
数据科学必备技能:一小时学会Random Forest随机森林
随机森林(Random Forest)是一种由决策树算法构建的监督机器学习算法,被数据科学家们用来解决回归和分类问题。 随机森林利用集成学习,结合了许多分类器,为复杂的问题提供解决方案。现在,随机森林算法已被应用于银行和电子商务等各个行业,用来预测行为和结果。
今天,我们就一起来学习随机森林(机器学习的一种方法),本文主要向你介绍随机森林的基本原理和一些应用。如果你想了解更多数据分析相关内容,可以阅读以下这些文章:
随机森林回归的一个局限
森林狼新晋数据分析师Nick Restifo谈篮球数据分析
作为数据科学家,如何提升你的沟通能力?
一篇清单,带你了解决策树Decision Tree术语
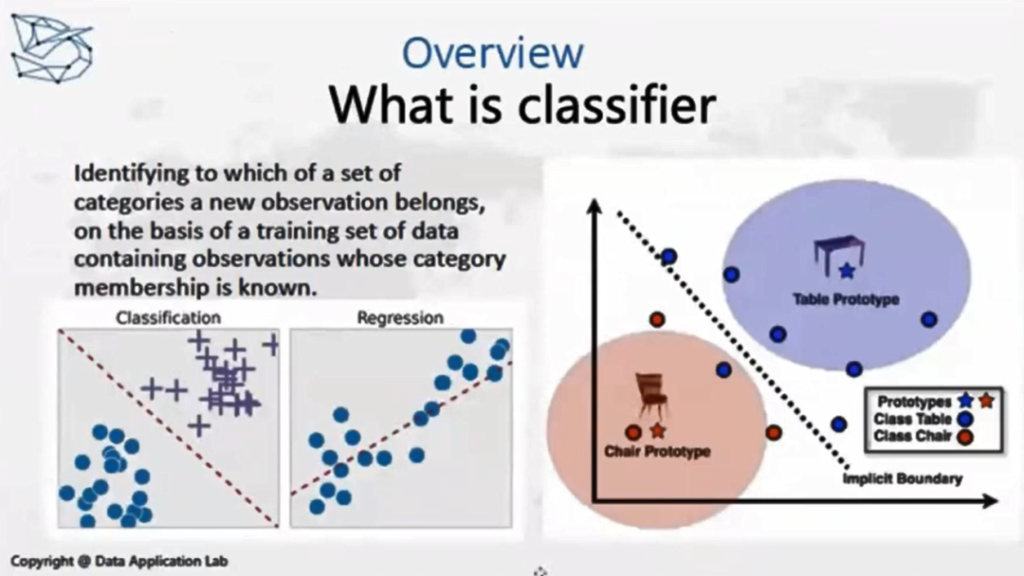
首先,我们来看看图片中的例子,这里的桌子和椅子被模型分开了。我们把这两个对象的属性,比如它有几条腿,它的高度和重量,以及有没有靠背等等这些特征拿出来,可以把目标分为两类(一类桌子,一类椅子)。再比如,我们想要判断一个孩子的学习水平等等问题,也可以用分类器。分类器算法解决的就是你要去预估的目标是一种分类的变量,跟它相对应的就是时间序列(数值)的变量。
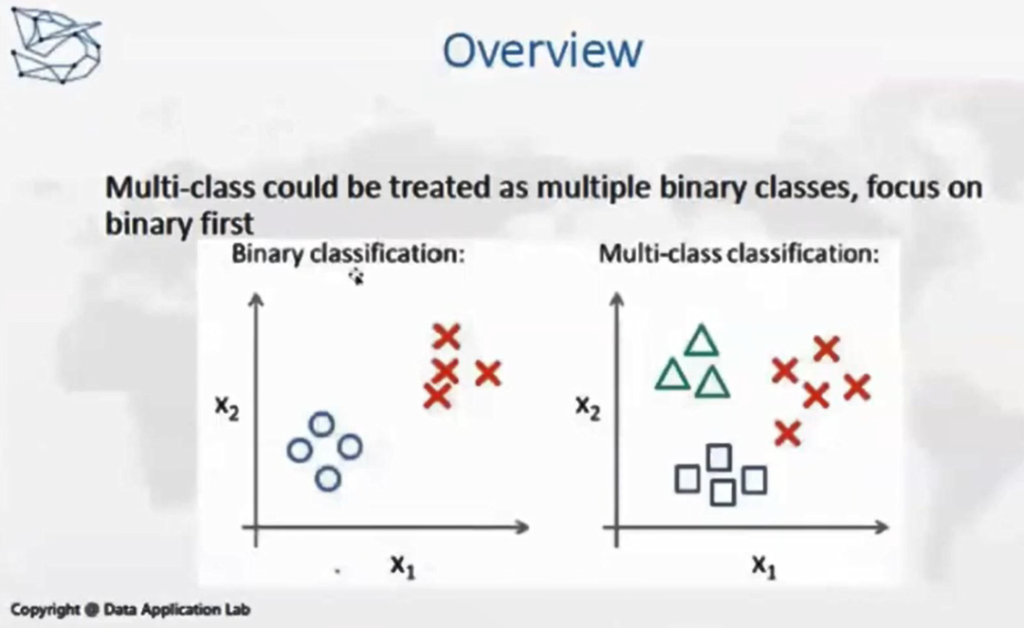
经典的分类器问题是0和1的区别,分类器的算法其实差别不大,但是评估他们的时候,会采用不同的方法。
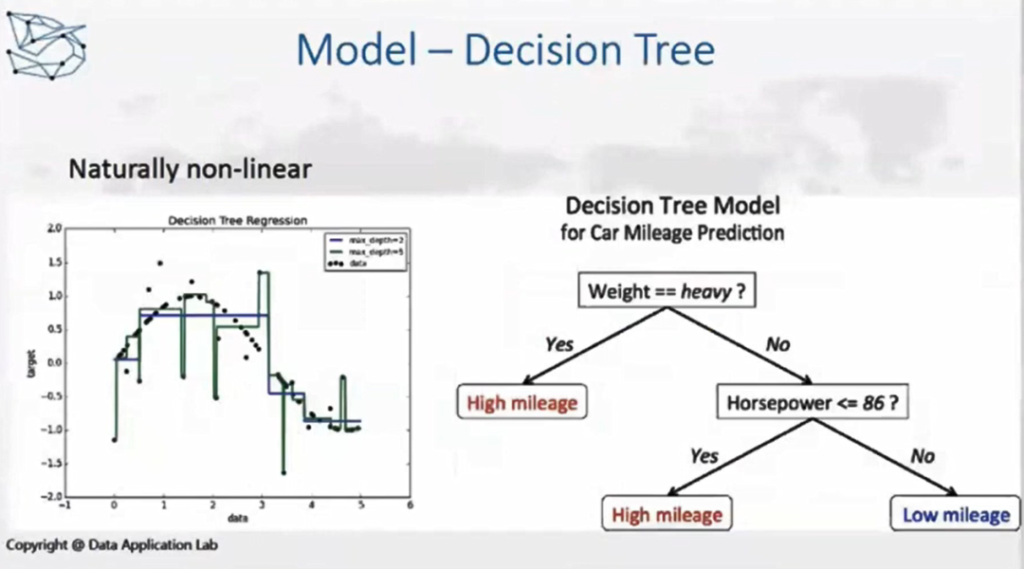
进入正题,让我们来看随机森林的方法,这里会用到决策树的算法,我们先来复习一下。数据应用学院以前的视频讲过决策树的内容,感兴趣的同学可以去YouTube学习。
