
连接数据与AI系统的关键点:LLM管道的设计与实现
数据和人工智能系统一团糟,这些系统复杂而难以理解。
无论你是刚刚开始从事人工智能工作,还是已经在该领域工作了几年,要弄清数据工程、研究(如DS、ML)和生产(如AIE、MLE、MLOps)如何整合成一个同质化的系统,都是一件相当困难的事。
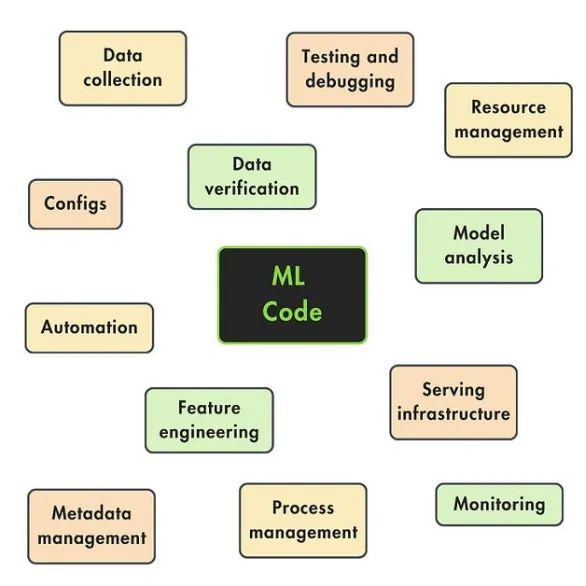
- 作为一名数据工程师,你的工作是将标准化数据摄取到数据仓库或数据湖中。
- 作为研究人员,当你在静态数据集上训练出最佳模型并将其推送到模型注册表时,任务就算完成了。
- 作为AIE或MLE工程师,在成功将模型部署到生产环境后,你的工作就完成了。
- 作为MLOps工程师,当操作流程实现了自动化并具备充分的监控以确保长期稳健性时,你的任务也告一段落。
然而,是否有一种更易理解、更直观的方式,来系统化理解整个端到端的数据与人工智能系统?
答案是:有的!那就是FTI架构。
接下来,我们将快速深入探讨FTI架构,并展示如何将其应用于生产级LLM & RAG(Retrieval-Augmented Generation)用例。如果你想了解更多关于LLM的相关内容,可以阅读以下这些文章:
大语言模型:AI如何改变医疗现状
为什么大语言模型不适合编码?
AI驱动的财务分析:多代理LLM系统将数据转化为见解
2024年打造生产级LLM应用的最佳技术栈
介绍FTI架构
FTI架构提出了一个清晰直接的思维导图,任何团队或个人都可以遵循它,来完成特征计算、模型训练以及推理管道的部署。
该模式表明,任何机器学习系统都可以归结为三个管道:特征(Feature)、训练(Training)和推理(Inference)。
这种架构强大之处在于,我们可以清晰地定义每个管道的职责和接口。最终,系统只有三个核心模块,而不是图1中展示的那种拥有二十个模块的复杂结构。这大大简化了操作和定义的难度。
图2展示了特征、训练和推理管道。我们将逐步放大每一个管道,来更深入了解它们的作用范围和接口。
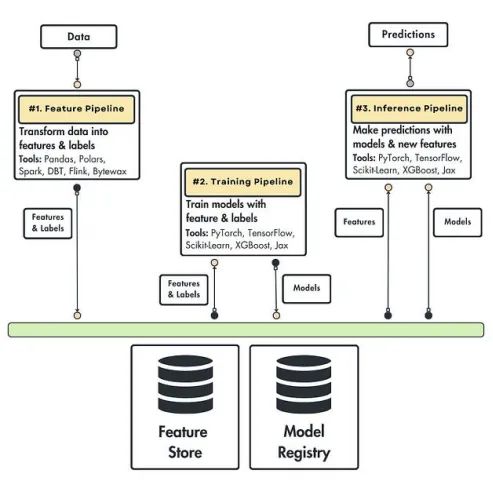
在进入细节之前,我想指出每个管道都是一个独立的组件,可以在不同的进程或硬件上运行。因此,每个管道可以由不同的团队使用不同的技术编写,或者以不同的方式扩展。
特征管道
特征管道将原始数据作为输入,对其进行处理,输出模型训练或推理所需的特征和标签。
这些特征和标签不是直接传递给模型的,而是存储在特征库中。特征库的职责包括存储、版本管理、追踪和共享这些特征。
通过将特征保存到特征库中,我们始终保有特征的状态。因此,我们可以轻松将这些特征发送到训练和推理管道中使用。
训练管道
训练管道从特征库中获取特征和标签作为输入,并输出训练好的模型。
模型被存储在模型注册表中。它的功能类似于特征库,但这次的主体是模型。因此,模型注册表将负责存储、版本管理、追踪模型,并与推理管道共享这些模型。
推理管道
推理管道以特征库中的特征和标签,以及模型注册表中的训练模型为输入。基于这两者,系统可以轻松进行批量或实时预测。
由于这是一个多用途模式,你可以自由选择如何处理预测结果。如果是批处理系统,预测结果可能会存储在数据库中;如果是实时系统,预测结果则会直接返回给请求的客户端。
关于FTI架构管道,你必须记住的最重要的一点是它们的接口设计。无论你的机器学习系统变得多么复杂,这些接口都会保持不变。
