的能量。
考虑一下,这里所描述的成本可以看作是运行模型的“裸成本”的下限。其他成本,如操作、维护、设备成本和利润,不包括在这一分析中。
估计表明,与云服务相比,在私有服务器上运行llm具有成本效益。特别是,在适当的情况下,将美洲驼8B与GPT-45o mini进行比较,将美洲驼70B与gpt – 40进行比较似乎是一笔潜在的好交易。
►技术问题2(成本估计):对于大多数模型,每1M代币的能源消耗(及其可变性)的估计是由“中位数±IQR”处方给出的,其中IQR代表四分位数范围。只有在Llama 3.1 8B Q4_0模型中,我们使用“mean±STD”方法,其中STD表示标准差。这些选择不是武断的;除了Llama 3.1 8B Q4_0之外的所有模型都显示出异常值,这使得中位数和IQR在这些情况下更加稳健。此外,这些选择有助于防止成本出现负值。在大多数情况下,当两种方法产生相同的集中趋势时,它们提供了非常相似的结果。
结论

对不同模型和工具的速度和功耗的分析只是整体情况的一部分。我们观察到,轻量化或高度量化的模型通常在可靠性方面表现出一定的局限性。随着聊天记录的增加或任务的重复,出现幻觉的频率也随之上升。这并不意外——较小的模型难以捕捉较大模型的广泛复杂性。为缓解这些限制,可以通过重复惩罚和温度调节等设置来改善输出质量。
另一方面,像70B这样的大模型始终展现出强大的性能,几乎不会产生幻觉。然而,由于即便是最强大的模型也可能出现不准确的情况,负责任且可靠的使用通常需要将这些模型与其他工具集成,比如LangChain和矢量数据库。尽管我们在此并未深入探讨具体任务的性能表现,但这些集成对于最小化幻觉并增强模型的可靠性至关重要。
综上所述,在私有服务器上运行大型语言模型(LLM)作为一种服务,能够提供具备竞争力的LLM替代方案,同时兼具成本优势和定制化的可能性。无论是私有部署还是基于服务的选项,各有其独特优势。在Austin AI,我们专注于提供满足客户需求的解决方案,无论这意味着利用私有服务器、云服务,还是采用混合方案。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Robert Corwin
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://towardsdatascience.com/running-large-language-models-privately-a-comparison-of-frameworks-models-and-costs-ac33cfe3a462