决策树的结构是像树一样,在初始的节点找一个变量,我们要先判断它是Yes还是No,也可能是大于小于,这个判断是取决于一个公式。比如图片里的例子,我们需要判断一个车子的行驶里程,那要看它重量是多少,马力是多少,如果很重的话是不是有很高的里程数呢,根据一步一步的判断来得出结论,决策树也非常符合我们平常思维的一种模式。
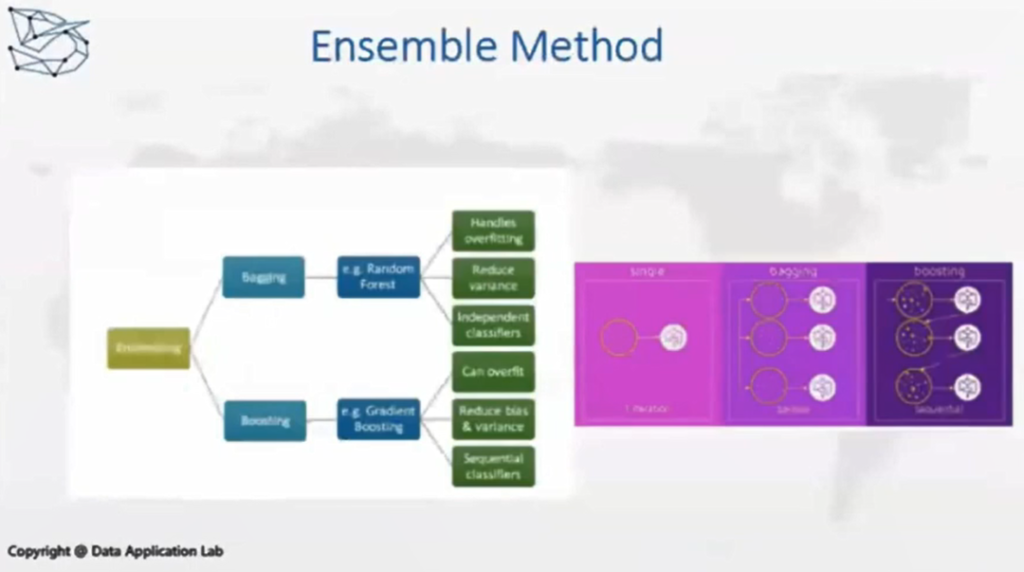

分类器有几个加强的算法,这种加强的算法我们称之为Ensemble Method。这个方法可以分作三类,今天我们主要讲Bagging这个算法,它是从训练集里随机选择一个子集;比如有一万条样本,随机在里面选一千条,用子集去训练模型,再在你的特征里面做一次Random的选择,只用部分的特征去训练模型,我们会得到一系列的基于前面随机选择而创建的模型,每一个模型都会有自己的输出,最后把每一个子模型预测出的结果进行综合的评判,这样会得出综合的结果,这种方法就叫bagging,而里面的一个经典的算法就是我们今天的讲的Random Forest。
这个算法的方法就是在原始的训练集里取出一个子集,来训练一棵“树”,Random Forest里面有很多决策树,决策树的训练集合是不同的;在选特征方面,它会从原有的特征里去选一个feature的子集,这样在进行判断的时候,相当于从整个特征集合中挑选出来一个子集,对这个子集进行训练。
这里可以选用信息增益的分叉决策。像前面讲到的,先挑选一个最容易能够将样本分开的特征,比如重量(weight)。挑选分割的特征也是在随机森林选一个子集中进行比较的,这两种方法就使随机森林产生很多决策树。
