
Standardization vs Normalization——数据人老说的“标准化”与“归一化”是什么?
通常,我们数据中的输入特征可以有不同的测量单位。因此,每个特征都可以有自己独特的数值分布方式。但是,合并分布不同的特征可能会导致模型错误地偏向有较大值和较大方差的特征。
特征缩放(Feature scaling)就是通过将所有数据拟合到特定比例来解决这个问题,这就是为什么它通常是特征工程中的必要组件的原因。
而两种最常见的特征缩放方法,就是标准化(standardization)和归一化(normalization)。
在本文中,我们将探索这两种方法的原理,并深入探讨如何确定机器学习任务的最佳缩放方法。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
Data Scientist生产力进阶—Python OOP编程快速入门
通过案例数据集,带你了解Python数据分析和数据可视化
2022年数据工程就业市场:对1000个FAANG职位信息进行分析
数据工程师都做哪些工作?带你了解我的一天
标准化(Standardization)
标准化需要缩放数据,以适应标准的正态分布。
标准正态分布(standard normal distribution)定义是一个均值为 0,标准差为 1 的分布。
将标准化可视化
为了更好地理解标准化,可以用可视化的方法来展示它对数据的影响。
我们将对 1 到 1000 范围内的 1000 个随机值进行标准化。之后,缩放前后的数据分布将以直方图的形式显示。
import numpy as np
import matplotlib.pyplot as plt
from sklearn.preprocessing import StandardScaler
import random
# set seed
random.seed(42)
# thousand random numbers
num = [[random.randint(0,1000)] for _ in range(1000)]
# standardize values
ss = StandardScaler()
num_ss = ss.fit_transform(num)
# plot histograms
fig, ax = plt.subplots(nrows=1, ncols=2, figsize=(10,5))
ax[0].hist(list(np.concatenate(num).flat), ec='black')
ax[0].set_xlabel('Value')
ax[0].set_ylabel('Frequency')
ax[0].set_title('Before Standardization')
ax[1].hist(list(np.concatenate(num_ss).flat), ec='black')
ax[1].set_xlabel('Value')
ax[1].set_ylabel('Frequency')
ax[1].set_title('After Standardization')
plt.show()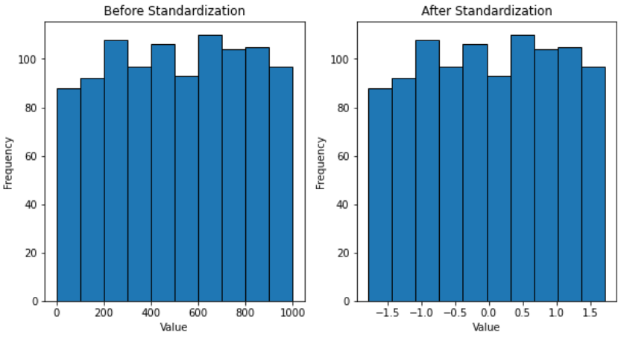
从直方图中,我们可以看到标准化是如何使数据符合标准正态分布的。缩放后的数据均值为 0,标准差为 1。
然而,即使值的本身发生了相当大的变化,分布的形状在变换后仍保持相对完整。这也是缩放的关键,因为我们必须保留存储在特征中的信息。
数学原理
那么,这些新值究竟是如何产生的呢?