将FTI架构应用于用例
FTI架构是工具无关的。为了更好地理解其工作原理,让我们展示一个具体的用例和技术栈。
用例:在你的社交媒体数据(如LinkedIn, Medium, GitHub)上微调LLM,并将其作为实时RAG应用程序公开。我们称其为“LLM Twin”。
我们将系统分为四个核心部分。
可能你会问:“为什么是四个,而不是FTI架构所定义的三个管道?”这确实是一个好问题。
幸运的是,答案很简单:我们还需要沿着特征/训练/推理三条管道实现一个数据管道。根据最佳实践:
- 数据工程团队负责数据管道。
- 机器学习工程团队负责FTI管道。
图3展示了LLM系统的高级架构。为了便于理解,我们将分别回顾这四个组件,并解释它们的工作原理。
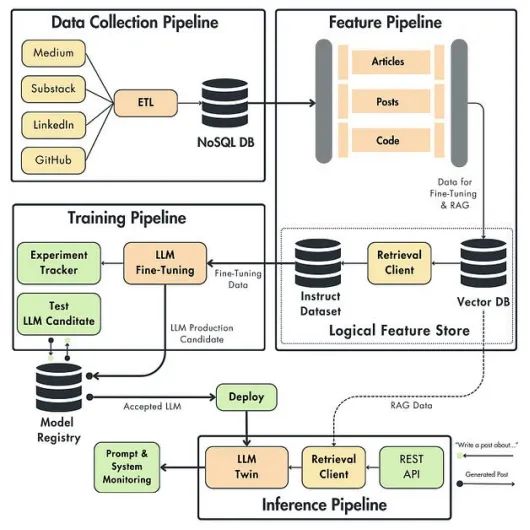
数据收集管道
数据收集管道包括从Medium、Substack、LinkedIn和GitHub抓取你的个人数据。
我们将采用ETL(Extract, Transform, Load)模式,从社交媒体平台提取数据,对其进行标准化处理,并加载到数据仓库中。
输出将是一个NoSQL数据库,作为我们的数据仓库。由于自然语言文本数据通常是非结构化的,因此NoSQL数据库非常适合此类存储需求。
尽管像MongoDB这样的NoSQL数据库没有被标记为数据仓库,但从我们的角度来看,它将充当一个数据仓库。为什么?因为它存储了由各种ETL管道收集的标准化原始数据,这些数据准备被吸收到ML系统中。
收集到的数字数据分为三类:
- 文章(Medium, Substack,其他博客)
- 帖子(LinkedIn)
- 代码(GitHub)
我们想要抽象出抓取数据的平台。例如,当向LLM提交一篇文章时,知道它来自Medium或Substack并不是必要的。我们可以保留源URL作为元数据来提供引用。
然而,从处理、微调和RAG的角度来看,了解我们摄取的数据类型是至关重要的,因为每个类别必须以不同的方式处理。例如,一篇文章、一篇文章和一段代码之间的分块策略看起来会有所不同。
特征管道
特征管道的职责是从数据仓库中获取原始文章、帖子和代码数据,对其进行处理,并将处理后的数据存储到特征库中,以供后续的训练和推理管道使用。
LLM Twin特性管道的自定义属性
它以不同的方式处理三种数据类型:文章、帖子和代码。
它包含三个主要的微调和RAG处理步骤:清洗、分块和嵌入。
它创建两个数字数据快照,一个在清洗之后(用于微调),另一个在嵌入之后(用于RAG)。
它使用逻辑特性存储,而不是专门的特性存储。
让我们稍微放大一下逻辑特性存储部分。与任何基于RAG的系统一样,基础设施的中心部分之一是矢量数据库。我们并没有集成另一个数据库,尤其是专门的特性存储,而是使用了向量数据库,并且加了一些额外的逻辑来检查系统所需特性存储的所有属性。
矢量数据库不提供训练数据集的概念,但它可以作为NoSQL数据库来使用。这意味着我们可以使用它们的ID和集合名称来访问数据点。
因此,我们可以很容易地查询向量数据库中的新数据点,而不需要任何向量搜索逻辑。最后,我们将检索到的数据包装成版本化、可追踪且可共享的工件。
系统的其余部分如何访问逻辑特性存储呢?训练管道将使用指令数据集作为工件,而推理管道将使用向量搜索技术查询向量数据库以获取额外的上下文。
对于我们的用例,这已经足够了,原因如下:
- 工件非常适合离线用例,例如训练。