在树的训练过程中,随机森林不像决策树,它本身没有更多的剪枝过程,但是它又要保证训练的每棵树之间尽量不要有什么关联,将树组合一起并收集输出做一个总评定,而总评定又优于每棵树的评定的效果。随机森林就是建于决策树的算法之上,只不过是用了很多棵树进行综合评估。
这样做有什么好处呢?
- 第一,随机森林擅长处理高维度的数据,因为特征的子集是随机选择的。
- 第二,随机森林的表现或效果比一棵树要好。
- 第三,在数据量急剧增加进行分布式机器学习时,每棵树的训练是一个独立的过程,如果是一台机器进行并行化,如果是集群进行分布式训练,这时可以适当地处理大数据训练。
- 第四,因为是随机森林选择特征,特征之间的影响在学习过程就会降低。特别是在训练分类器时可能会面临不平衡数据,比如大部分病人出院之后就健康了,真正治疗不好返回来的是小数。
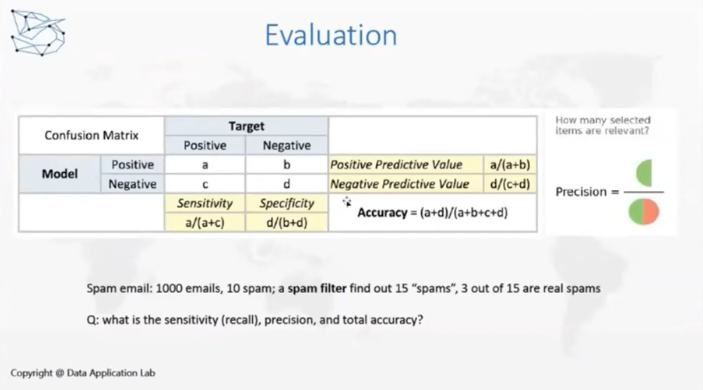
这里,我们也介绍一下评估的问题。在分类器中,最常见的一种评估方法就是Confusion Matrix。根据真实值和模型预测为0、1的二分类,进行排列组合后有4种情况, True Positive, True Negative, False Positive, False Negative。根据这四个值计算一下F1 score, Precision, Recall, Accuracy, 这些都是可以评估模型的指标,在此基础上,还可以考虑ROC。
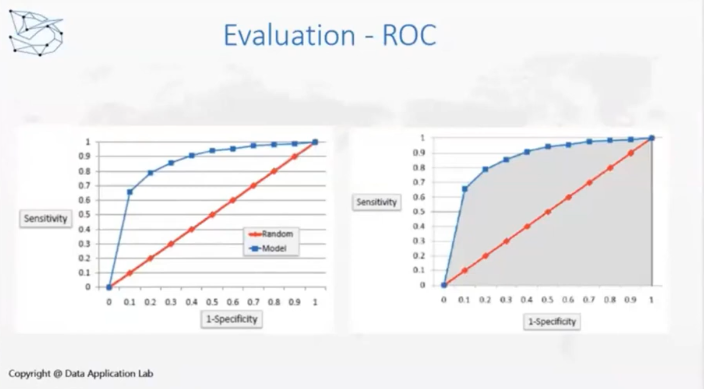