用于得出标准化值的公式如下:
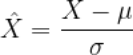
用外行的话来说,标准化就是用数据的平均值和标准差来转换数值。
为了看看这个公式是如何实现的,让我们在一个例子中使用它。
假设我们正在处理以下数据:
训练集:[1、4、5、11]
测试集:[7]
在这种情况下,平均值为 5.25,标准差为 3.63。请记住,我们在确定参数时不用考虑测试集。
了解所有必要信息后,我们可以通过简单的即插即用(plug-and-chug)来标准化原始值。
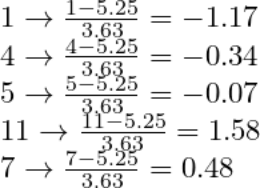
为了验证这些结果,我们可以在 Python 中执行相同的操作。
# training and testing data
train = [[1],[4],[5],[11]]
test = [[7]]
# scaling training and testing data with standardization
ss = StandardScaler()
train_mms = ss.fit_transform(train)
test_mms = ss.transform(test)
# showing change in values
print('Training Data:')
for i in range(len(train)):
print(f'{train[i][0]} -> {round(train_mms[i][0], 2)}')
print(f'\nTesting Data:\n{test[0][0]} -> {round(test_mms[0][0], 2)}')
归一化(Normalization)
归一化需要缩放数据,以适应特定的范围。
虽然这个范围可以由你选择,但通常情况下,归一化会把数据拟合到 0 和 1 的范围内。
将归一化可视化
同样,可视化有助于我们深入了解归一化对数据的影响。
我们可以对相同的 1000 个随机数进行归一化,并用直方图查看它们在缩放后的变化情况。
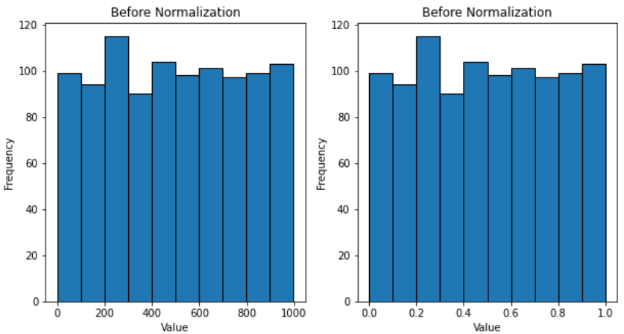
如上图所示,分布发生了变化和缩小,所有值都在 0 和 1 之间。
与标准化类似,标准化不会过多地改变分布的形状,因为它的目的之一是保存信息。
数学原理
归一化遵循了一个简单的公式:
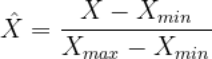
这公式的意思是,归一化根据分布中的最小值和最大值转换值。
我们可以通过对相同的虚拟数据进行归一化来重复前面的练习:
训练集:[1、4、5、11]
测试集:[7]
在这种情况下,最小值为 1,最大值为 11。
重复一下,在推导这些参数时我们不考虑测试集。这也意味着,即使测试集的值小于 1 或大于 11,公式中的最小值和最大值仍将分别为 1 和 11。
有了这些信息,归一化值很容易推导出来:
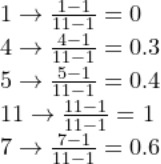
我们可以通过在 Python 中执行相同的操作来验证这些结果。
# training and testing data
train = [[1],[4],[5],[11]]
test = [[7]]
# scale data with normalization
mms = MinMaxScaler()
train_mms = mms.fit_transform(train)
test_mms = mms.transform(test)[0]
# show change in values
print('Training Data:')
for i in range(len(train)):
print(f'{train[i][0]} -> {round(train_mms[i][0], 2)}')
print(f'\nTesting Data:\n {test[0][0]} -> {round(test_mms[0], 2)}')
重要说明
如上面的例子中所述,在确定缩放操作的参数时,我们不应考虑测试数据。
任何缩放中使用的参数都应由训练数据单独确定。虽然测试数据也进行了转换,但它只会根据从训练数据中派生的参数进行缩放。
你应该使用哪个缩放方法?
尽管标准化和归一化具有相同的基本功能,但它们的使用方法不同。因此,它们的用例也不同。
标准化对于适合正态/高斯分布(normal/gaussian distribution)的数据是理想的。
它在处理具有异常值的数据时也很出色,因为它更能抵抗极端值。PCA 中就经常使用标准化,目的是在降低维度的同时最大化方差。
另一方面,当你不确定数据的分布时,归一化是更安全的选择。
总而言之,确定机器学习任务中的最佳特征缩放方法前,你需要对所用的数据有深入的了解。
结论

现在,你已经了解了如何利用标准化和归一化来缩放数据。尽管具有相似的功能,但它们采用不同的方法,这意味着它们的可用性会因情况而异。
了解这两种技术之间的差异非常重要,这样你才能够确定、并针对给定情况应用最佳的缩放方法。这能优化你的特征工程,并提高模型的整体性能。祝你在数据科学工作中好运!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
原文作者:Aashish Nair
翻译作者:Jiawei Tong
美工编辑:过儿
校对审稿:Jiawei Tong
原文链接:https://towardsdatascience.com/standardization-vs-normalization-dc81f23085e3