- 向量数据库是为在线访问而构建的,而我们需要在线访问来进行推理。
总而言之,我们输入原始文章、帖子或代码数据点,处理它们,并将它们存储在特性存储中,以便训练和推理管道可以访问它们。
请注意,去掉所有的复杂性,只关注界面,这完全符合FTI模式。
训练管道
训练管道从特性存储中获取指令数据集,用它对LLM进行微调,并将调整后的LLM权重存储在模型注册表中。
更具体地说,当一个新的指令数据集在逻辑特性存储中可用时,我们将触发训练管道,使用工件,并对LLM进行微调。
在初始阶段,数据科学团队负责这一步。他们运行多个实验,通过自动或手动的超参数调优,为该任务找到最佳模型和超参数。
为了比较和选择最好的超参数集,我们将使用一个实验跟踪器来记录所有有价值的信息,并在实验之间进行比较。最终,他们将选择最佳的超参数和微调LLM,并将其作为LLM生产候选。然后,将建议的LLM存储在模型注册表中。
在实验阶段之后,我们存储并重用找到的最佳超参数,以消除流程中的手动限制。现在,我们可以完全自动化训练过程,称为连续训练(CT)。
触发测试管道是为了进行比微调期间更详细的分析。在将新模型推向生产环境之前,要根据一组更严格的测试对其进行评估,以确保最新的候选模型比当前的生产环境更好。如果这一步通过,模型最终被标记为可接受,并部署到生产推理管道中。
即使在完全自动化的机器学习系统中,也建议在接受新的生产模型之前进行手动步骤。这就像在有重大后果的行动之前按下红色按钮。因此,在这个阶段,专家将查看由测试组件生成的报告。如果一切看起来都很好,模型就会被批准,然后自动化可以继续。
我们想要澄清的最后一个方面是连续训练(CT)。
我们的模块化设计使我们能够快速利用像ZenML这样的ML编排器来调度和触发不同的系统部件。
例如,我们可以安排数据收集管道每周抓取数据。然后,当数据仓库中有新数据可用时,我们可以触发特性管道;当有新的指令数据集可用时,我们可以触发训练管道……然后,我们就有了CT!
推理管道
推理管道是拼图的最后一块。
它连接到模型注册中心和逻辑特性存储。它从模型注册中心加载微调的LLM,并从逻辑特性存储访问RAG的向量数据库。
它通过REST API接收客户端请求作为查询。使用经过微调的LLM和对向量数据库的访问,它执行RAG并回答查询。
所有客户端查询、使用RAG的丰富提示和生成的答案都会发送到提示监视系统,以便进行分析、调试并更好地理解系统。监控系统可以根据具体需求触发告警,并采取手动或自动的行动。
在接口层,该组件完全遵循FTI架构,但当放大时,我们可以观察到LLM和RAG系统的独特特征,例如:
- 检索客户端用于对RAG进行矢量搜索。
- 提示模板将用户查询和外部信息映射到LLM输入。
- 用于快速监控的专用工具。
总结
FTI架构是一个强大的思维导图,可以帮助你连接复杂数据和人工智能世界中的点,如LLM Twin用例所示。
感谢阅读!你还可以订阅我们的YouTube频道,观看大量大数据行业相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/。
原文作者:Paul Iusztin
翻译作者:过儿
美工编辑:过儿
校对审稿:Jason
原文链接:https://medium.com/decodingml/connecting-the-dots-in-data-and-ai-systems-70e91065682a