ROC是一种曲线,在分类器中可以输出1、0的概率,使用阈值决定模型预测值是0还是1,如果1的可能性大于50%,那么就是1,小于50%就是0。但是,在现在经济环境不好的情况下,在判断信用卡是否坏账时银行可能会把阈值降低,由原来的40%降为30%,如果成为坏账的情况大于30%就会采取风控的机制,比如限制额度。模型评估指标的有效性随着阈值变化而变化,ROC是在不同阈值情况下模型的表现效果,计算的就是右图灰色部分是AUC(Area Under Curve)。
那随机森林能否应用在回归问题中呢?决策树是可以在回归问题中使用的,随机森林本身也是可以的。
sklearn.ensemble.RandomForestRegressor是随机森林基于回归问题的算法,其中很重要的一个参数是criterion,使用了回归算法中常用的均方误差mse,mse就是评估节点,在节点分化时的目标。
这个就是将来评估节点,节点分化时所用的目标。如果你用它处理回归问题的话,首先用的library是不一样的,也要特别注意评估的标准。
接下来我们来看一下代码,这里分析的是一个Re-admission(重回医院)的问题。比如一个病人住院了,在出院之前可以根据住院记录包括年龄、性别、体重、住院原因等,基于这些数据来做一个模型预估一下他们是否会重新回到医院继续治疗。这就是这个问题基本的思路。
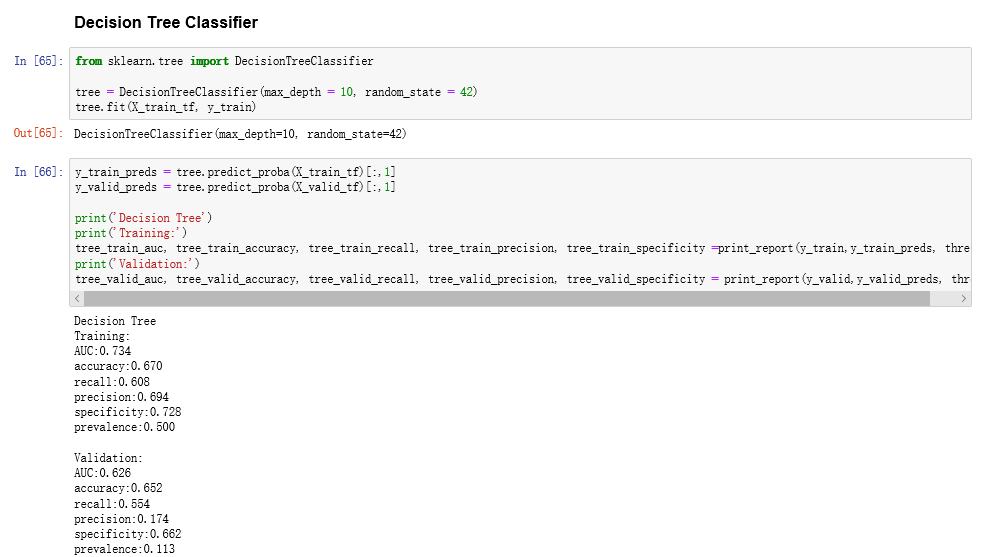
下面是决策树的一些内容,max_depth = 10, random_state = 42,给一个 random_state 的话,能让每次训练的结果不会变化很大,max_depth是树的深度,后面的一些参数就是原来自己带的一些值。最下面是决策树的评估指标。
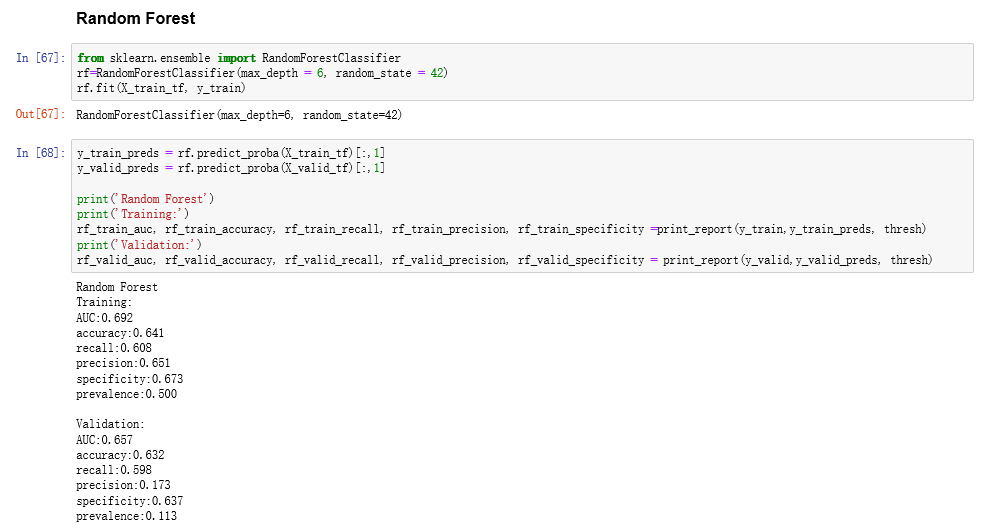
下面是Random Forest,它是放在ensemble包里面的一个算法,它本身就是一个ensemble的方法,特别还是一个Bagging的一个算法。可以看到,max_depth = 6,这里这样做是为了让过程更快一些,因为这个树的深度越大,计算量会更大,其他的参数基本上和前面树的参数是一样的。后面有一个print_report的一个函数,把训练的几个指标打印出来,包括AUC和accuracy。理论上来说,Random Forest比单个的树要好一点,就是创建很多树,把树的综合结果进行评估。
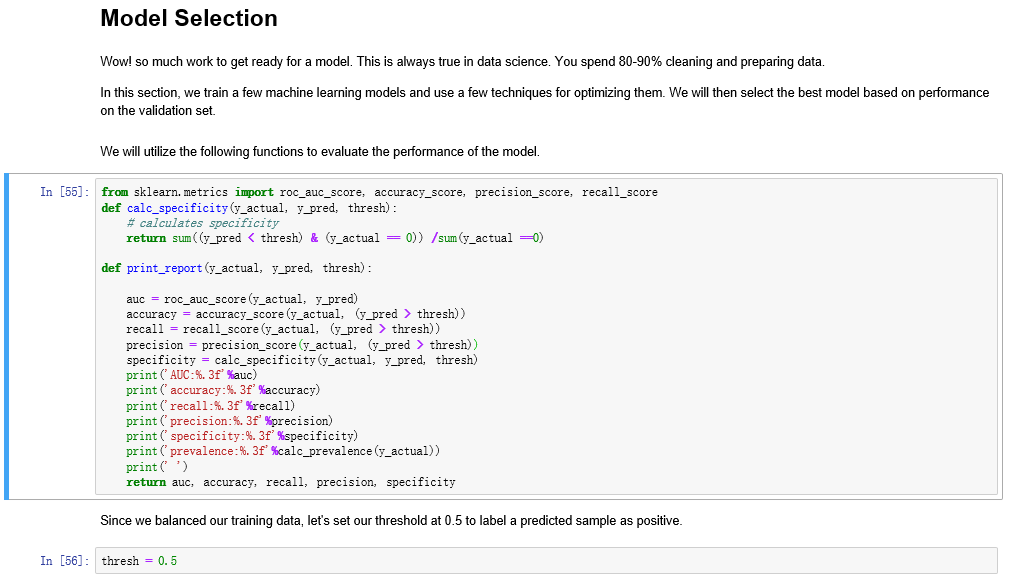
接下来,我们看一下print_report这个函数。print_report实际上就是算了一些基于confusion metrics之上的一些评估的函数。
本文从决策树开始,我们主要学习了Random Forest的算法是怎么工作的、以Bagging方法为代表的ensemble方法,也提到了boosting的算法,介绍了基于ensemble的bagging的方法如何理解Random Forest。
以上就是本文的全部内容,如果你想了解更多关于数据分析相关的内容,欢迎关注我们的公众号。祝你数据科学旅途顺利!你还可以订阅我们的YouTube频道,观看大量数据科学相关公开课:https://www.youtube.com/channel/UCa8NLpvi70mHVsW4J_x9OeQ;在LinkedIn上关注我们,扩展你的人际网络!https://www.linkedin.com/company/dataapplab/
Recap 作者:数据应用学院
美工编辑:过儿
校对审稿:佟佟
公开课回放链接:https://www.youtube.com/watch?v=tVUpw_zuFO0&t=448s





